
VLA模型π0.7展现自学与涌现能力,世界模型路径面临挑战





本文来自微信公众号:42号电波,作者:兰博,编辑:James
4月17日凌晨,美国具身智能企业Physical Intelligence(PI)发布新款VLA模型π0.7,在具身领域向行业证明了VLA的组合泛化能力。
在实际应用中,该模型面对未接触过的新任务时,能借助已掌握的技能自主构思解决方案。例如叠衣服任务,尽管π0.7此前无相关数据,却能「涌现」出这项技能,通过组合已有技能来完成叠衣服的操作。
PI称π0.7是「开箱即用的」VLA模型,无需针对具体任务微调,就能完成折箱子、做咖啡、打开抽屉等操作。
它还具备跨本体能力,即便陌生本体缺乏相关任务数据,搭载π0.7后的任务成功率,与拥有大量遥操经验的人类首次执行相同任务时的成功率相近。
实现这些能力的关键在于采用多样化且详细的Prompt,提升数据利用效率,这种数据处理方式在行业内较为罕见。
PI研究员Ashwin Balakrishna表示:「过去我总能根据训练数据推测模型的能力范围,这次却无法预测了。」
当前多数VLA模型仍局限于「见过才能做」,泛化能力高度依赖训练数据分布,而π0.7将VLA推向新高度,也让世界模型的发展路径感受到压力。

通才模型达到专才水平
机器人领域一直致力于打造能执行多任务的通用模型,但实际中多数任务需专项训练,远未达到通用标准。
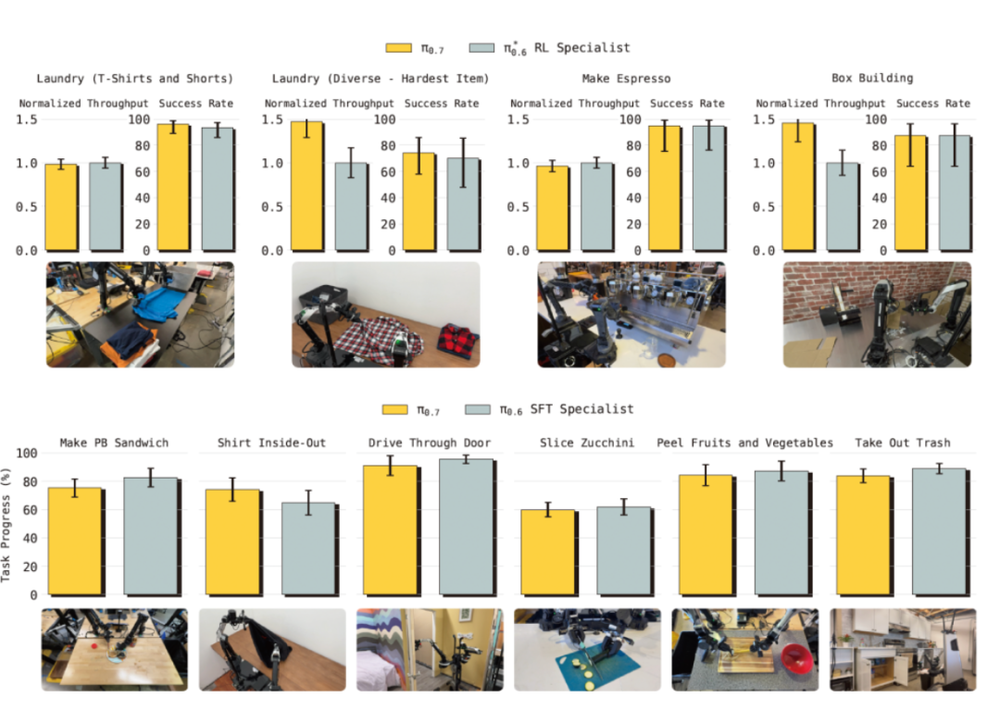
π0.7的开箱即用特性展现出通才潜力。实验数据显示,在做咖啡、叠衣服、装箱等任务中,尽管π0.7未针对这些任务专门训练,其水平仍追平了经微调的π0.6专家模型RL specialist和SFT specialist。
更值得关注的是,π0.7在叠衣服、装箱任务中的效率更高。
目前多数「专家模型」通过以下方式构建:
针对单一任务收集大量数据;
进行强化学习或监督微调;
将策略压缩为高度特化的模型。
这类专家模型的能力源于对单一任务的深度拟合,而π0.7的路径截然不同,它未针对特定任务额外训练,主要依赖已有能力的组合与复用。
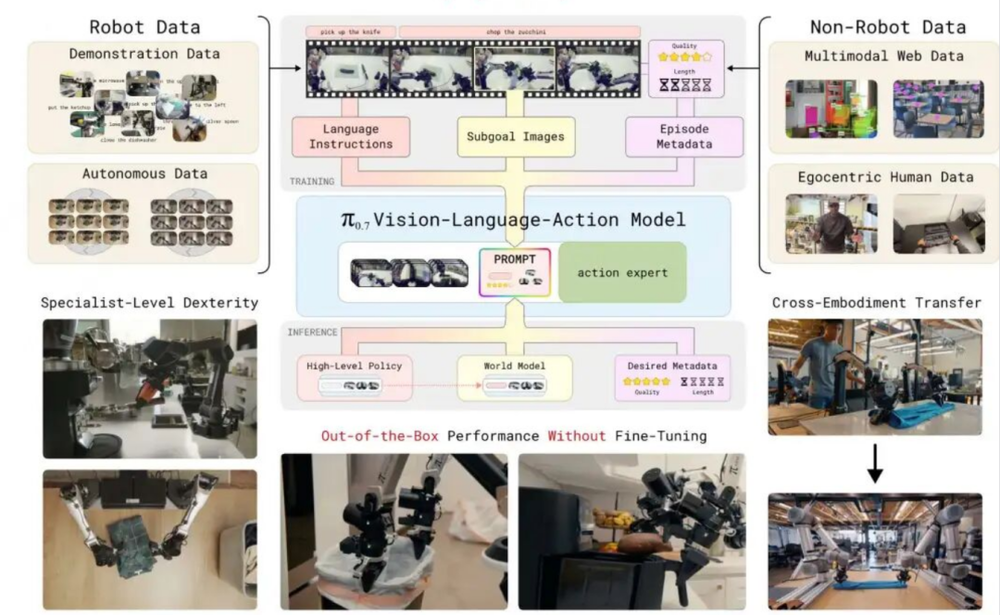
以叠衣服任务为例,它并非直接学会叠衣服,而是调用抓取、展开、对齐、折叠等在其他任务中掌握的基础能力,在执行过程中动态组合成新解决方案。
因此,π0.7能达到专才水平,是因为它更灵活,懂得复用能力,不受固定策略限制,执行中会不断选择更合适的动作组合。
π0.7的核心在于一种新的能力获取方式:用有限技能覆盖无限任务。

组合泛化能力的实现机制
从技术博客可知,PI的数据处理方式是实现这些能力的关键。
传统VLA对数据的组织接近「任务标签」,如倒水、抓取、开抽屉各为一类数据,模型学习输入到动作的映射,往往仅掌握表象,难以理解本质。
π0.7则转向另一种结构,将任务拆分为可复用的「技能单元」,再通过语言组合。
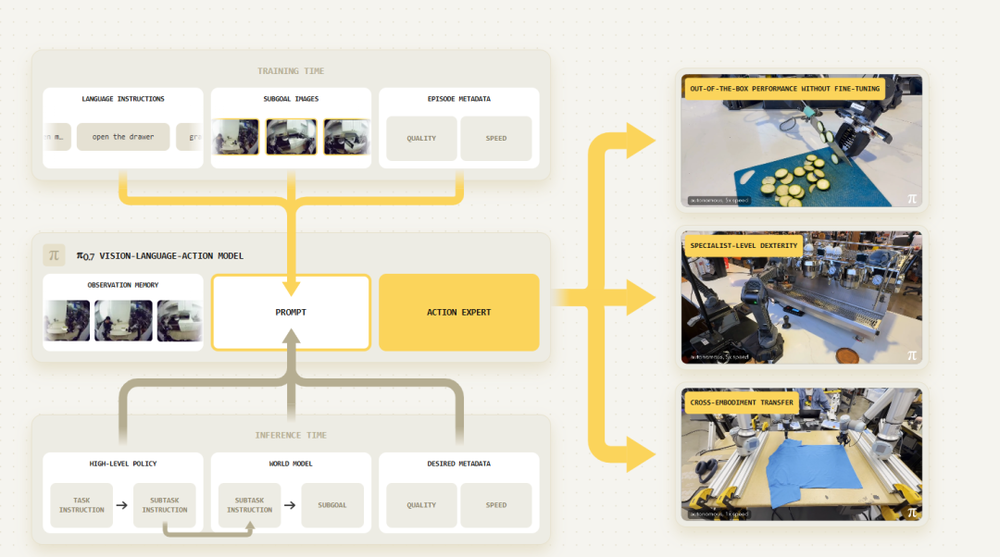
这意味着模型内部不再仅隐式拟合任务,而是逐渐形成:
可复用的动作基元(primitives)
对任务目标的结构化理解
基于语言的动态组合能力
这也是它面对叠衣服这类陌生任务时,能进行抓取、展开、对齐、折叠等组合推理,而非盲目猜测的原因。
这一步的关键是让任务表示从「样本驱动」转向「结构驱动」,使机器人能力像大语言模型一样逐渐具备「涌现」潜力。
通过工作人员的口述引导,机器人能完成打开锅盖、放入食材、关闭机器等操作,即便训练数据中这类任务极少。
口述即可教会机器人新技能,若能广泛应用,数据采集成本将大幅降低。
Prompt成为可控执行的引导机制
多数机器人系统中,Prompt仅为高层指令,实际行为由策略模型决定。
但在π0.7中,Prompt的角色发生转变,承担任务描述、执行约束和中间指导功能,形式更多样、详细:
任务拆解方式
操作顺序提示
纠错信号
PI的做法是给数据添加多样上下文,形成多模态Prompt,甚至包含任务完成后的预期画面。

此时,Prompt不再只是自然语言描述,而是与数据共同构成更丰富的上下文,包括任务拆解、操作顺序提示及潜在纠错信号。
这些信息在训练中被纳入,使模型推理时能基于这些结构决策。
PI团队强调,使用更多样、详细的Prompt可显著提升模型能力。
跨本体泛化实现软件硬件解耦
作为专注软件的具身企业,PI希望像自动驾驶软件公司一样,通过向机器人提供智能软件盈利。
但机器人领域硬件种类繁多,软件的跨本体泛化能力是PI必须解决的问题,这也是π0.7的核心能力之一。
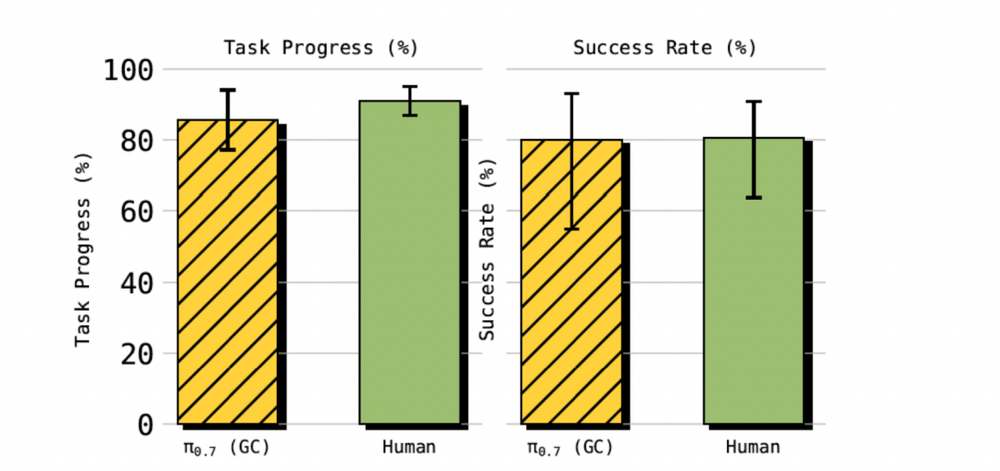
具体任务中,π0.7在叠衣服时,训练数据无UR5e机器人叠衣服的样本,但其完成度达85.6%。
相比之下,10名平均有375小时遥操经验的人类操作员完成度为90.9%,两者成功率相近,而π0.7在数据方面并无优势。
这种跨本体泛化潜力,为PI软件的大规模商业应用增添了底气。

写在最后
总体而言,π0.7的核心在于模型能力获取方式的转变。
以往模型能力增长多依赖数据覆盖,见过的任务才能完成,泛化能力高度受训练分布限制。
π0.7展示了另一条路径:用有限技能覆盖无限任务空间,使模型能力增长不再单纯线性依赖数据规模,更注重:
技能的拆解与复用;
任务的结构化理解;
通过语言的动态组合能力。
当这些条件满足后,机器人能力开始「涌现」,这种能力从结构与组合中自然「生长」。
因此,PI研究员难以通过训练数据预测模型能力边界,因为能力来源不再完全对应具体数据,而是来自更高层次的组织方式。
有趣的是,在世界模型热度高涨的当下,π0.7的出现让VLA路径重新受到关注,世界模型的发展可能因此面临挑战。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com