
国产大模型集中爆发:从技术追赶迈向价值突围






本文来自微信公众号:星海情报局,作者:星海老局,原文标题:《从DeepSeek到Seedance 2.0,国产大模型杀疯了》,头图来自:视觉中国
AI的进化从不遵循缓慢爬坡的轨迹,而是以突然跃迁的方式实现突破。
春节前的三天时间里,中国大模型行业就迎来了这样一次关键跃迁。从视频生成到代码工程,从多模态创作到长文本推理,多个热门赛道几乎同时取得进展,相关成果的发布既无预热也无长时间铺垫,迅速引发行业关注。
Seedance 2.0横空出世,DeepSeek与MiniMax在编程及Agent能力上完成迭代升级,智谱GLM-5以工程级能力开源亮相……这一系列密集发布不仅在行业内激起讨论,也让全球市场重新审视国产大模型的进化速度。
这场压缩在72小时内的集中爆发并非巧合,2026年或许正是国产AI从追赶走向突围的分水岭。
三天六厂,中国大模型集体展现新进展
2月9日,即梦发布Seedance 2.0。
起初,这看似只是一次常规的视频模型升级,但很快讨论风向发生转变。
用过AI视频工具的人,想必都对其不可控性带来的挫败感深有体会。
过去生成的AI视频,常出现人物形象前后不一、动作突然变形、分镜割裂等问题,仿佛是几段素材拼接而成。创作者为达到理想效果,往往需要反复修补细节,在不断试错中碰运气。
Seedance 2.0试图解决的正是这种不可控性。
此次字节采用统一的多模态生成架构,强化了复杂运动场景下的物理一致性。与1.5版本相比,Seedance 2.0在复杂交互和运动场景中的生成质量可用率有了进一步明显提升。
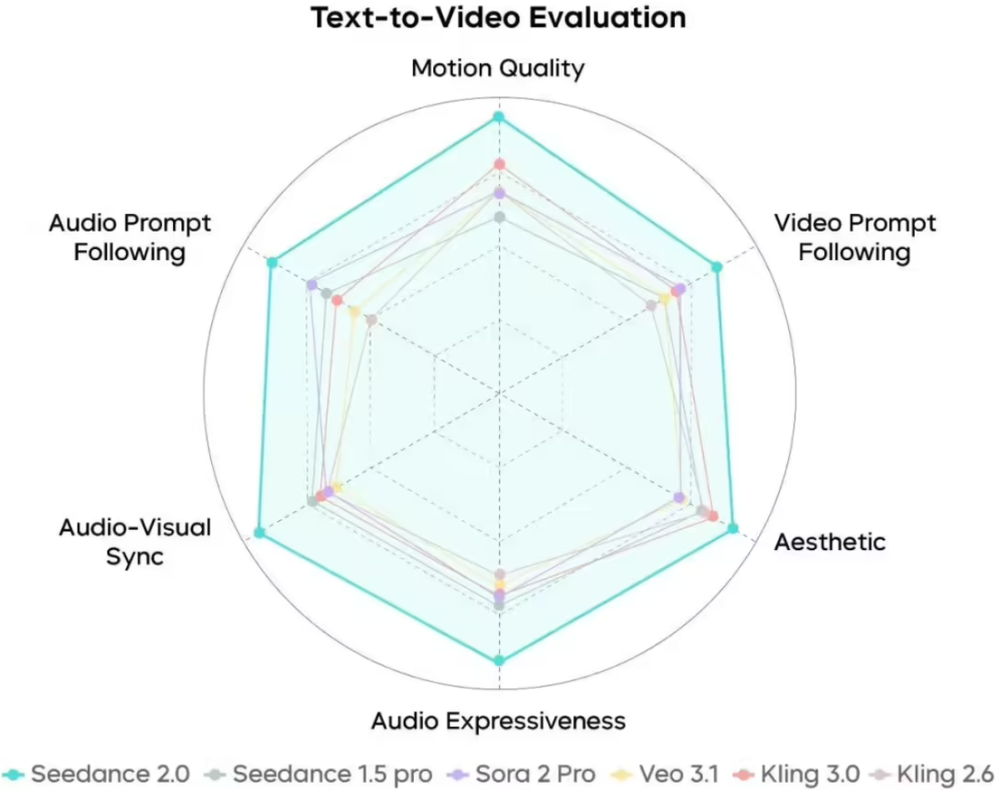
Seedance 2.0 文字生成视频能力评测 来源:IT之家
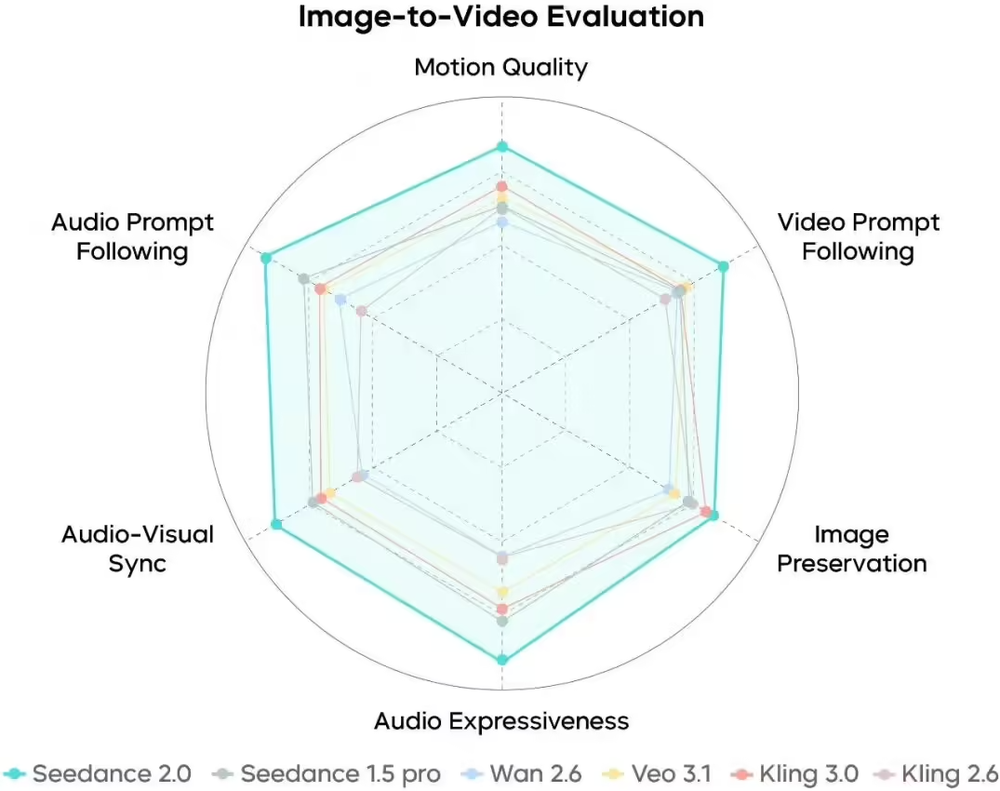
Seedance 2.0 图片生成视频能力评测 来源:IT之家
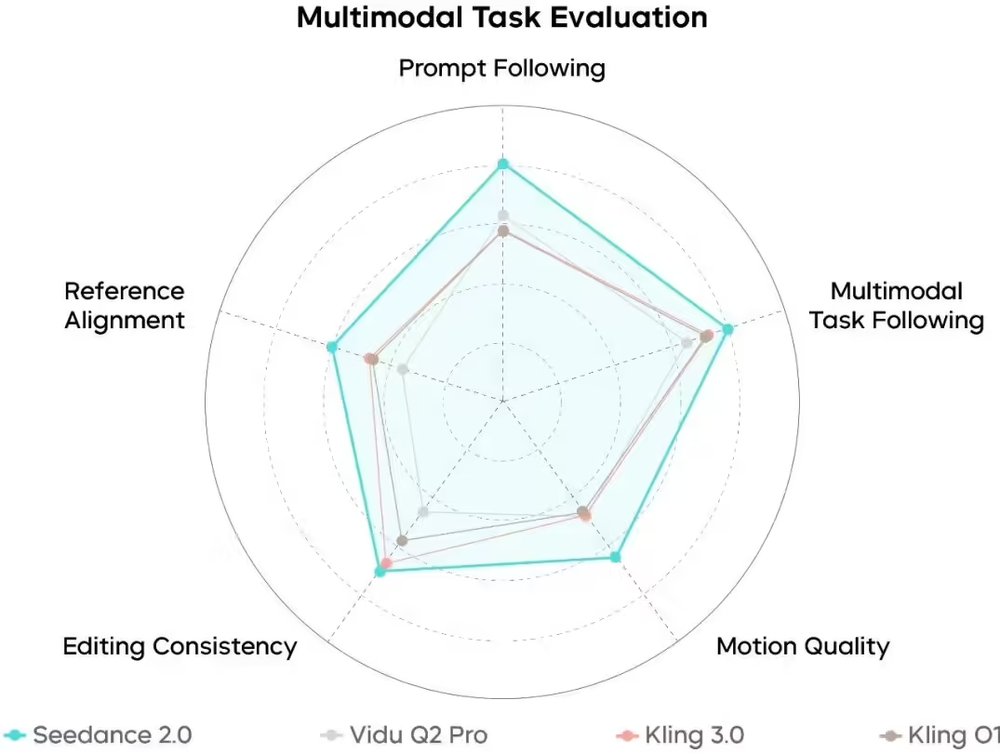
Seedance 2.0 图片生成视频能力评测来源:IT之家
例如,若想生成自己与奥特曼打斗的视频,只需上传个人视频与声音生成AI分身,再配合参考图和文字描述,模型就能自动完成分镜与剪辑,输出兼具4K画质和电影感分镜的成片。
这意味着AI视频生成工具首次具备工业级影视制作能力,不少人由此真切感受到“人人都是创作者”的时代即将来临。
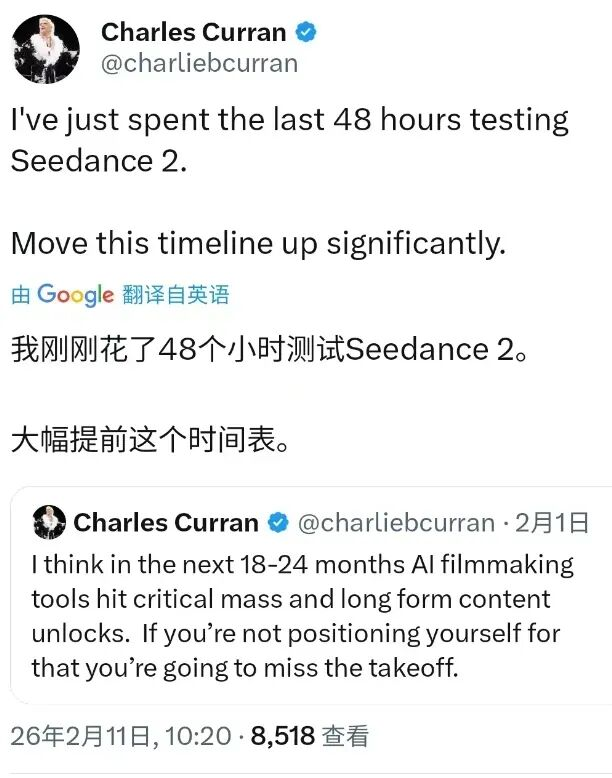
相关讨论迅速传到大洋彼岸。马斯克在X上转发Seedance相关内容,感叹“进展太快了”;好莱坞导演Charles Curran也公开探讨其对影视制作流程的影响。从影视行业到科技行业,Seedance的名字被频繁提及。
但这只是开始,在随后的72小时里,国产模型圈进入密集更新状态。
2月10日,阿里发布Qwen-Image-2.0,重点解决图片编辑中的文字排版难题。用户可让模型将整篇《兰亭集序》准确排入画面,生成古风书法海报,无需担心错字或乱码问题。
同一天,腾讯混元发布HY-1.8B-2Bit模型。这是一款面向终端设备的轻量级大模型,在大幅压缩体积的同时保留核心能力,能更高效地在手机等消费级设备上运行,意味着大模型开始真正走向端侧,不再完全依赖云端算力。
2月11日,MiniMax与DeepSeek几乎同时更新。前者切换至M2.5版本,优化工具调用与任务执行能力;后者将上下文长度扩展至百万Token级别。
2月12日,智谱宣布开源GLM-5。这个此前在OpenRouter匿名上线、已被开发者用于真实项目的模型,终于公开身份。
根据Artificial Analysis榜单,GLM-5位居全球第四、开源第一,且已完成与多家国产芯片平台的深度适配。
串联这几天的事件,一个趋势愈发清晰:这72小时改变了国产大模型的竞争方向。
告别参数竞赛,国产AI转向务实路径
回溯2023、2024年,国产大模型的主旋律可概括为“对标GPT-4”。
那段时间,几乎每款新模型发布,宣传中都会出现“接近GPT-4”或“局部超越GPT-4”的表述。
2024年初,智谱发布GLM-4时强调模型性能直追GPT-4;百川智能推出Baichuan 3时,也在报道中提及模型在部分中文评测中实现对GPT-4的反超。
当时的大模型行业里,榜单、分数和参数是唯一的硬通货。
技术进步有目共睹,但随着模型能力提升,一个现实问题逐渐凸显:资金从何而来?
模型更强不代表商业化之路更顺畅,训练和推理所需的算力成本持续上升,而应用端的付费意愿并未随参数规模扩大同步增长。
市场逐渐冷静,开始思考如何将大模型能力转化为真正的生产力。
这种压力并非国内独有,在大洋彼岸,OpenAI也面临盈利挑战。
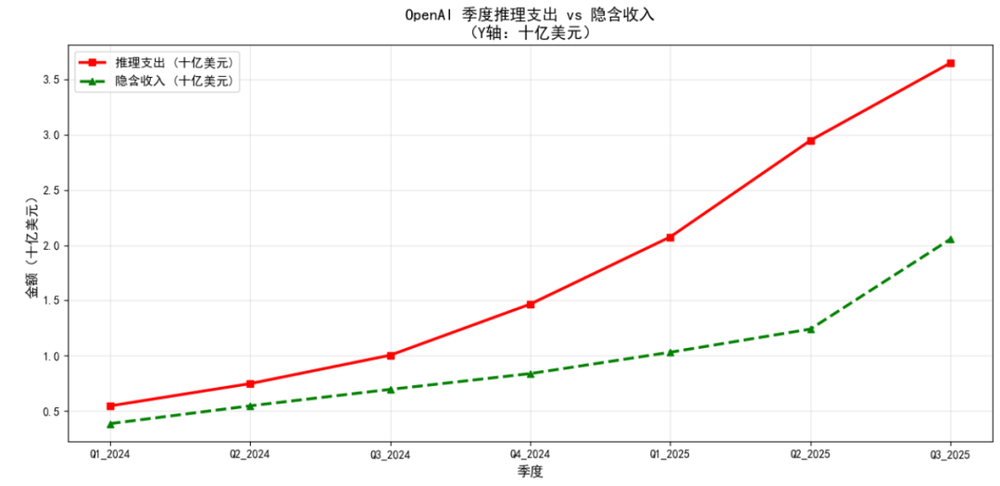
OpenAI,可能创造了历史上最快的烧钱速度 来源:新智元
据路透社报道,尽管ChatGPT用户规模庞大,但长期付费比例有限,OpenAI不得不探索广告和多元化收入结构,以覆盖不断攀升的研发和算力投入。
硅谷投资人Mary Meeker指出,大模型公司的核心挑战已从单纯的技术突破转向盈利结构的可持续性。在高成本与价格竞争的双重压力下,利润空间不断被压缩。
大模型技术领先不等于商业成功。
了解这一背景后,再看前几天72小时的密集发布,就能更清晰地发现变化所在。
此次厂商们不再执着于“全面超越”的宏大叙事,而是聚焦于用大模型解决具体问题。
Seedance深耕内容创作领域,打磨影视制作能力;通义千问Qwen-Image攻坚排版与设计场景;MiniMax、DeepSeek和智谱则将重心放在效率提升和工程执行上。
国联民生证券指出,随着Agent(智能体)时代到来,行业价值重心正从流量规模转向执行能力与结果付费机制。
只有当大模型能理解并完成完整项目(而非仅生成零散代码)、生成的视频可直接进入生产流程(无需大量后期修补)、能调用工具、输出标准文档并参与实际协作时,才算完成完整的商业闭环。
因此,在这轮密集更新中,参数规模退居幕后,落地能力成为新的竞争重心。
国产大模型正沿着这条更务实的路径,从技术追赶迈向价值兑现。
中国AI:构建自主系统能力
大模型的密集爆发并非偶然,背后是国家级系统能力的支撑。
据新华社报道,截至2026年初,中国人工智能企业已超6000家,核心产业规模突破1.2万亿元,同比增长近30%;国产开源大模型全球累计下载量超100亿次。
这组数据表明,大模型已不再是几家公司间的参数竞赛,而是嵌入完整产业链之中。上游是国产芯片和算力平台,中游是模型与开发框架,下游则连接电网、制造、金融、政务等真实场景。
国家系统能力的第一层支撑是算力环境的成熟。
近年来,国产大模型越来越强调与本土算力平台的深度适配。
智谱发布GLM-5时明确表示,模型已适配华为昇腾、寒武纪、摩尔线程等国产算力平台;DeepSeek也公开提到,通过与国产硬件协同优化推理效率,降低算力成本。
当国产软硬件开始协同迭代,成本曲线和效率曲线都会发生变化,模型能力的释放也因此更稳定、更可控。
第二层支撑是应用规模的真实落地。
在中国,大模型的应用场景天然密集,它并非停留在技术层面,而是会迅速进入基础设施的应用层面。
例如“光明电力大模型”已覆盖国家电网总部及27家省级公司,在无人机巡检场景中,年巡检杆塔达500万基,人工登塔次数减少约40%。
企业端的变化同样显著,《亿邦动力》报道,一家半导体设备企业将海外CRM系统替换为国产AI CRM后,通过智能体实现客户流失预警与资源自动调度,运维成本下降超50%。
第三层支撑是生态协同方式的差异。
与美国更强调单一闭环生态不同,中国路径偏向开源与本土化适配,这种策略让模型、芯片、平台与行业应用之间形成更紧密的连接。
据MIT与Hugging Face联合报告,中国开源大模型的全球下载占比超17%,高于美国的15.8%。与此同时,“超算互联网”等基础设施正在打通算力与模型资源的调度通道。
国产大模型升级不再只是代码版本更新,而是算力、平台、行业应用的同步推进。
第四层支撑是战略方向的确定性。
我国“十五五”规划建议明确提出,要加强人工智能与产业、民生、监管的深度融合,将AI作为数字经济的重要基础设施来建设。这种顶层设计为产业提供了明确的长期发展坐标。
当算力环境逐步稳定、应用场景高度密集、产业链协同推进、政策方向清晰这些条件同时具备时,模型的集中爆发就不再是偶发事件,而是必然结果。
在这场从技术到产品、从比肩到突破的突围战中,中国AI正摆脱“追赶者”心态,逐渐拥有“领先者”的底气。
结语
彼得·德鲁克在《创新与企业家精神》中指出,创新的意义不在于技术本身有多先进,而在于能否为资源创造新的价值。
这句话放在今天的AI竞赛中再合适不过。
当大模型告别参数比拼,像电力一样成为人人触手可及的基础设施,能够解决实际问题时,它才真正拥有改变世界的力量。
或许,这才是这一轮集体突围带给我们的真正启示。
参考资料
1.Seedance官网
2. 2024-2025年中国AI大模型市场现状及发展趋势研究报告,艾媒咨询
3. 2025年中国大模型行业发展研究报告,36氪研究院
4. 中国大模型落地应用研究报告2025,InfoQ 研究中心&中欧 AI 与管理创新研究中心
5.密集“上新” 国产大模型商业化竞速升级,经济参考报
6. 中国大模型正跻身全球第一梯队,新华网
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com