
AI生成内容标识新规:给虚假信息套上紧箍咒





这一标识办法的出现,旨在震慑黑灰产。
互联网上真假难辨,去伪存真成了当下网民上网必备技能。然而,随着生成式人工智能(AIGC)的成熟,互联网世界的一切愈发真假难分。

为解决AI虚假内容泛滥问题,国家网信办等四部门联合发布《人工智能生成合成内容标识办法》。从今年9月1日起,所有AI生成的文字、图片、视频等内容需添加显式和隐式两种标识。显式标识能被用户明显感知,隐式标识则添加在生成内容的元数据中。
与微信、抖音等平台此前建立的AI内容管理体系相比,新规最大变化是发布者成为AI内容第一责任人,需对AI虚假内容负主要责任。不过,让内容发布者充当第一道防火墙,也是无奈之举。

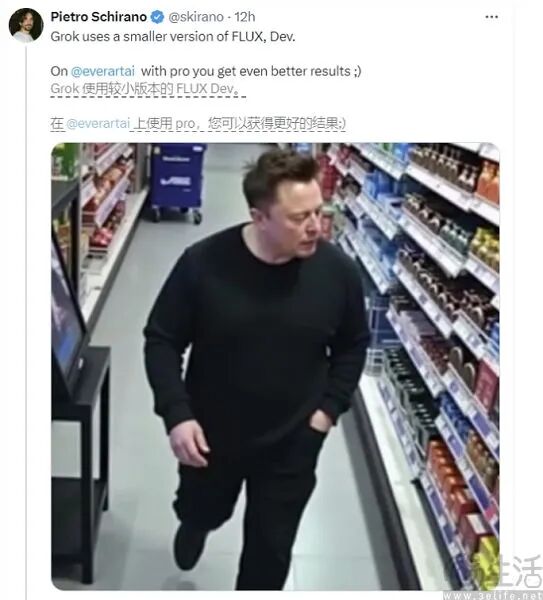
如今,AI成了互联网最大的谣言制造机,像“AI马斯克”骗老人退休金、“Yahoo Boys”用AI视频搞“杀猪盘”等黑产利用AI作恶的消息屡见不鲜。黑产利用多模态AI大模型生成的内容以假乱真,让人们难以分辨。
实际上,AIGC前置技术深度学习诞生不久,黑产就盯上了它。但当时机器学习有局限,使用门槛高。比如2017年的deepfakes(深度伪造)技术,虽开源,但玩转它所需的生成对抗网络(GAN)和变分自编码器(VAE)并非一般人能掌握。
以ChatGPT为代表的AI大模型技术出现,让deepfake走入寻常百姓家。以往伪造内容需在特定工具中反复调试参数,如今科技巨头为争夺AI时代先机,大力推进AI技术普惠化。
大语言模型和多模态大模型的出现,让文生音频、文生视频成为现实。众多AI产品实现了用自然语言无中生有。谷歌发布的Nano - banana颠覆了Photoshop,不仅能“生图”,还能按自然语言做复杂修图,使人工编写内容与AI创作内容的差异越来越小。
到了2025年,若有“作恶”想法,“作案工具”唾手可得。那么,能否让AI厂商从源头杜绝AI大模型产出有害虚假内容呢?实际上,OpenAI、谷歌等大厂一直在努力,“AI安全护栏”(AI Guardrail)就是他们为让AI符合人类期望而设计的防护机制。
AI厂商通过动态意图分析等方式,用“安全护栏”保护AI。但“AI安全护栏”存在缺陷,因为AI大模型要有智能就需自主决策能力,开发者无法将安全护栏设置得密不透风,以完全杜绝有害内容、恶意攻击或敏感信息泄露。
也就是说,“AI安全护栏”若过于严密,AI模型会变“智障”,大厂不可能为安全让自家AI如此。因此,他们尝试给AI内容打水印,让用户辨别。
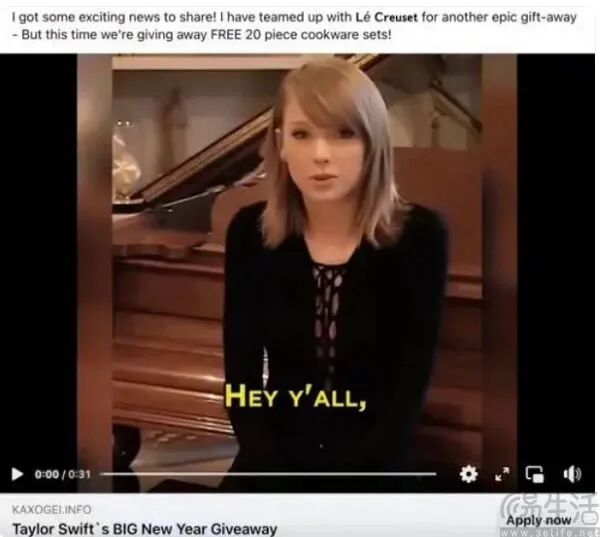
去年夏季,微软等公司组建C2PA,试图用水印技术区分AI生成内容和人类作品。但美国研究人员发现,AI水印不牢固,通过调整亮度等技术就能去除。
国内互联网大厂常用的运营方式在AI虚假内容面前也不太管用。为助用户区分虚实,微信等平台要求创作者主动声明“内容由AI生成”,但大量创作者担心被限流,导致很多AI生成内容未主动表明身份。这是因为平台对AI态度复杂,既希望AI赋能创作,又怕低质量AI内容污染社区氛围。
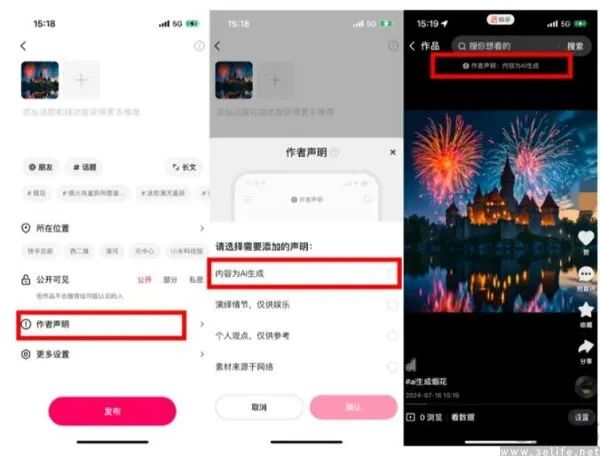
在当前技术条件下,将责任传导到创作者是遏制AI虚假内容的有效手段。毕竟主动炮制虚假内容多带有主观恶意,一般人用AI创作多是“图一乐”。
使用AI生成虚假内容的人难以给出合理解释,所以《人工智能生成合成内容标识办法》的出台,无疑能震慑想用AI“搞事情”的潜在黑灰产。
本文来自微信公众号“三易生活”(ID:IT - 3eLife),作者:三易菌,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com