
DeepSeek V4正式发布:打破闭源垄断,携手华为算力,百万上下文成标配





DeepSeek-V4终于揭开面纱!预览版已正式上线并同步开源,一举推出两大版本,旨在打破顶级闭源模型的垄断地位,同时明确了与华为芯片的合作方向。其Agent能力可与Opus 4.6相媲美,百万上下文更是成为了标配。
刚刚,DeepSeek-V4来了!
预览版正式上线并同步开源。
一共两个版本:
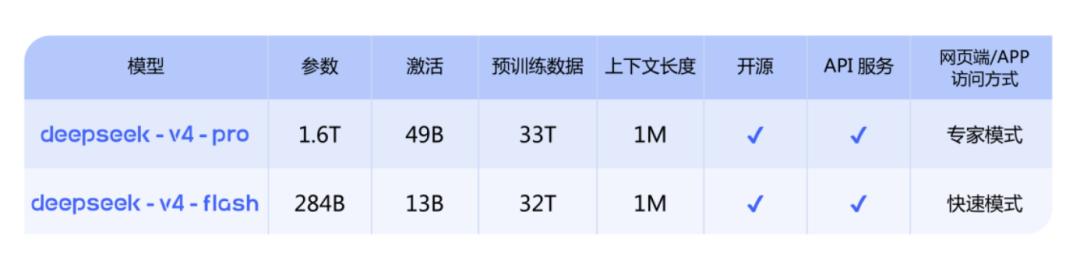
DeepSeek-V4-Pro:对标顶级闭源模型,1.6T参数,49B激活参数,上下文长度达1M;
DeepSeek-V4-Flash:更轻量高效的经济版本,284B参数,13B激活参数,上下文长度同样为1M。
官方表示:在Agent能力、世界知识储备以及推理性能方面,均实现了国内与开源领域的领先水平。
并且:
目前DeepSeek-V4已成为公司内部员工使用的Agentic Coding模型,根据评测反馈,其使用体验优于Sonnet 4.5,交付质量接近Opus 4.6的非思考模式,但与Opus 4.6的思考模型仍存在一定差距。
目前官网和APP均已上线该模型,API服务也同步完成更新。
大家关注的国产算力方面,重点信息是:下半年将支持华为算力。

顶配与性价比兼具,双版本同步推出
此次V4版本一次性发布了两个不同定位的模型。
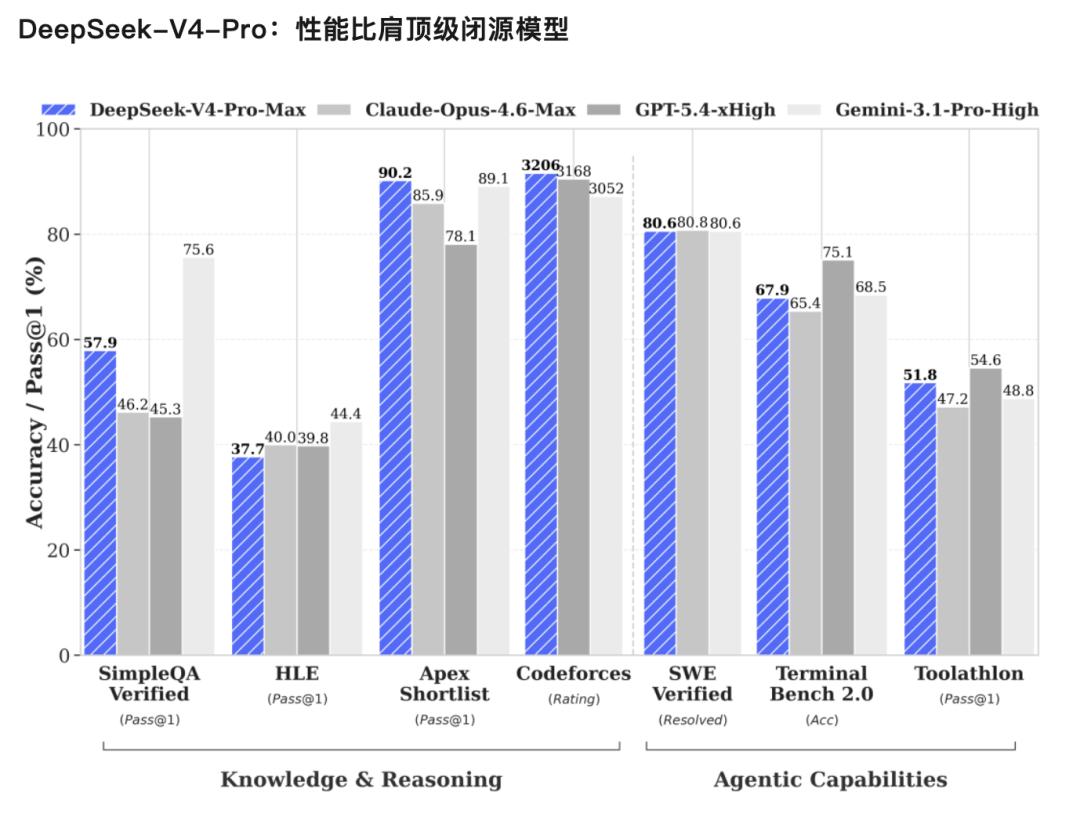
V4-Pro,性能可与顶级闭源模型比肩。
官方给出的核心优势有三点:
Agent能力显著提升:在Agentic能力的Coding评测中,V4-Pro已达到当前开源模型的最佳水平,在其他Agent相关评测中也表现出色。内部测评显示,在Agent Coding模式下,V4的使用体验优于Sonnet 4.5,交付质量接近Opus 4.6的非思考模式,但与Opus 4.6的思考模型仍有一定差距。
丰富的世界知识储备:DeepSeek-V4-Pro在世界知识测评中,大幅领先其他开源模型,仅略逊于顶尖闭源模型Gemini-Pro-3.1。
世界顶级的推理性能:在数学、STEM以及竞赛型代码等测评中,DeepSeek-V4-Pro超越了当前所有已公开评测的开源模型,取得了可与世界顶级闭源模型相媲美的优异成绩。
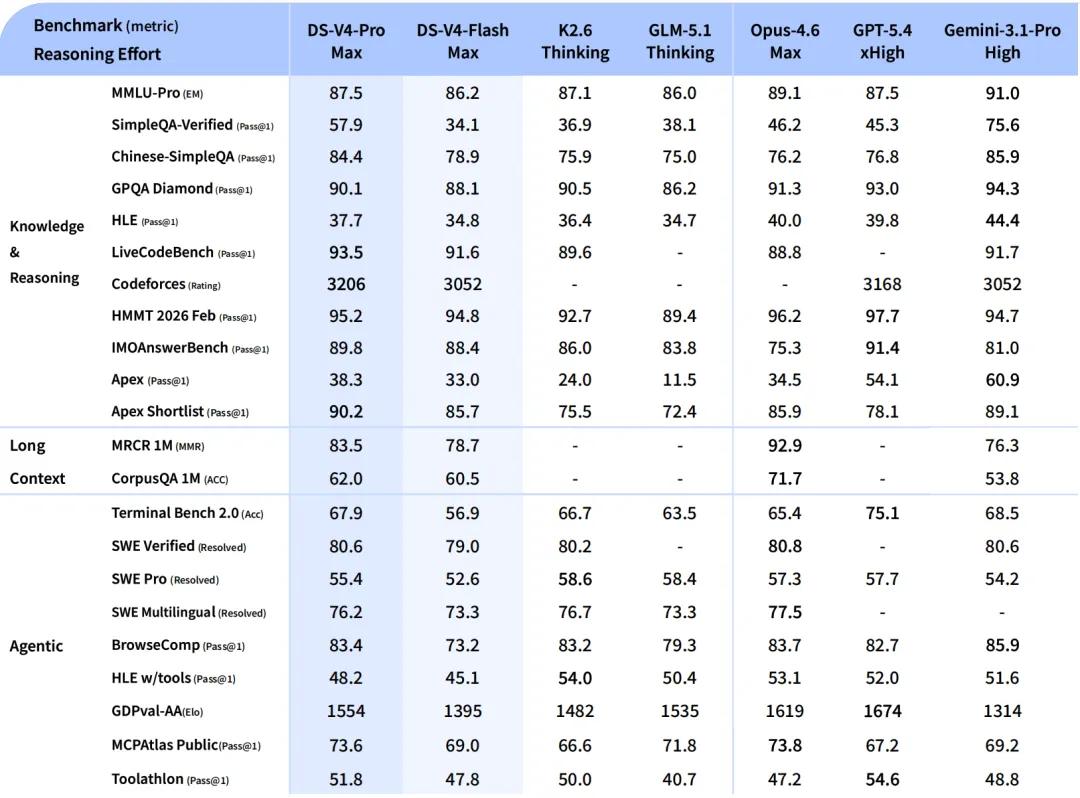
V4-Flash,是更轻量、更快速的经济版本。其推理能力接近Pro版本,世界知识储备稍逊,但参数和激活规模更小,API调用成本更低。
在Agent任务方面,DeepSeek-V4-Flash在简单任务上与DeepSeek-V4-Pro不相上下,但在高难度任务上仍存在差距。
在洗车测试中,V4也顺利通过。

不过在“绝望的父亲”这一经典生物学场景测试中,DeepSeek-V4未能直接抓住红绿色盲的关键要点(依据遗传学规律,若女性为红绿色盲,其生物学父亲必然也是红绿色盲)。

百万上下文成为标配
值得关注的是,从即日起,1M上下文将成为DeepSeek所有官方服务的标配。
一年前,1M上下文还是Gemini独有的核心优势;其他闭源模型的上下文长度要么是128K,要么是200K;开源领域几乎没有模型能达到这一量级。
DeepSeek直接将百万上下文从“高端功能”转变为基础服务。
而且该模型是开源的。他们如何实现这一点?发布稿中给出了答案——
V4开创了全新的注意力机制,在token维度进行压缩,并结合DSA稀疏注意力技术。与传统方法相比,大幅降低了对计算资源和显存的需求。
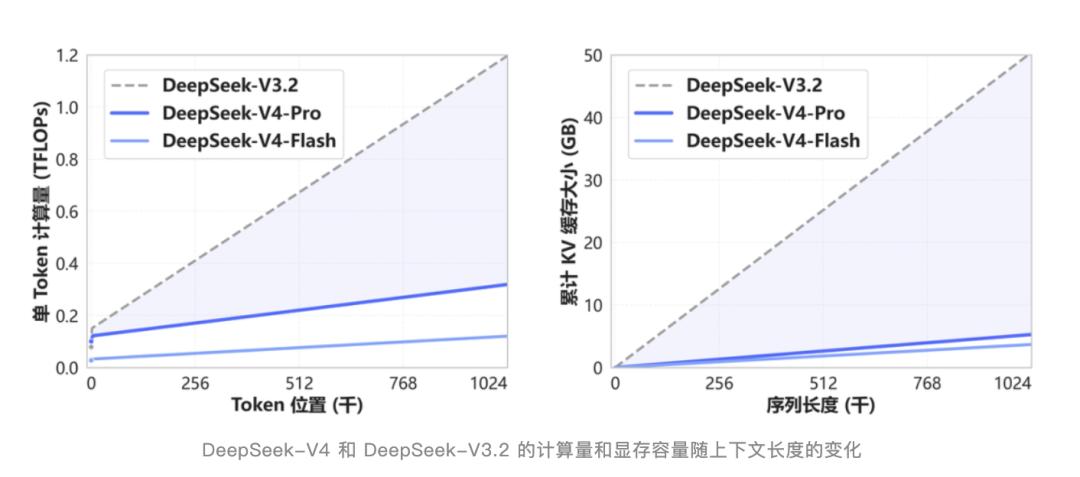
DSA并非新名词。半年前的V3.2-Exp更新中首次引入该技术,当时外界关注度不高,因为其跑分与V3.1-Terminus几乎一致,看起来像是一次无太多亮点的中间版本更新。
如今回顾,那其实是V4版本的技术基础。
Agent能力专项优化
在Agent方面,V4针对Claude Code、OpenClaw、OpenCode、CodeBuddy等主流Agent产品进行了适配与优化,代码任务和文档生成任务的性能均有提升。
发布稿中还附带了一张V4-Pro在某Agent框架下生成的PPT内页示例。

API价格
API服务方面,V4-Pro和V4-Flash同步上线,支持OpenAI ChatCompletions接口和Anthropic接口两套标准。
base_url保持不变,只需将model参数修改为deepseek-v4-pro或deepseek-v4-flash即可调用。
两个版本的最大上下文长度均为1M,且同时支持非思考模式和思考模式。在思考模式下,可通过reasoning_effort参数调整强度,分为high和max两档。官方建议在复杂Agent场景中直接使用max档。
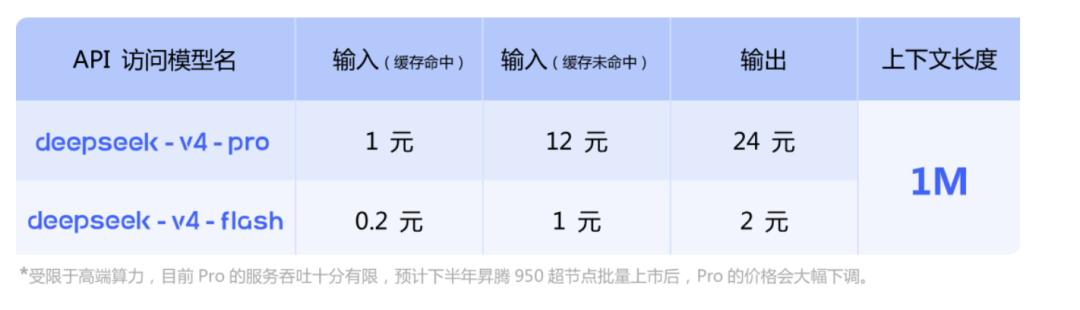
这里有一个重点信息——下半年将支持华为算力。
此外,旧模型名称将被下架。
deepseek-chat和deepseek-reasoner将在三个月后(2026年7月24日)停止使用,当前阶段这两个名称分别对应V4-Flash的非思考模式和思考模式。
这对个人开发者影响不大,只需修改model参数即可。但对接了生产环境的公司,需在这三个月内完成迁移工作。
额外信息
在发布稿的结尾,DeepSeek引用了一句话:
「不诱于誉,不恐于诽,率道而行,端然正己。」
这句话出自荀子的《非十二子》,字面意思是:不被赞誉所诱惑,不被诽谤所吓倒,遵循自己认定的道路前行,端正自身品行。
放在此次发布的场景中,这句话颇具深意。
过去半年,关于V4何时发布、是否跳票、是否已被其他产品超越、是否已被Claude通过蒸馏数据攻克等传言,在中英文AI圈反复流传。年初甚至有人笃定V4会在春节前发布,结果等到了四月底。
DeepSeek从未对此作出回应。
然后在某个周五的下午,他们推出了V4,同步开源,同步上线官网和App,同步更新API,还在发布稿中提及内部员工已弃用Claude的事实。
没有路线图,没有直播,没有访谈。
“率道而行”这四个字,听起来像是一句口号。但如果结合过去半年V3.2那次“亮点不足”的Exp版本、为V4铺垫了半年的DSA稀疏注意力技术,以及将1M上下文从核心优势转变为标配的发展路径来看,DeepSeek已经做到了。
DeepSeek-V4模型开源链接:
[1]https://huggingface.co/collections/deepseek-ai/deepseek-v4
[2]https://modelscope.cn/collections/deepseek-ai/DeepSeek-V4
DeepSeek-V4技术报告:https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
本文来自微信公众号“量子位”,作者:量子位,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com