
英伟达的AI Grid愿景:通信企业该入局吗?一份成本与价值的深度剖析





在年度GTC大会上,英伟达提出了名为“AI Grid”的宏大构想,计划推动全球电信网络向人工智能基础设施转型。
“AI Grid”是由相互连接的AI基础设施节点构成的网络,覆盖AI工厂、区域接入点、中心机房、移动交换中心及基站站点。这些节点配备全栈式AI基础设施,通过安全、高带宽、低延迟的网络连接,实现数据、模型、智能体和工作负载的无缝流转,让整个网格如同统一的分布式系统运作。
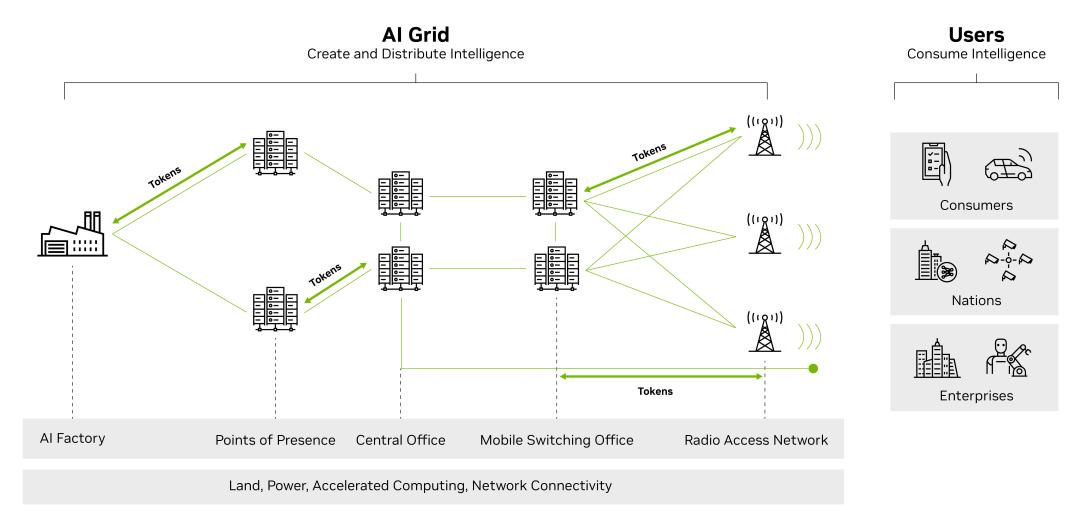
目前,T-Mobile US、Comcast、SoftBank等电信运营商正在探索“AI Grid”领域。英伟达强调,电信公司现有的铁塔、光纤和频谱等资产,使其天然适合承载分布式推理基础设施。但核心问题在于:若这一愿景代表未来趋势,电信运营商现在是否应投入大量资金建设分布式AI基础设施?
针对此问题,ABI Research近期发布分析报告,为电信公司算了一笔账。报告涵盖“AI Grid”落地中的边缘GPU部署、网络延迟限制、总体拥有成本,核心是厘清:英伟达的愿景如今是否可行,还是一场押注未来的昂贵赌博?
降低延迟是核心驱动力吗?
在网络近边缘或远边缘部署GPU,最常见的理由是延迟——实时执行和控制类应用对延迟要求严格,推理服务器越靠近用户,响应速度理论上越快。
然而,ABI的分析显示,这一论点对当前主流AI工作负载并不成立。对于生成式AI,首字延迟(TTFT,衡量从请求发起至接收第一个字节的时间)是关键指标,网络延迟并非主要影响因素。标准网络往返时间可能达100毫秒,但DNS解析、隧道建立、计算密集的预填充和解码阶段才是更大的延迟来源,这些环节不受推理服务器位置影响。以1000个token的中等提示词为例,预填充阶段约需160毫秒,解码阶段可能长达数秒。
这意味着,常规聊天机器人交互中,将推理服务器移近用户不会显著改善体验。token生成的计算延迟远超过网络传输节省的时间。Latitude首席执行官Guilherme Soubihe在接受RCR Wireless采访时指出:“绝大多数数据中心级GPU容量已被超大规模云厂商和前沿模型开发商用于大语言模型训练和微调,这些工作负载不会从边缘部署中获得有意义的收益,因为网络延迟基本无关紧要。”
不过情况更复杂。英伟达GTC大会演示显示,边缘部署后聊天机器人往返延迟从2000毫秒降至400毫秒。Personal AI首席执行官Suman Kanuganti质疑当前围绕单个请求的延迟讨论框架:“AI Grid并非优化单次调用,而是针对并发。”他引用基准测试:P99突发流量下,四节点AI Grid能将语音延迟保持在500毫秒内,吞吐量比基线提升80%,而集中式部署在相同负载下性能下降。即边缘的优势不在于缩短单个请求的毫秒数,而在于为海量并发会话维持稳定服务质量。对单个消费者查询,延迟优势不明显,但对处理大规模并发的运营商,考量结果不同。
物理AI才是让延迟成为架构刚需的领域。自动驾驶汽车、配送无人机、机器人、视频监控、智能眼镜及AR/VR,都大幅压缩了可接受的延迟窗口——云端推理无法满足需求。
ABI用实例说明:100毫秒延迟下,时速100公里的自动驾驶汽车相当于有2.8米“失明”距离。安全关键系统需要近乎实时执行,远端云数据中心推理不可行。这一原理适用于最后一公里配送机器人、实时视频分析等新兴应用。
但问题在于时机。这些物理AI应用大多距离规模化还有数年。爱立信美洲思想领导力负责人Peter Linder认为,部署理由需结合网络效率提升和未来收入潜力,而非仅依赖物理AI需求;Kanuganti则更激进,认为语音AI、视频智能和企业AI服务是现有用例。若自动驾驶汽车等真的接近大规模应用,现在就必须开始基建。
建设成本是否划算?
即使延迟论点和应用场景达成一致,分布式AI网格的财务挑战仍令人却步。ABI结论是,未来两到三年内,为降低标准延迟而大规模部署全国性边缘服务器在财务上不可行。基站部署尤其面临单位经济效益问题——每个基站服务用户群有限、覆盖范围窄,除密集高价值区域外,每个站点的回报都具挑战。
为用真实数据支撑讨论,ABI以美国T-Mobile为例模拟计算。T-Mobile US曾在GTC大会表示,“kinetic tokens”将为全球电信运营商带来巨大机遇,利用基础设施资产需AI-RAN系统及网络中部署GPU。假设T-Mobile US运营约13000个屋顶基站站点,开始配备AI-RAN服务器(采用英伟达ARC-1服务器,单价6万美元,每台为三个基站提供算力),到2035年完成屋顶站点GPU全覆盖——包括部署、冷却及其他辅助成本,累计总成本将达37亿美元。下图展示该部署场景的年度总体拥有成本:
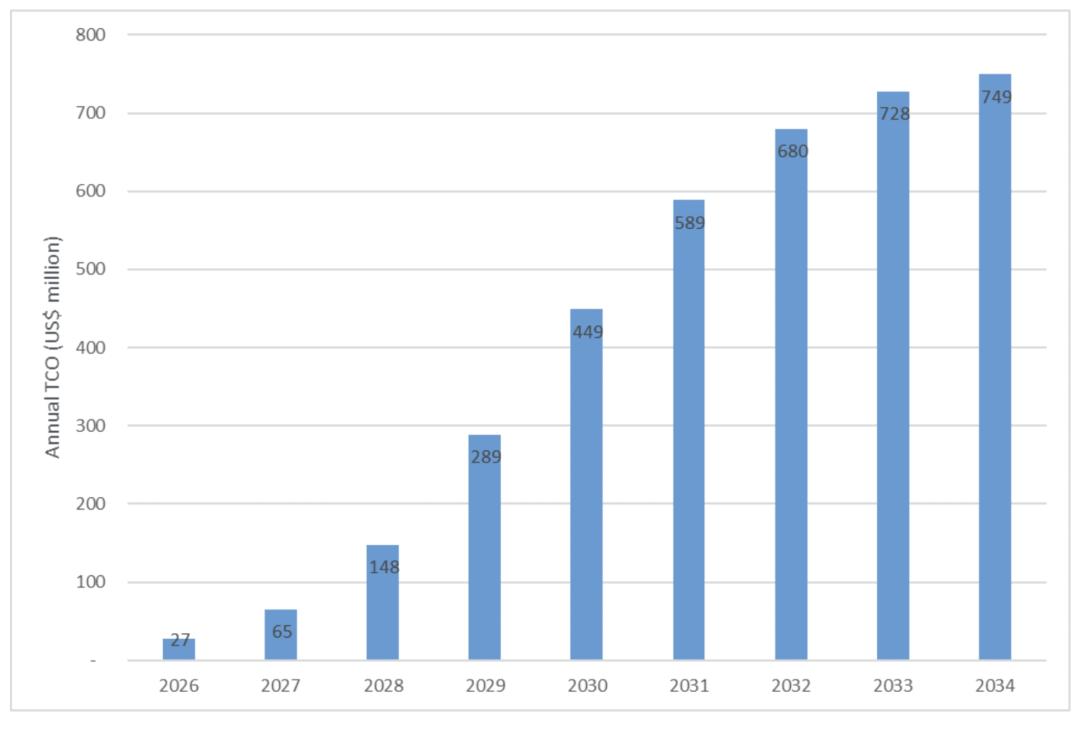
图:T-Mobile US在所有屋顶站点逐步部署GPU服务器的年度总体拥有成本
若收入相应增长,将投资分摊到九年,“AI Grid”投入更可控。37亿美元在英伟达体量下微不足道,但电信运营商及其投资者需要强有力的商业案例支撑支出——尤其是这笔投入规模相当于部署新一代无线网络。
基础设施现状加剧财务挑战,Kanuganti表示:“通信铁塔设计初衷并非容纳和冷却高密度计算设备”,这解释了先行者为何从具备冗余电源、冷却和物理安全措施的有线近边缘设施入手。Linder也强调:“无线电站点环境恶劣,因此使用专门设计的基于ASIC的计算,优化功耗、性能和成本,尽可能取消风扇。”
两种观点结论一致:远边缘建设取决于硬件能效提升、专为边缘AI设计的硬件形态,以及整合无线处理与AI推理的AI-RAN架构的出现。
鉴于这些限制,ABI预测AI推理初期部署将集中在核心网节点(通常一个国家内少于10个),之后随低延迟需求增长和经济性改善,逐步扩展到基站站点。视频监控、自动驾驶、最后一公里配送机器人、智能眼镜及AR/VR应用,使边缘推理成为架构必然要求。早期“AI Grid”部署主要为电信网络未来铺路,为6G所需的分布式计算打基础。
英伟达的“AI Grid”愿景值得投入吗?
按英伟达设想,“AI Grid”旨在跨计算位置无缝处理AI工作负载,优化成本、性能和用户体验。简言之,根据延迟、成本和策略目标决定模型运行位置及token流转方式。
赋能实时AI应用:对话助手、AR/VR、在线游戏和工业机器人等实时AI应用,为实现沉浸式体验需严格控制延迟。“AI Grid”通过将计算工作负载部署在靠近终端用户和设备的位置,实现此类高延迟敏感应用的大规模运行。
优化大规模Token成本:多模态生成和高级推理模型生成的Token数量是简单文本型LLM的100倍,增加网络数据量并推高云出口成本。“AI Grid”通过将Token密集型工作负载部署在具成本效益的分布式AI节点,减少数据出口和带宽消耗,同时不牺牲服务质量。
地理弹性架构提升弹性与投资回报:“AI Grid”可运行从AI应用到网络功能的各类工作负载,优化每个节点利用率,提高基础设施投资回报率并降低运营开销,优于单一用途系统。将多个分布式AI节点视为虚拟系统,能更智能扩展容量、应对需求高峰并减少单点故障。
区域合规与数据主权:企业可定义数据和模型在“AI Grid”上的存储和执行位置,使部署符合区域规则,同时利用全球规模协调能力。
基于这些收益,英伟达正构建电信公司成为新型AI网格关键节点的叙事。但需清醒认识到,这一框架对英伟达的好处远超其他方。设备销售、软件授权、生态绑定——无论“AI Grid”最终形态如何,英伟达都是最大赢家;而电信运营商的道路远不明朗。
率先行动的玩家短期内未必能看到实际回报,更多是在英伟达等公司所称的“AI超级周期”中抢占战略卡位。但这种卡位是否值得在收入来源未验证前投入数十亿美元资本支出,仍是悬而未决的问题~
参考资料:
ABI on AI infra | AI grid may be the next telecoms arms race (Analyst Angle)——RCRWireless
Nvidia’s AI grid and the telco dilemma——RCRWireless
What Is an AI Grid?——英伟达官网
英伟达的电信雄心:重塑2万亿美元网络产业——C114通信网
黄仁勋的物理AI野望:将5G网络转变为分布式AI计算机!——物联网智库
本文来自微信公众号 “物联网智库”(ID:iot101),作者:Sophia,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com