
被忽视的AI力量:数据采集作为基础设施






人工智能社区热衷于追求更大的模型、十亿令牌上下文窗口以及GPU的微调运行,然而,人工智能堆栈中最易被忽视的强大力量却潜藏于这一切的底层,那就是数据。
需要明确的是,尽管扩大模型规模仍有其重要性,但对于大多数现实世界的人工智能产品而言,性能的提升越来越依赖于数据的质量和新鲜度,而非仅仅是参数的数量。为了获取边际收益而将模型规模翻倍,不仅成本高昂,而且在环境方面也难以持续,因为巨大的电力和水成本根本无法实现大规模扩展。
这一瓶颈已从堆栈中凸显出来。
构建AI原生产品的创始人和首席技术官逐渐意识到,他们的代理出现问题,并非是“模型”本身“不够智能”,而是因为它盲目地处理过时、不相关或不完整的上下文。例如,Salesforce在2025年5月斥资80亿美元收购了Informatica,目的是增强其AI驱动的Agentforce平台。通过此次收购,他们能够访问高质量的实时数据,从而获得更准确、更具扩展性的成果。
性能的优劣取决于能够检索到的数据,而不仅仅是提示的方式。除非使用H100集群或运行着API预算无限的前沿模型,否则超越巨头的最佳途径是在可承受的范围内为模型提供更智能的数据,即领域特定、结构化、去重且新鲜的数据。
但在构建上下文之前,数据必须先存在。这就需要可靠、实时地访问开放网络,不仅仅是进行一次性的数据抓取或获取数据集,而是要建立能够反映当前情况的强大管道。
各位,这就是基础设施。如果说计算让NVIDIA变得不可或缺,那么我认为下一个重大突破不在于更多的层数,而在于获取更多有价值的信号而非噪声。而这一切始于将数据采集视为生产基础设施。
“好数据”的标准
如果正在构建一款AI原生产品,系统的智能程度将不再取决于提示的巧妙程度,或者上下文窗口中能容纳的标记数量,而是取决于为其提供当下重要上下文的能力。
但“好数据”的定义较为模糊,下面来具体说明它对人工智能的意义:
领域特定:例如AI辅助优化零售定价,需要的是竞争对手数据、客户评论或区域趋势等相关信息,而非无关的噪音,必须做到精准定位。
持续更新:网络变化迅速,错过今日X趋势的情绪模型,或使用上周价格的供应链模型,都已过时。
结构化和去重:重复、不一致和噪声会浪费计算资源并稀释信号,结构比规模更重要,干净的数据胜过庞大的数据。
实时可操作:过时的数据毫无价值,实时数据如价格变动、新闻、库存变化等,能够为即时决策提供支持,但前提是数据收集必须合乎道德、可靠且可规模化。
这就是Salesforce收购Informatica的原因,不是为了新模型,而是为Agentforce提供结构化的实时数据,以改善下游决策。
同样,IBM在2024年7月斥资23亿美元收购了StreamSets用于打造Watsonx。StreamSets专注于从混合数据源提取数据、监控数据流并处理模式漂移,这使IBM能够跨企业系统为Watsonx提供最新、一致的信号。对于需要基于实时状态进行推理的AI来说,这种基础设施能带来10倍的增效效果。
Dataweps转向Bright Data为飞利浦和华硕等电商客户收集实时竞争对手定价和市场趋势也是出于类似原因。他们的AI驱动定价和竞价系统依赖于快速、准确的数据,而Bright Data的API驱动生态系统(包括代理、存档/数据集、支持AI代理的浏览器自动化工具等)使他们能够可靠且大规模地收集这些数据。Bright Data不仅是数据抓取工具,更是一家AI基础设施提供商。
关键在于,检索质量如今比提示工程更为重要。即使是最好的提示也无法解决模型在推理时提取过时或不相关数据的问题。
在当下,正确的环境是后Deepseek时代AI生存或消亡的关键。
数据采集的挑战
乍一看,数据基础设施似乎只是管道,如采集管道、转换、存储等,显得枯燥乏味。但在RAG和代理AI时代,这种管道变得至关重要。因为系统不再只是进行推理,而是基于外部、不断变化的多模态实时信息进行推理,这改变了一切。
我认为,现代人工智能数据栈已发展成为一个成熟的价值链,涵盖信息的获取和提取、转换和丰富、整理和排序,以及存储并提供给合适的组件(无论是模型、代理还是人类)。每一层都面临着实时挑战和现实后果,与传统的ETL管道不同,它并非只是将数据录入数据湖然后搁置一旁。
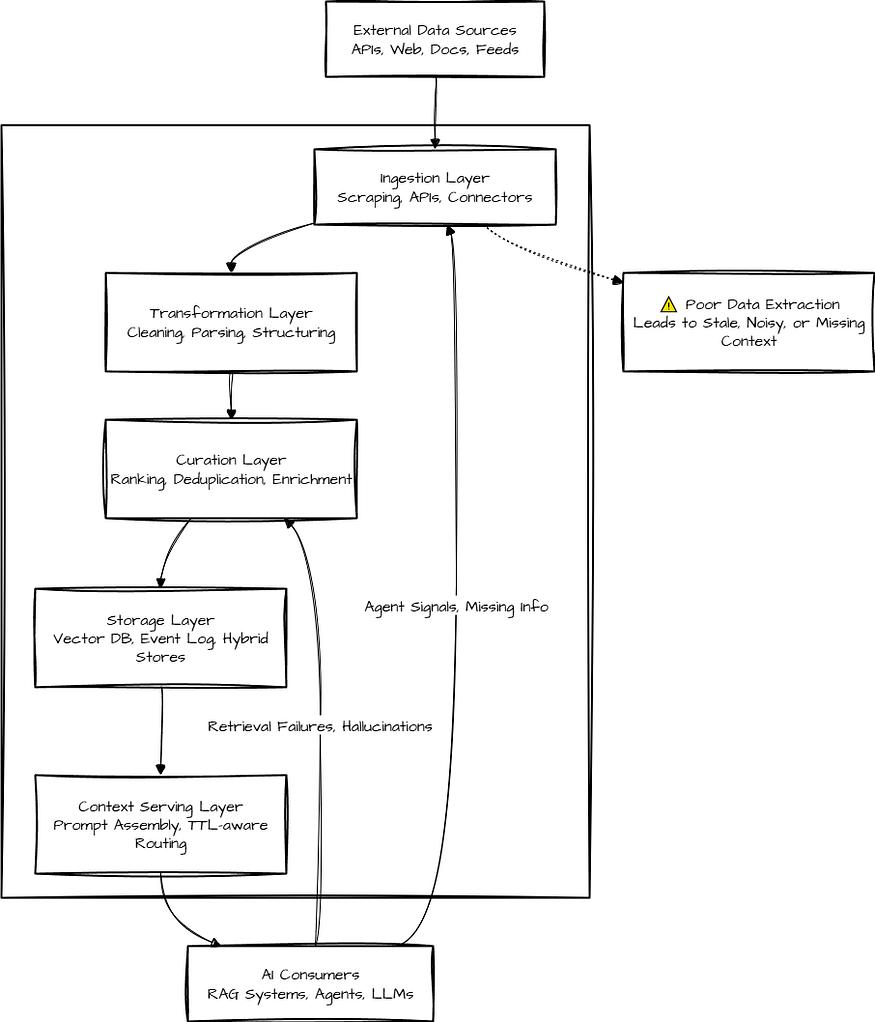
大多数团队在第一步,即采集环节就容易出错。糟糕的数据提取会破坏上下文,如果采集层错过了关键更新,在边缘情况下默默失败,或者以错误的结构或语言捕获信息,那么整个堆栈都会受到影响。
换句话说,无法设计未曾摄取的语境。有一篇有趣的论文《AI海洋中的塞壬之歌:大型语言模型中的幻觉调查》,作者是Zhang等人,该论文指出在生产级系统中,未解决的摄取问题是“模型幻觉”和其他异常代理行为的最常见根源。
因此,在RAG和代理AI时代,摄取必须具有战略性:
它必须对人工智能代理友好,能够提供结构化的、即时的数据。
它必须能够处理动态UI、CAPTCHA、变化的模式和混合提取(API + 抓取)。
多步骤AI代理既需要实时信号,也需要历史记忆,因此该基础设施必须支持定时提取、增量更新和TTL感知路由,并且具备弹性、合规性,随时准备应对变化。
它必须具有规模可靠性,能够持续从数百万个来源提供最新信息,并且符合网站条款和法律规范。
这就是脆弱的抓取工具、静态数据集和一次性连接器不再适用的原因,也是像Bright Data这样专注于自动化友好、代理优先数据基础设施的平台变得和模型本身一样重要的原因。
我见过像Gemma 3这样的开源、开放权重模型在狭窄领域中表现优于GPT - 4,仅仅是因为新鲜的、精选的、基于领域的数据让它们能够用于更好的检索系统。
我们来计算一下,假设将检索到的上下文片段的总效用定义为:U = ∑i = 1kRiFi 。其中,Ri ∈ [0,1]是第i个检索到的片段与查询的相关性得分;Fi ∈ [0,1]是新鲜度得分,以随时间衰减的函数建模(例如指数或线性);k是检索到的上下文块的数量,受模型的上下文窗口约束。
即使假设语义搜索完美,最大化U也可能意味着丢弃高度相关但过时的数据,转而选择相关性稍低但最新的信号。如果提取层跟不上,就会导致可见性损失和效用下降,并且过时内容的存在还会降低性能,导致检索到的上下文质量的复合下降。
这就是为什么数据采集(包括但不限于计划更新、TTL感知爬取、SERP提取、提要解析等)不再仅仅是管道。
数据采集基础设施的模样
那么,将数据采集视为一流的基础设施究竟意味着什么呢?
这意味着:
构建循环管道,而非负载:数据不应只是一次性抓取并存档,而应按计划进行流式传输、刷新和更新,并且内置自动化、版本控制、重试逻辑和可追溯性。一次性转储无法提供持久的智能。
将新鲜度纳入检索逻辑:数据会随着时间老化,排名和检索系统应将时间漂移视为首要信号,优先考虑能够反映当前世界状态的上下文。
使用基础设施级来源:从自制脚本中抓取原始HTML无法实现大规模扩展,需要访问层,这些层应提供SLA、对验证码的弹性、模式漂移处理、重试、代理编排和合规性支持。
跨模态采集:有价值的信号存在于PDF、仪表板、视频、表格、屏幕截图和嵌入式组件中,如果系统只能从纯HTML或Markdown中提取数据,就会错过一半的信息。
构建事件原生数据采集架构:Kafka、Redpanda、Materialize和时间序列数据库等并非只适用于后端基础设施团队,在AI原生系统中,它们将成为采集和重放时间敏感信号的神经系统。
简而言之,不要把数据视为静态资源,而要把它当成计算资源,需要进行编排、抽象、扩展和保护,这才是“数据采集即基础设施”的真正含义。
未来:信息大于规模
大多数RAG讨论都集中在模型层面,但如今兴起的AI栈中,模型可以互换,而数据基础设施才是长期的竞争优势。
摩尔定律或许已不再适用,但原始性能仍在稳步提升。在不久的将来,我不确定人工智能系统的性能是否取决于微调或快速的技巧。我认为,最终的胜利将取决于系统掌握的知识以及获取知识的速度。最智能的人工智能系统并非拥有最大窗口的系统,而是拥有最佳上下文管理能力的系统,这得益于实时数据、动态内存和智能提取。
因此,作为工程师,不应将每一个新的数据源、反馈或实时数据流视为“内容”,而应将其视为能力;每一个新的数据流也未必是噪音,而是信号。
也许你已经构建了这样一个关键的人工智能基础设施,只是还没有这样称呼它。
也许你已经开始考虑将数据(例如API)馈送到自己的内部智能层,并且意识到不需要最大的模型,只需要合适的管道。
那些将网络规模的数据采集视为基础设施而非次要任务的团队,将会行动得更快、学到更多、用更少的费用获得成功。
本文来自微信公众号“数据驱动智能”(ID:Data_0101),作者:晓晓,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com