
内存墙困境:AI加速为何不能仅靠堆砌计算单元?





本文来自微信公众号: 歪睿老哥 ,作者:歪睿老哥
一提到AI加速,不少人首先想到的就是增加算力、堆砌更多浮点计算单元。
但这种思路其实存在误区。
当前AI加速的瓶颈并非计算能力本身,而是数据搬运、通信效率以及不规则算子的处理问题。即便峰值算力再高,如果这些环节跟不上,也难以发挥作用。
以大语言模型推理为例,每生成一个新token,都需要对已存储的KV缓存进行读写操作。这一过程对计算的需求并不高,真正的短板在于内存带宽——若带宽不足,即便计算单元数量再多,也只能等待数据从内存缓慢传输,大部分时间处于闲置状态。
再看当下流行的混合专家模型(MoE),每个token仅由部分专家处理,这种动态路由的不规则计算方式,传统通用硬件难以高效支持。
因此,要运行最新的顶尖模型,无论是训练还是推理,若缺乏专门的硬件加速优化,要么成本高得惊人,要么延迟严重到无法实际应用,根本无法落地。
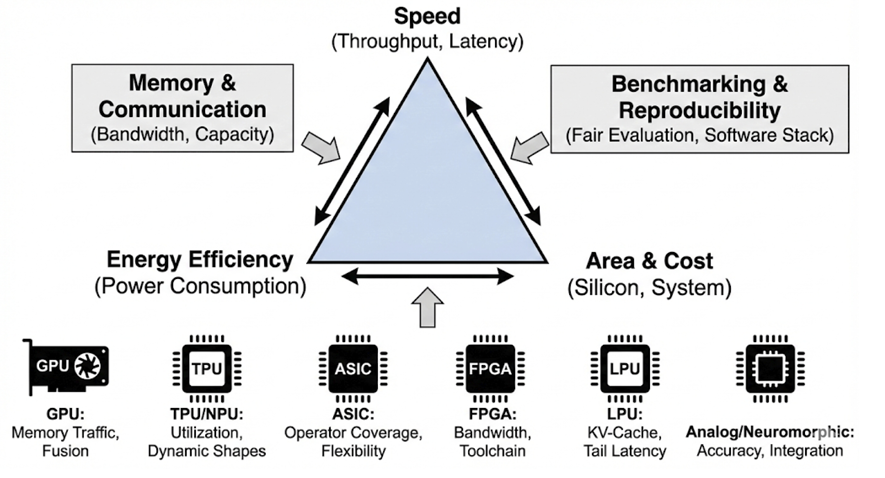
目前,硬件加速领域已全面铺开,从配备张量核心的通用GPU,到谷歌TPU、手机NPU等专用张量处理器,还有FPGA可重构设计、ASIC专用推理芯片。近期甚至出现了专为大语言模型推理打造的LPU,存算一体、神经形态计算等新技术也在不断发展。
这些技术的出现,本质上是刚需推动的结果——没有它们的加速,如今的AI技术很难从实验室走向大众的手机等终端设备。
无论是训练还是推理,大模型早已将压力转移到内存和通信层面,单纯堆砌计算单元无法解决问题。下面我们从不同维度拆解瓶颈所在。
首先是功耗与能量瓶颈。
你知道吗?
移动一个字节数据消耗的能量,比完成一次浮点计算要高出好几个数量级。
当前绝大多数场景中,芯片的功耗大部分都消耗在数据搬运上,而非计算过程。
数据移动的能耗明显高于算术运算能耗。
从不同硬件来看:
GPU的功耗基本与内存流量绑定,若不进行算子融合,大部分能量会浪费在寄存器、缓存与显存之间的数据来回搬运上;
TPU/Edge NPU依靠专用数据流节省能量,但一旦工作负载不符合设计预期,需要频繁访问片外存储,能量效率会立刻下降;
ASIC和FPGA虽能通过流水线和片上缓存减少数据搬运,但只要模型出现新算子需要回退到CPU,或片上存储无法容纳数据导致频繁交换,能量优势就会消失;
即便是专门针对大模型推理的LPU,以及存算一体、神经形态等新架构,也绕不开KV缓存搬运的能量成本问题——本质仍是数据移动的挑战。
讲完功耗,再看大家关注的延迟与吞吐量问题。
很多厂商宣传峰值TOPS,但实际运行时往往达不到,原因何在?
因为吞吐量和延迟并非仅靠算力堆砌就能提升,瓶颈始终在数据端。
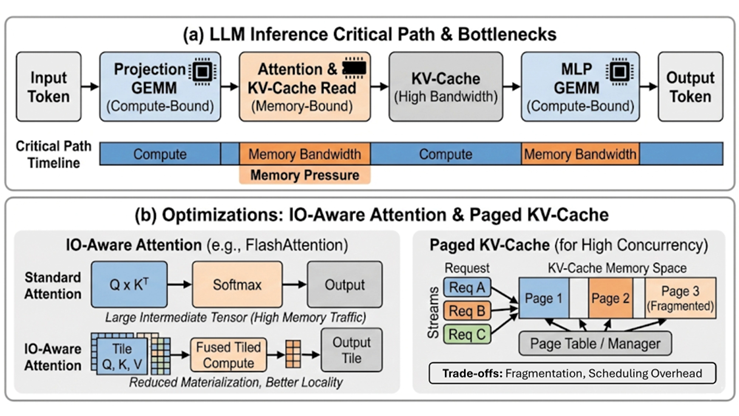
LLM推理的预填和解码阶段瓶颈对比,解码阶段明显受内存带宽限制
以大语言模型推理为例:整个过程分为预填和解码两个阶段,预填阶段计算密集,解码阶段则完全受带宽制约。
每生成一个新token,都要读写整个KV缓存,数据未传输完成,计算单元再强也只能等待。
不同硬件的痛点各异:
GPU通过批处理提升吞吐量,但批次越大排队时间越长,尾延迟难以控制;
TPU/NPU对固定形状的密集算子处理速度快,但形状变化、序列变长时,编译调度跟不上,延迟会大幅上升;
ASIC依靠固定算子实现低延迟,但若遇到不支持的新算子,延迟会直接崩溃;
FPGA可实现确定性低延迟,但路由拥堵和片上内存不足的问题,会导致序列稍长时吞吐量下降;
专门用于LLM推理的LPU,即便将调度集成到硬件中,也无法摆脱一个规律:上下文越长,需要搬运的KV缓存越多,延迟下限由内存带宽决定,架构优化也无法突破这一物理限制。
接下来是面积与成本瓶颈。
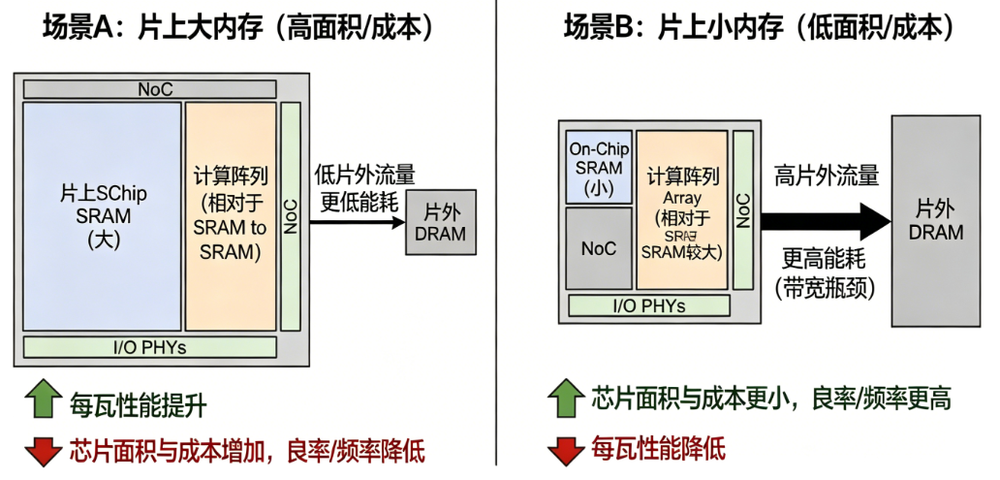
加速器设计中的面积、成本与性能权衡
硅片面积有限,将面积分配给计算单元还是内存,是永恒的权衡问题。
如今越来越多的设计发现,将面积分配给内存和互联,比分配给更多计算单元的回报更高。
例如,在大模型推理中,即便拥有满片的计算单元,要容纳70B模型的权重和KV缓存,也需购买更多卡,即使每张卡的计算利用率仅30%,这笔“容量税”也不得不交。
采用低延迟SRAM架构的LPU,延迟表现出色,但存储大模型权重需要堆砌大量芯片,成本极高,非普通用户所能承受。
新架构也面临类似问题:存算一体需要大量ADC/DAC周边电路,这些电路的面积甚至超过计算交叉阵;
神经形态芯片将大量面积用于存储和路由,处理密集模型时的面积效率远低于传统脉动阵列,成本难以收回。
然后是核心的内存与通信瓶颈。
当前端到端性能基本受内存容量、带宽和通信限制,峰值算力只是一个理论数字。
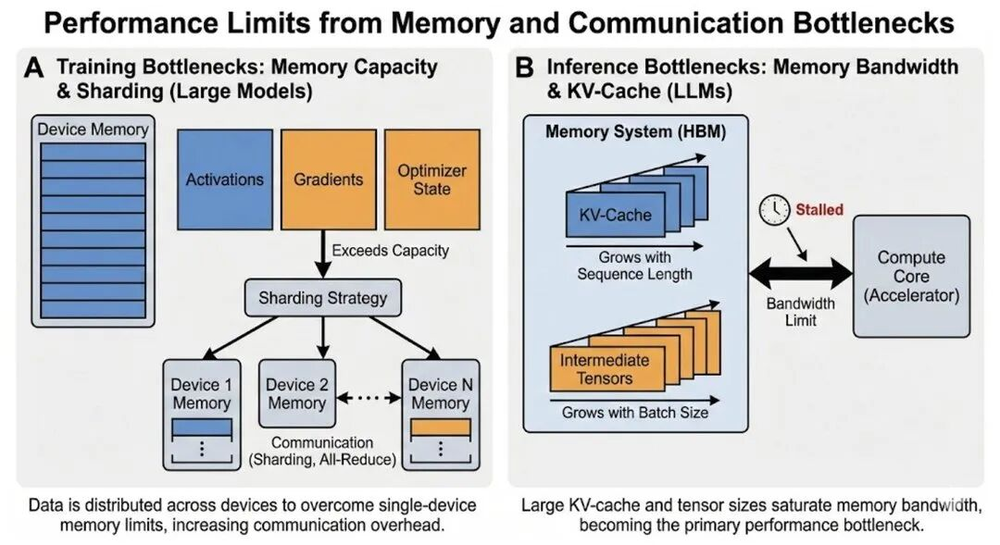
大模型训练和推理中的内存与通信瓶颈,有限的HBM带宽和互联延迟是主要限制因素
训练时需要存储激活值、梯度和优化器状态,大模型的这些数据会迅速占满显存;
推理时LLM的KV缓存会随上下文长度和并发数线性增长,即便计算能力充足,带宽不足仍会导致运行卡顿。
分布式训练中,多卡间的all-reduce操作,通信时间常超过计算时间,互联带宽不足时,增加再多卡也无法提升效率。
不同硬件的具体情况也有差异:
GPU算力增长速度远快于内存带宽,“内存墙”问题日益突出;
TPU编译器若工作集略超片上SRAM容量,性能会急剧下降,比GPU的降级速度更快;
ASIC依靠固定数据流节省带宽,但遇到Attention这类不规则访问时,性能会大幅下降;
LPU进行多芯片互联时,需要纳秒级同步,普通PCIe无法满足,必须采用专用互联,成本随之上升;
存算一体虽解决了片外数据搬运问题,但片上网络成为新瓶颈,交叉阵计算完成后数据无法及时传出,计算单元仍会闲置。
最后是资源利用率问题,这一点常被忽视,但对实际体验影响很大。
不规则的工作负载,如非结构化稀疏、动态形状、MoE路由等,会导致负载不均衡,即便峰值算力很高,实际利用率可能不足一半。
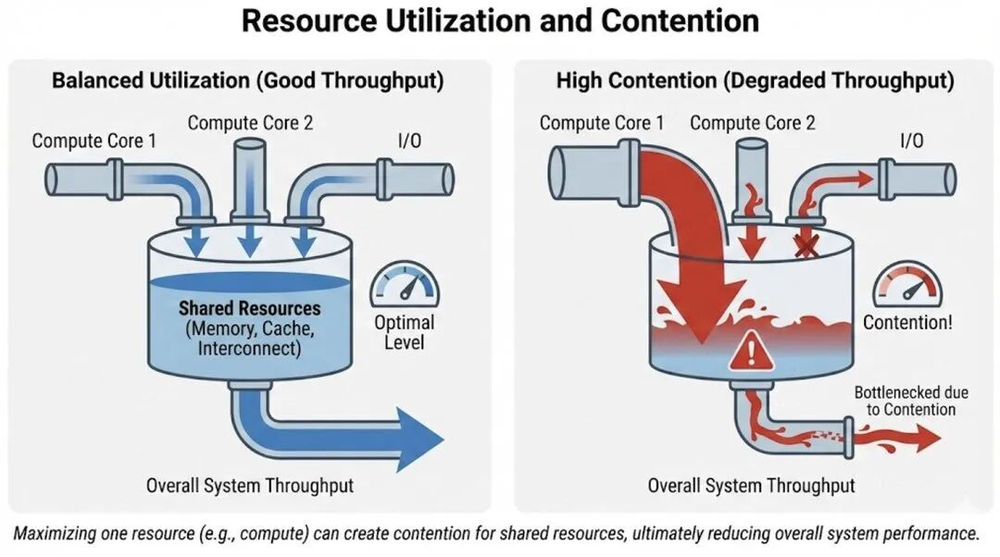
不规则工作负载导致的负载不均衡与计算单元利用率下降示意图
例如,小批量推理时,许多ASIC为追求峰值TOPS设计了较宽的向量,当batch=1时,利用率甚至不足十分之一;
TPU的脉动阵列处理matmul速度极快,但处理LayerNorm、Softmax等小算子时,向量单元不足,大脉动阵列只能闲置;
大模型的预填和解码阶段,预填时计算单元满负荷运行,解码阶段90%的时间都在等待数据,利用率难以提升。即便是专门的LPU,也需通过特殊调度硬件才能提高利用率。
最后谈谈基准测试的误区,很多厂商宣传的成绩是在最优场景下测得的,换为实际负载后表现会大打折扣。
性能结果对软件栈、精度、模型大小、batch大小、序列长度等因素非常敏感,同一硬件用不同方法测试,结果可能相差数倍。
例如,许多存算一体的论文仅测试计算单元的峰值,未计入ADC转换和非matmul算子的开销;不少NPU只宣传峰值TOPS,却不提有多少算子不支持需回退到CPU;
测试大模型时只说每秒处理的tokens数,却不说明并发量、尾延迟和上下文长度,这些都是不严谨的做法。
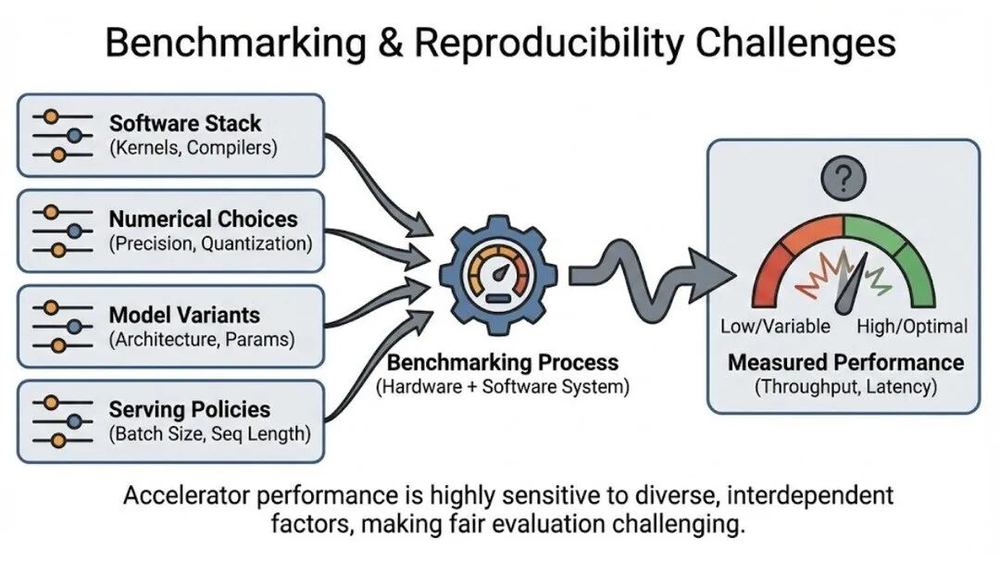
神经网络加速器基准测试的挑战,结果对软件版本、编译选项、测量方法高度敏感
总结来说:
无论采用何种架构、应用于何种场景,当前神经网络加速的核心矛盾都不是“算力不足”,而是“数据传输不畅”。
所有有效的优化,本质都是减少不必要的数据移动,让数据尽量靠近计算单元。这一逻辑从上个世纪“内存墙”概念提出,到如今AI大爆发,始终未变。
参考:Hardware Acceleration for Neural Networks:A Comprehensive Survey
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com