
2代LeCun世界模型,62小时机器人训练,开启物理推理新时期。









人工智能正在走向物理。——
Meta开源发布V-JEPA 2世界模型:一种AI模型,可以像人类一样了解物理世界。

Meta首席AI科学家图灵奖获得者Yann LeCun亲自出镜宣传,并称:
我们认为,世界模型将为机器人技术带来一个新的时期,使现实世界中的AI智能体能够帮助完成家务和体力任务,而无需大量的机器人训练数据。

那么什么是世界模型呢?
简而言之,就是AI模型,它能够对真实的物理世界做出反应。
这应该具备以下几种能力:
理解:世界模型应能理解世界的分析,包括物体、动作、运动等事物的识别视频。
预测:世界模型应该能够预测世界将如何进化,如果智能体付诸行动,世界将如何改变。
规划:基于预测能力,世界模型应该可以用来规划实现目标的行动序列。
V-JEPA 2(Meta Video Joint Embedding Predictive Architecture 2 )是首个基于视频训练世界模型(视频是世界信息丰富、易于获取的来源)。
可以用来提高动作预测和物理世界建模能力,零样本规划在新环境中进行和机器人控制。

V-JEPA 2一发布就引起了不少好评,甚至有网友表示:这是机器人领域的革命性突破!


规划控制模型可以通过62小时训练生成。
V-JEPA 2选择自我监督学习框架,利用100多万小时的互联网视频和图像数据进行预训练,证明纯视觉自我监督学习可以在不依赖语言监督的情况下达到顶级表现。
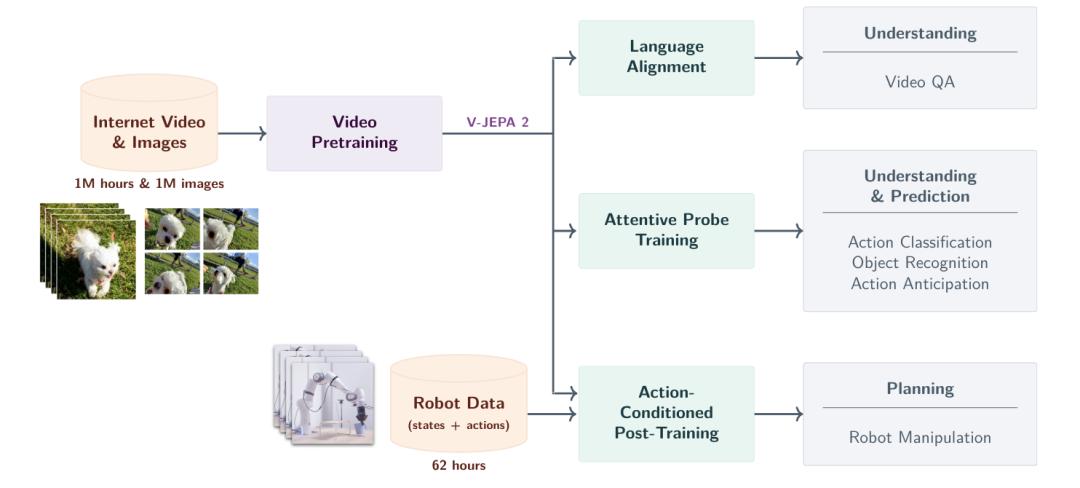
从大规模视频数据预训练到多元化下游任务,图中清晰地展示了如何进行全过程:
输入数据:使用100万小时网络视频和100万图片进行预训练。
训练过程:视频预训练采用视觉掩码除噪目标。
下游应用分为三类:
理解与预测:行为分类,物体识别,行为预测;
语言对齐:通过与LLM对齐来实现视频问答;
计划:通过后训练行动条件模型(V-JEPA 2-AC)实现机器人操作。
V-JEPA 2选择联合嵌入式预测架构结构(JEPA),主要包括两个部件:编码器和预测器。
编码器接收原始视频并输出能够捕捉到关于观察世界状态的语义信息的嵌入。
预测器接收视频嵌入和预测额外的前后文本,输出预测嵌入。
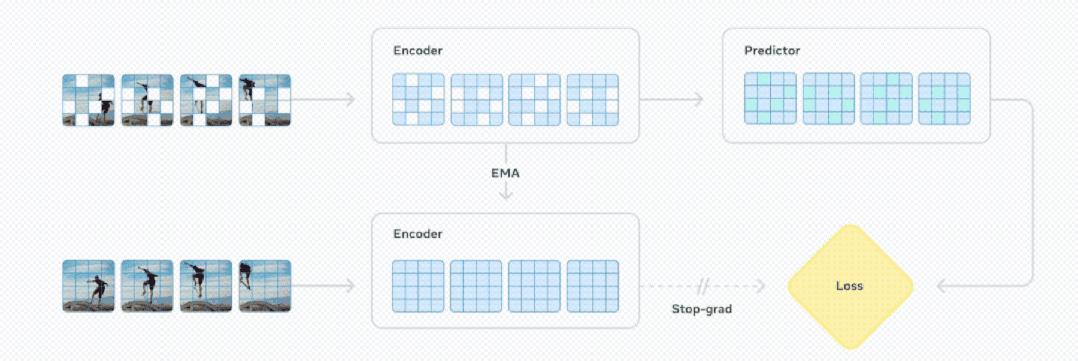
研究小组通过视频进行自我监督学习来训练V-JEPA 这样就可以在不需要额外人工标注的情况下进行视频训练。
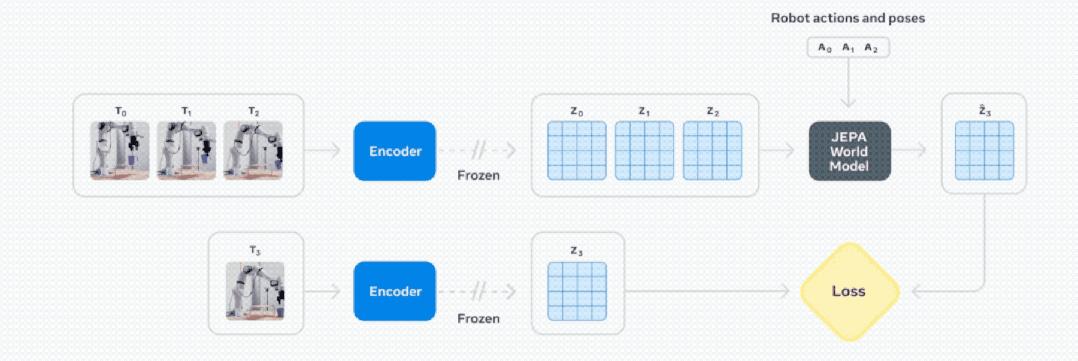
V-JEPA 2练习涉及两个阶段:第一,没有动作预训练(左边是下图),然后是额外的动作条件训练(下图右边)。
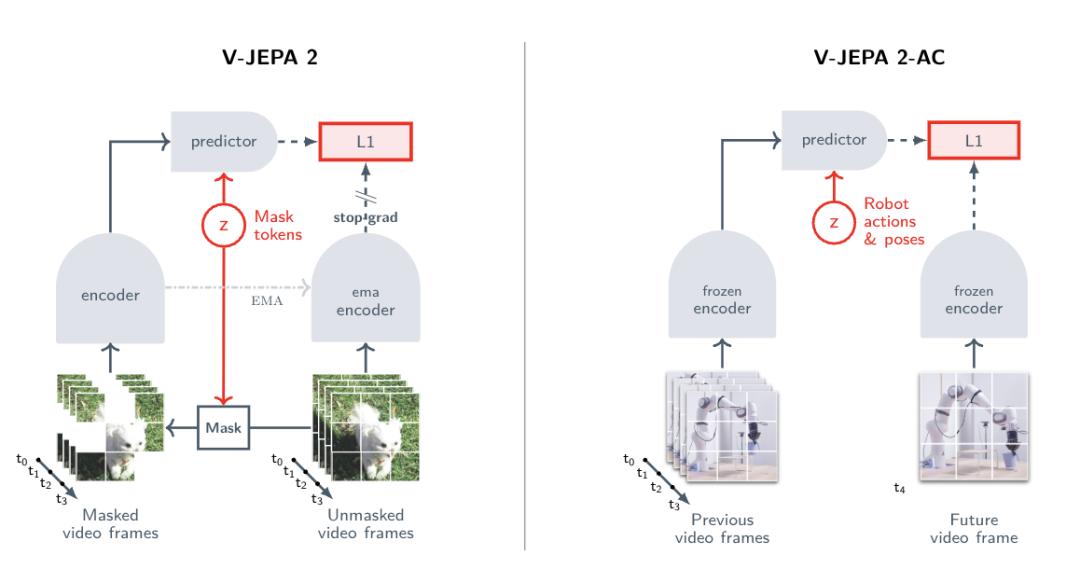
训练有素之后,V-JEPA 在运动理解方面取得了优异的性能(在Something)-Something 达到77.3的v2 top-1精确度),并且在人类动作预测方面达到了目前的最佳水平(Epic-Kitchens-recalll100达到39.7-at-5),超越了以往的特定任务模型。
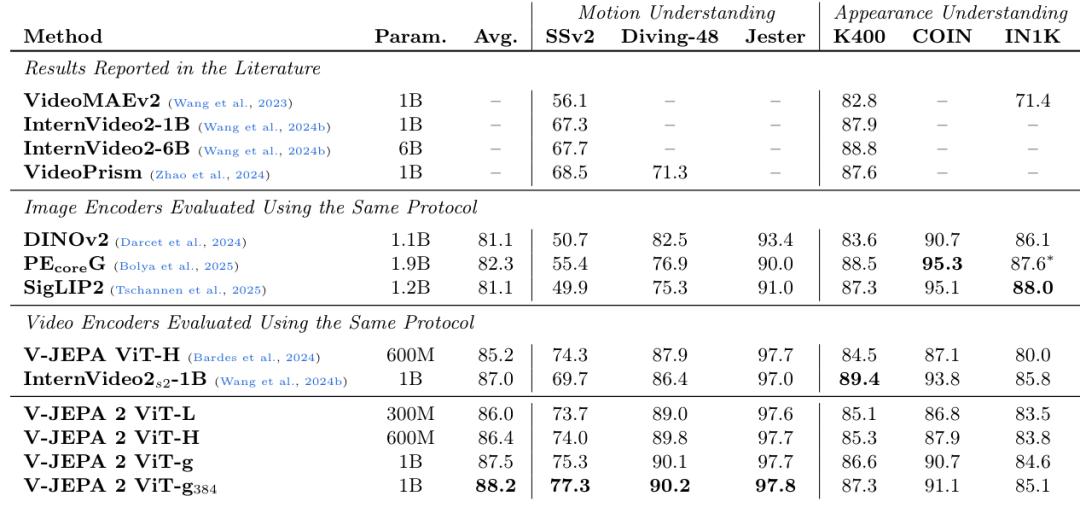
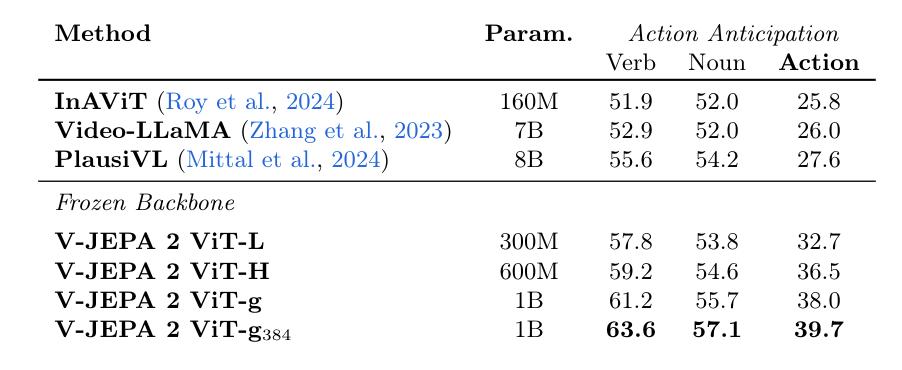
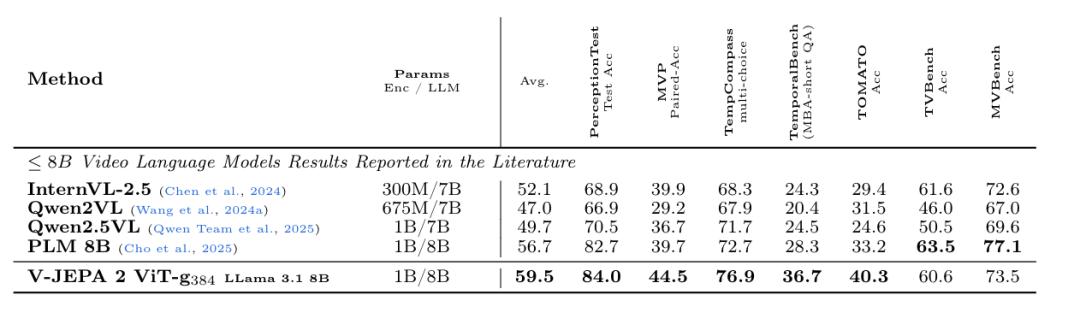
另外,将V-JEPA 2与大型语言模型对齐后,团队在8B参数规模下的多个视频问答任务中显示出当前最佳性能(例如,在PerceptionTest上达到84.0,在TempCompass上达到76.9)。
对于短期任务,例如捡起或放置物体,团队以图像的形式指定目标。
使用V-JEPA 2编码器可以嵌入当前状态和目标状态。
从目前的状态来看,机器人可以通过使用预测器来想象采用一系列替代动作的后果,并根据其接近目标的速度对替代动作进行评分。
每一步,机器人都会通过模型预测控制重新规划并实施下一步对该目标进行最高评分。
对于更长时间的任务,例如,捡起物体并将其放置在正确的位置,指定一系列机器人试图按顺序实现的视觉子目标,类似于人类所看到的视觉模仿学习。
通过这些视觉子目标,V-JEPA 2在新的、未见过的环境中捡起和放置新物体时,通过率达到65%–80%。
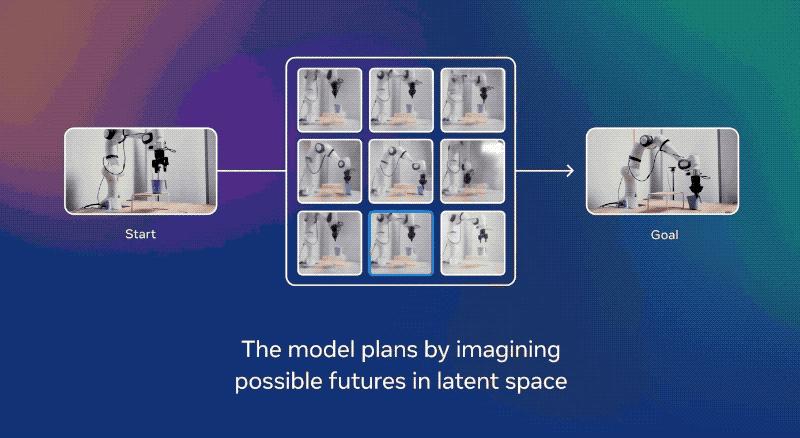
理解新的物理标准
Meta还发布了三个新的基准测试,用于评估目前的模型了解和推理视频中物理世界的能力。
虽然人类在三个基准测试中表现出色(准确率85%)–95%),但是人类的表现和包括V-JEPA 2顶级模型之间存在明显的差距,这表明模型需要改进的重要方向。
IntPhys 2在早期IntPhys基准测试的基础上,专门设计来衡量模型在物理上可能和不可能的场景之间的区分,并进行构建和扩展。
该团队通过一个游戏引擎生成视频对,其中两个视频在某一点之前完全一致,然后其中一个视频发生了物理破坏。
模型必须确定哪个视频发生了物理破坏。
虽然在各种情况和环境下,人类在这项任务中几乎达到了完美的准确性,但目前的视频模型正处于或接近随机水平。

Minimal Video Pairs (MVPBench)视频语言模型的物理理解能力通过多选题测量。
它旨在缓解视频语言模型中常见的捷径解决方案,例如依靠表面视觉或文本线索和偏见。
MVPBench中的每一个例子都有一个最小的变化:视觉上相似的视频,以及相同的问题,但是答案是相反的。
为获得一个例子的分数,模型必须正确回答其最小变化对。

CausalVQA测量视频语言模型回答与物理逻辑有关的问题的能力。
这个标准旨在理解物理世界视频中的逻辑关系,包括反事实(如果...会发生什么)、期望(下一步可能会发生什么)和计划(下一步应该采取什么行动来实现目标)有关。
虽然大型多模态模型在回答视频中“发生了什么”的问题方面的能力越来越强,但在回答“可能发生了什么”和“接下来可能发生了什么”的问题时,仍然存在困难。
这表明,在给定行动和事件空间的情况下,预测物理世界可能如何进化,与人类表现存在巨大差距。
One More Thing
Meta还展示了企业在通往高级机器智能的道路上的下一步计划。
目前,V-JEPA 二是只能在单一的时间尺度上学习和预测。
但是,许多任务需要跨越多个时间尺度来规划。
所以一个重要的方向就是发展致力于训练,能够在多个时间和空间尺度上学习、推理和布局。分层次JEPA模型。
另外一个重要方向是多模态这些模型可以使用多种感官(包括视觉、音频和触觉)来预测JEPA模型。
项目地址:GitHub:https://github.com/facebookresearch/vjepa2Hugging Face:https://huggingface.co/collections/facebook/v-jepa-2-6841bad8413014e185b497
参考链接:
[1]https://ai.meta.com/blog/v-jepa-2-world-model-benchmarks/
[2]https://x.com/AIatMeta/status/1932808881627148450
[3]https://ai.meta.com/research/publications/v-jepa-2-self-supervised-video-models-enable-understanding-prediction-and-planning/
本文来自微信微信官方账号“量子位”,作者:关注前沿技术,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com