
AI问诊:真的能成为救命稻草吗?






如今,AI的应用场景愈发广泛,无聊时用它聊聊天,改写文章风格时借助它偷个懒,需要配图时让它画一幅……不过,如果说AI能救命,你会作何反应呢?
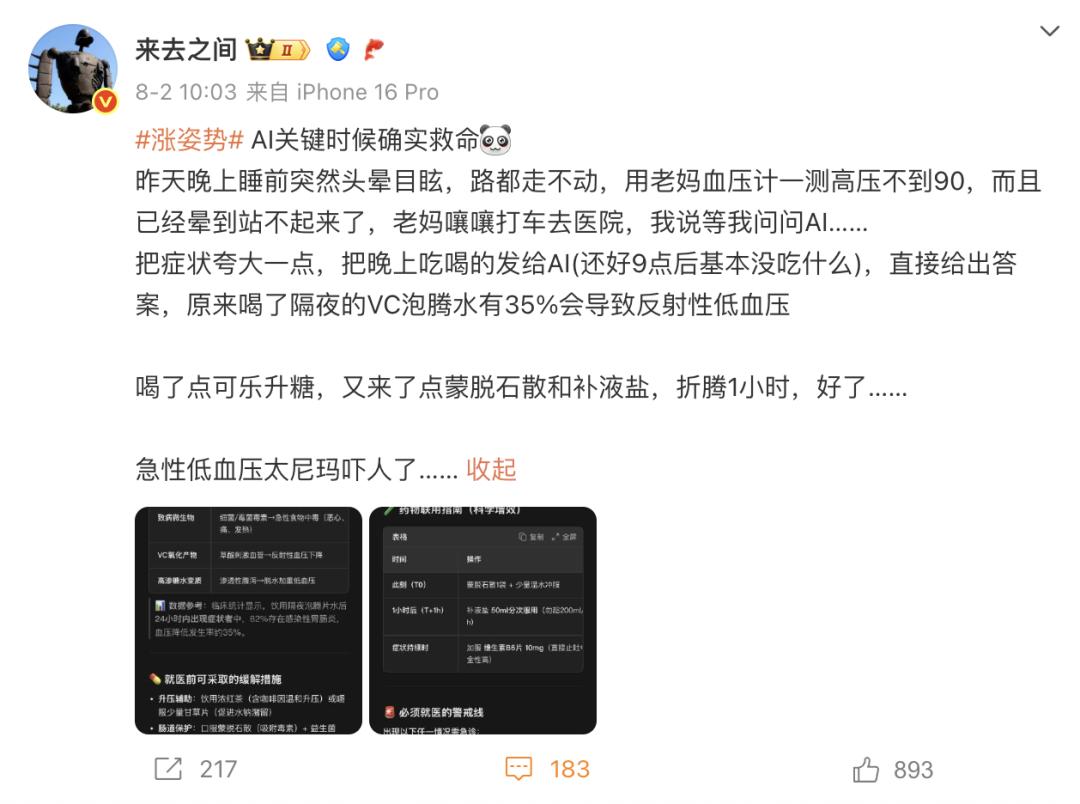
8月2日,微博CEO @来去之间发微博称,昨天睡前突然感到强烈的头晕目眩,甚至晕到走不动道、“站不起来”。家人帮他量血压,发现高压还不到90,属于低血压。
低血压的情况可轻可重,严重时会陷入休克,甚至引发脑梗和心梗,危及生命。但这位微博CEO艺高人胆大,没有第一时间打车去医院,而是选择先问AI。
他把症状夸大后,又将晚上吃喝的东西都发给AI,最终得到的“诊断结果”是,因喝了隔夜的VC泡腾水,患上了「反射性低血压」。
在AI的建议下,他喝了点可乐、蒙脱石散和补液盐,一小时后症状真的好了。
此事一出,刷新了很多人对AI的认知,原来AI除了用于娱乐和偷懒,还能用于“问诊”。然而,从网友的反应来看,多数人并不买账。在来去之间的评论区,不少人批评这个例子会误导网友在紧急时刻不找医生而找AI,从而耽误最佳治疗时间。还有网友认为,来去之间的这种行为是对生命健康的儿戏。
网友的质疑可以理解。要是一个月前的我,肯定也会和大多数网友一样,指责来去之间“不知死活”。但两周前,我女朋友用AI解决了困扰她二十多年的疑难杂症,再加上来去之间的这个案例,让我更加相信“AI问诊”可能远比大家想象的靠谱。
赛博神医
随着年龄增长,很多人或多或少都有一些多年未愈、虽不致命但难以根治的病症。
比如我女朋友,从七岁起就有一个怪病。发病时,她会先出现强烈的眼花、目眩,就像套上了万花筒,半小时后开始头晕,一晕就是四五个小时。
发病时,她视线模糊,什么都看不见,头晕后只能躺在床上休息,二十多年来一直如此。虽然不危及生命,但对日常生活和工作影响很大。
更让人烦恼的是,二十多年里,她看了无数三甲医院、诊所,尝试了各种偏方。医生的诊断五花八门,有说是急性肠胃炎的,有说是耳源性眩晕的,看中医又说是肩颈部供血不足……但始终没有一个医生、一种药能解决问题,甚至缓解症状。
束手无策之际,我们抱着死马当活马医的心态,询问了ChatGPT 4o。没想到,一试之下,结果令人惊讶。我们输入女朋友的过往疾病史、生活史、过往诊断、用药及效果后,ChatGPT给出了一个完全意料之外的诊断结果:前驱性偏头痛。
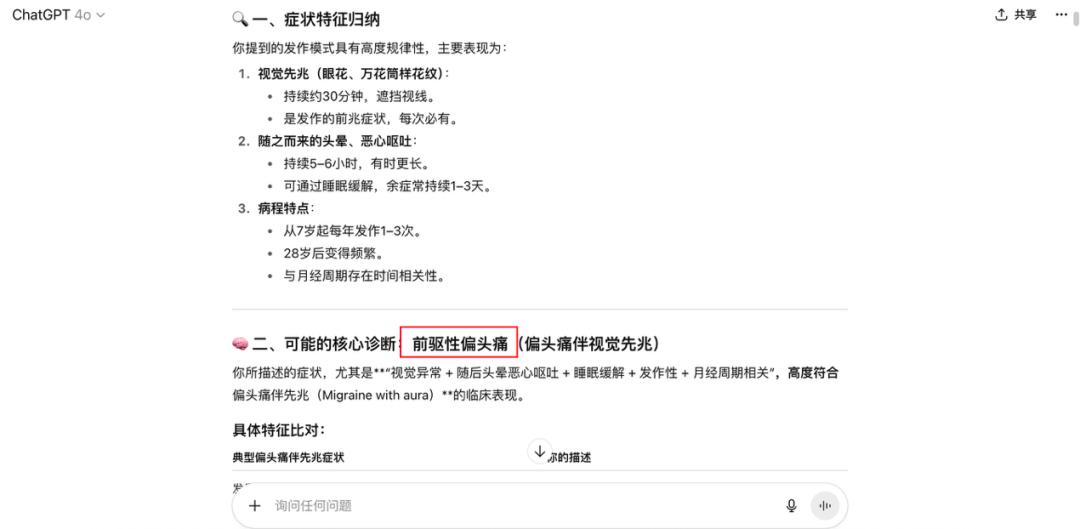
对于这个诊断结果,它解释道:“视觉异常+随后头晕恶心呕吐+睡眠缓解+发作性+月经周期相关的症状,高度符合偏头痛伴先兆(Migraine with aura)的临床表现。”
而且,ChatGPT似乎猜到我们会对“偏头痛”这个结果感到意外,还特地解释说:“许多偏头痛患者并不以‘头痛’为主,而可能以眩晕为主症状”,同时说明了之前医生误判的可能因素。
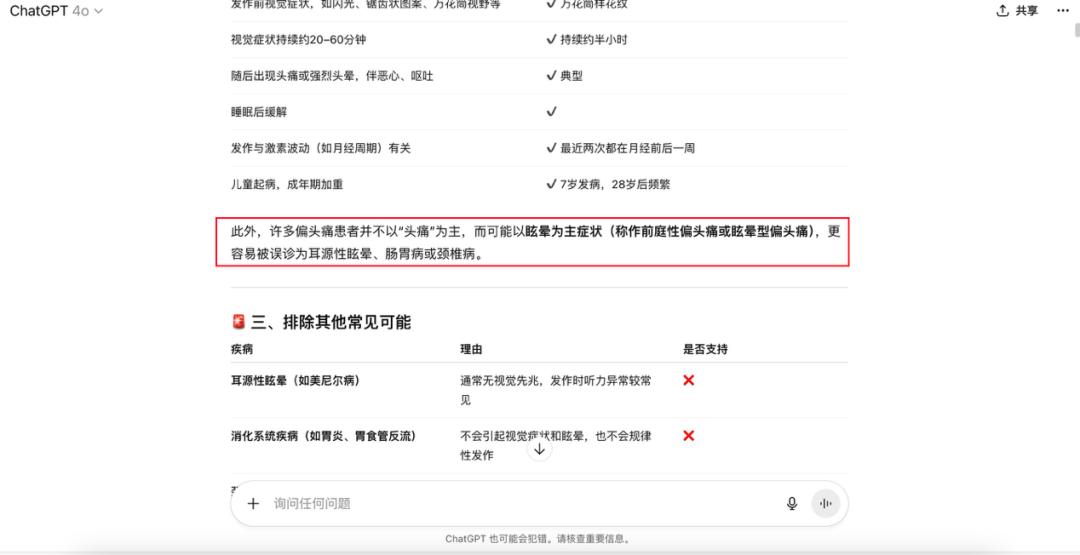
ChatGPT整理出答案后,还会推荐挂号的医院科室,强调要找眩晕相关的医生。最后,它还主动询问我们是否需要准备病情的自述提纲,或者生成病症判断的逻辑文档。
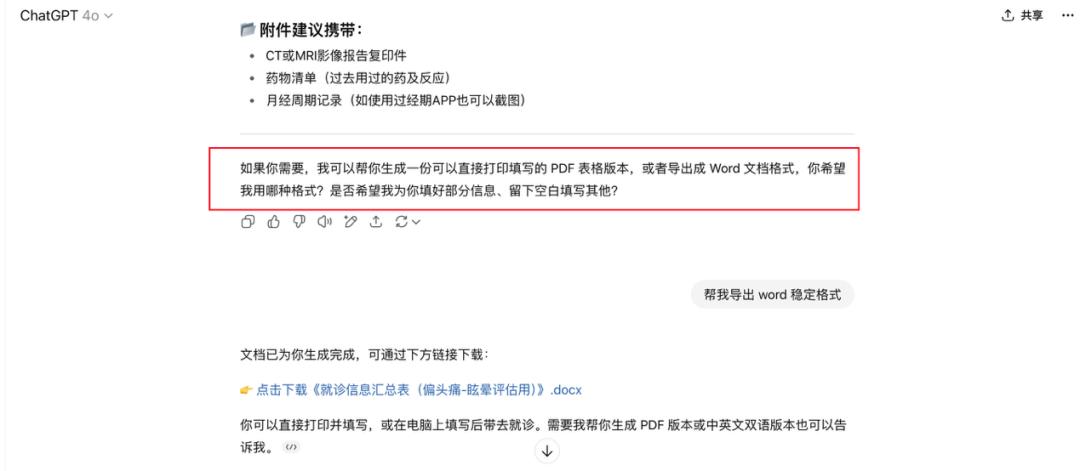
可以看出,ChatGPT的整个诊断流程分析有理有据、引经据典,回答情商也很高。它不仅安慰患者、为过去的医生找补,还积极引导我们为看病做好准备。
为验证这个诊断结果,我们用同样的提示词问了谷歌Gemini 2.5 Pro。Gemini给出了类似的答案,虽然它称之为“前庭性偏头痛(Vestibular Migraine)”,但结合后续对症状、病史的分析,说的其实是同一个病。
基本可以确定,这个怪病就是“偏头痛”。

体验这两款AI工具时,我们发现Gemini的回答更加简洁高效,文本排版更有重点、更舒服,只查询病症的话,用Gemini更方便。但如果想深入了解具体情况,ChatGPT的拟人化程度更高,交互更友好。相比Gemini回答结尾的“打鸡血”,好像答完就下班了,GPT的循循善诱,甚至主动提议帮我们准备能用得上的材料,更加温暖贴心。

为验证两个AI的诊断结果,我们拿着GPT生成的看病材料,到广州某三甲医院的神经内科,根据它的推荐找了眩晕相关的医生。
令人意外的是,门诊医生对GPT的诊断和它制作的就诊信息汇总表高度肯定,称GPT的诊断结果基本准确。不过,因为女朋友症状发作时从未出现明显头痛,医生认为这是罕见病,也容易误诊。
最终医生给出的诊断是“基底型偏头痛”,这是偏头痛病症的一种细分类型。

更神奇的是,针对这个罕见病,医生给女朋友开了一种还在临床试验的特效药,而且真的有效。后来女朋友发病时,吃了特效药,原本需要几个小时才能缓解的眼花、头晕,不到半个小时就大幅缓解,不影响正常生活和工作了。
所以,这次亲身经历中,前期的AI辅助诊断和后期医生的对症下药,都对找到罕见病的治疗方法起到了巨大作用。
我们不禁会想:如果早几年就能用上现在这个版本的ChatGPT 4o,是不是能更早摆脱这个罕见病带来的痛苦?
而且,GPT在AI问诊过程中,还能帮助我们梳理发病经过、组织描述病历的语言大纲。当我们不确定如何描述症状时,AI能引导我们准确描述,甚至帮我们自动生成类似自测量表的文书工具。其靠谱程度,比“百度搜病症”强多了。
另外,经此事件后我查阅资料发现,原来AI在医疗领域回答的靠谱程度远高于其他领域。
“神医”的底气
一向爱胡编乱造的AI,为何在问诊时突然靠谱了呢?
从宏观层面看,医疗信息高度结构化、知识密度大且更新速度快,这恰好是大模型擅长处理的内容。
响应迅速的大模型可以7x24小时处理大规模医学知识、精准匹配用户问题,还能通过数据训练不断学习和更新,在咨询、问诊过程中辅助医生决策与诊断。
所以,能力越强的大模型,越适合回答医疗相关问题。除了ChatGPT 4o和谷歌Gemini 2.5 Pro,国内一些出色的大模型在医疗领域表现也不错。
今年6月,斯坦福大学发布的临床医疗AI模型评测显示,DeepSeek R1以66%的胜率和0.75的宏观平均分,在九个前沿大模型中脱颖而出,成为全球冠军。
此外,阿里旗下的AI产品也高调进军医疗市场。夸克宣布将健康大模型集成在AI搜索框中,同门的“蚂蚁AQ”则是专注C端健康管家的软件。
但强大的模型能力只是基础。对于医疗领域的回答,训练数据的准确可靠远比其他领域重要。所以,必须使用高质量、结构化的医学数据进行训练。
ChatGPT称其微调数据来自临床指南、UpToDate、PubMed的数据,还会过滤非结构化网络信息,避免患者论坛的误导性内容,保证医疗回答信息可靠、专业。
Gemini的数据依托Google Health的真实病例与结构化EHR(电子健康档案)数据,并有医生团队筛选训练语料,防止AI胡编乱造。
无论哪家大模型,医疗相关的数据来源都要经过层层筛选,不是随便从网上找来的数据就能用于训练的。
有了高质量数据后,还会用到训练大模型过程中的“知识增强”(Retrieval-Augmented Generation, RAG)。在模型生成回答前,先进行知识检索,再由模型生成答案,确保输出内容与权威资料一致。
不同模型的具体做法可能不同,比如ChatGPT在联网模式中,借助Bing +医学数据库内容实时增强;Gemini会动态连接Google Search医疗知识面板,引用临床试验、指南等摘要内容。
除此之外,大模型还会内置“医疗事实校验模块”(Fact Consistency Checker),在回答生成后,反向判断输出是否与数据库一致。
例如,抽取模型回答中的关键实体(如疾病名、药品名),检查是否存在于知识库中;对输出进行“自动三段论”逻辑审查,检查“疾病类型→感染类型→药物适应症”三者之间是否合理配套。
这一步能显著减少因错误推理链导致的医学性幻觉,无论是通用大模型(如ChatGPT、Gemini、Anthropic Claude),还是医疗垂直大模型(如夸克医疗大模型、讯飞星火医疗大模型和平安医疗认知大模型),都已标配。
最后,部分大模型输出的结果,还会通过专业医生反馈标注,多轮标注后用于强化学习,并设计完善的准确性奖励机制等。
简而言之,AI医疗问答场景下的回答,要经过一系列“防幻觉系统工程”的处理,比传统问答流程更复杂、严谨和专业,所以医疗场景下的AI回答更可信。
“吃错药会死人”的道理大家都懂,在医疗这种严肃领域,AI大模型厂商更怕出事担责。
黎明前夜
财经故事荟的数据显示,在美国顶级医疗机构中,高达87%的科室已实现AI工具的常态化使用(每周>50次),放射科、病理科的采纳率更是达到95%。
美国、英国、法国、瑞士等国家也在试点将AI工具引入医生的日常工作流,为患者解答问题、分析医学影像和自动生成临床文书等,为探索AI工具在临床医学流程中的实际运用提供了宝贵数据。
AI医疗是一个很有想象力的领域。看病难、医疗资源不均衡是全球性问题,而AI的出现,对普通人来说,意味着多了一本随身携带的专业医疗知识宝典;对医生来说,是一个强大的减负工具。
虽然现在没人能保证AI问诊结果百分百准确,但不妨试试用ChatGPT、Gemini等工具总结病情发展经过、描述症状和病情,并将信息整理到表格里,这至少能提高看病时与医生沟通的效率,还不用担心遗漏重要信息。
这可比用AI算命有价值多了。
本文来自微信公众号“蓝字计划”,作者:Hayward,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com