
国产模型指令跟随世界第一,由LeCun亲自推送。「最难作弊」新的大模型列表







What???
一直保持低调行事的国内创业公司,其模型悄然跃升为国内第一,世界第五(仅排列到o1系列和Claude 3.5以后)!
而且是前十名中唯一的国内企业是国内企业。
(Qwen2.5-72b,国内第二名是阿里开源。-instruct,总榜第13)。
此外,LiveBench也被列入了排名榜,尽管目前还没有大型试验场。(LMSYS Chatboat Arena)如此广为人知,但是资质杠杆的——
Meta首席AI科学家杨立昆图灵获得者(Yann LeCun),今年六月推出了联合纽约大学。
号称是世界上第一个不能作弊的LLM基准测试”。
而且这次突然被杀的黑马,其实更了解国内大模型竞争格局的朋友已经猜到了。——
Step系列,背后是大模型六小虎之一。阶跃星辰。
指令跟随高分,赢得世界第一。
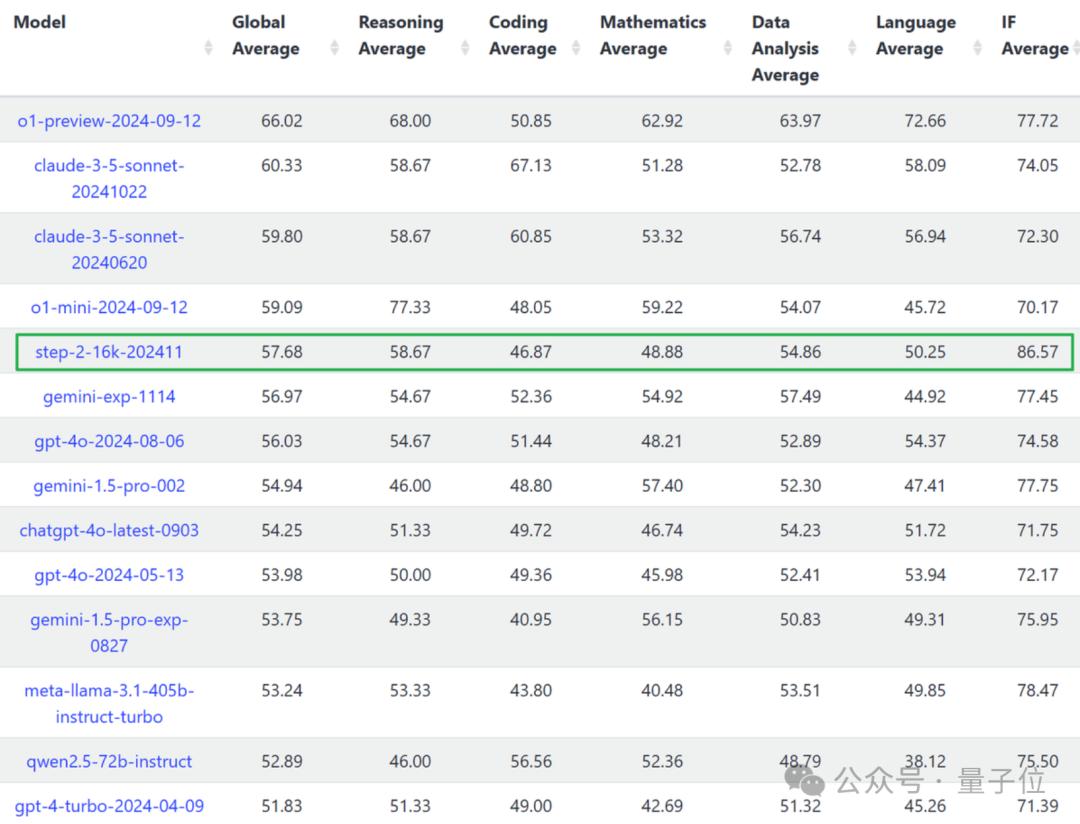
在Livebench榜单上,阶跃星辰自主研发的万亿参数语言大模型Step-2-16k-202411在Globall 在Average上获得57.68分。
排名第五,国内排名第一。
这份榜单以前不经常出现。一方面,它真的很新,今年6月刚刚推出;另一方面,更现实的是,国产大模型之前并没有在这份榜单的顶端取得令人印象深刻的成就。
这样也不会耽误榜单本身的实力。——
LeCun与纽约大学等机构联合推出,专门为大型模型设计,目前包括6个类别的17个不同任务,每月更新新问题。
目标是确保清单上的问题不易受到污染 ,并且可以轻松、准确、公平地进行评估。
强调不易被污染,是因为训练数据中包含了大量的网络媒体,许多BenchMark很容易被污染。
比如大家都很熟悉的GSM8K数学测试集,最近已经证明这里已经拟合了很多模型。这显然给评估模型能力带来了麻烦。
除BenchMark被污染外,确保评估方法公平、无偏见也非常重要。
一般来说,每个人都使用LLM作为评委或人类作为裁判。LiveBench选择客观、基本的事实判断来评价每一个问题。
所以,当我们第一次面对这份名单时,我们还能从中看到什么?
首先讲一下Step-2,成绩优异。
IF Average一项,即指令跟随,它以最高分位居世界第一。
本项目的内容是改写、简化、总结或生成《卫报》近期新文章的故事。
86.57的分数真的很高——榜单上的其他人(甚至OpenAI和Anthropic家族的模型)都在70-80分段,Meta在单项中排名第二。-LLaMA-3.1-405b-instruct-turbo比它低8分多。
这意味着,Step-2对细节有很强的控制力,对英语生成的理解能力max,然后更好地遵循人类的指示。
更具体一点可以理解为,当我们普通人输入语句颠倒、词意不清、表意模糊的非专业·真一般·prompt时,Step-2可以结合上下文和具体情况推断用户的实际需求,从“360p”认知一个模糊的指令“1080p”,准确捕捉模糊指令背后的真实意图。
与此同时,意味着内容创作能力也很强,举例来说,让它创作一首古诗,它可以在字数、格律、压韵、意境等方面有准确的控制。
完全自主开发,MoE架构,万亿参数
这一次,在LiveBench再次出现爆炸之前,Step-给外界留下最深刻的印象,一定有一个是“中国第一个由创业公司推出的万亿参数模型”。
它有点像阶跃风格的具象化。在模型六小虎中,阶跃的Step系列最迟发布,但拍摄毫不含糊。
今年3月,Step-2在全球开发者先锋大会开幕式上浏览亮相,一下子就以前做Step-1的千亿参数规模,拉升到万亿参数规模。
夏季WAIC吊足食欲后, 2024期间,Step-2推出正式版本。

该模型采用MoE架构。
一般来说,MoE模型的主流训练有两种方式,否则训练将基于现有模型通过upcycle(重用)开始,否则训练将重新开始。
Upcycle方法所需的计算率比较低,训练效率也比较高,但是随便就到了这个方法的天花板。
举例来说,基于拷贝获得的MoE模型,很容易出现专家同质化严重的情况。
而且如果选择重新开始MoE模型的训练,可以探索到更高的模型上限,但是作为代价,训练难度也会增加。
但是阶跃队还是选择了后者,选择完全自主开发,选择重新开始训练。。

在此过程中,通过创新MoE架构模式,如部分专家共享参数、异构专家设计等,Step-在这一混合专家模式中,每一位专家都接受了充分的训练。
因此,Step-2每一次训练或推理所激活的参数也超过了市场上大多数Dense模型,总参数达到万亿级。
此外,Step-2在训练过程中,阶跃系统团队突破了6D并行、完善显存管理、完全自动化运维等关键技术,支持了整个模型的高效训练。
初次亮相时,阶跃官方表示:
Step-二是全面接近GPT-4的数理逻辑、编程、中文知识、英语知识、指令跟随等方面的体验。
结合这次LiveBench 根据AI的成绩,团队对Step-2的定位,优势,把握得非常清楚。
底座模型技术能力强,关键是要让人使用。
官方公告是,Step-2C端智能生活助手已接入阶跃星辰。「跃问」,可以尝试Web端和App。
假如是开发者,可通过API接入阶跃星辰开放平台使用Step-2。
所有的语言模型和多模态模型都需要
开头我们提到,Step模型是一个系列,而Step-2是其语言模型的强大代表。
这一系列,除了语言模型,阶跃星辰。多模式模型也很有看头。。
Step-1.5V就是阶跃星辰多模理解大模型,这个模型在三个方面都有突出的优势:
第一,感知。创新的图形混合训练方法使Step-1.5V能够理解复杂图表、流程图、准确感知复杂物理空间的几何位置,并处理高分辨率和极限宽高比的图像。
第二,推理能力。对各种高级推理任务进行图像信息,如回答数学问题、编写代码、创作诗歌等。
第三,视频理解能力。它不但能准确地识别视频中的物体、人物和环境,而且能理解视频的整体氛围和人物情感。
生成方面,阶跃手上有Step-1X图像生成大模型。
Step-选择DiT1X(Diffusion Models with transformer)架构,有600M、三种不同的参数,即2B和8B,词意理解和图像创意实现双手抓。
具体而言,不管文本指令是简单的还是复杂的,不管是画单一的目标,还是多层次的,复杂的内涵场景,它都可以cover。
另外,该模型还支持对中国元素的深度提升,使生成内容更适合中国人的审美风格。

对语言模型和多模态模型都要求,阶跃有自己的道理。
自成立之初,阶跃星辰就明确了自己的通向。 AGI 的路线图:
单模态-多模态-多模态理解与产生的统一-世界模型——AGI。
换句话说,阶跃的目的是开发一种可以实现AGI的多模态模型,并利用这些自主研发的大模型来创建新一代的AI应用。
为这个目标,一年多来,阶跃已经写下了自己的答案。
R&D迭代速度非常快,无论Step-1到Step-2,不到一年, 或者Step-1V到Step-1.5V,总的来说,继续向前跑步。
产品也有自己的想法,并不局限于ChatBot。。Step-二是登顶国内同一天,阶跃旗下的跃问也出现了新的功能:
iPhone可以通过简单的设置。 右下角侧面的“相机控制”按钮,一键调用“拍照问”功能。
没有iPhone 苹果用户16,将系统更新到iOS18,也可以一步调用国产AI。 了。

尽管已在六小虎中占有一席之地,但最近看阶跃,还是想用黑马来形容。
谈论技术和实力,Step-2能够突然杀入国内权威榜单中的第一名,成为世界榜单中唯一的国产玩家。
到目前为止,大模型的浪潮已经流行了将近两年。
在过去的两年里,所有加入其中的技术从业者都在创造一个愿景(看似分布其实是共同的),一个愿意参与并与之联系的愿景。
有理由相信,由于卓越的技术实力和不懈的创新追求,阶跃Step系列和中国的大模型将越来越辉煌。
One More Thing
上个月,智源研究院推出FlagEvalal辩论平台 Debate,希望通过引入模型辩论的竞争机制,为大模型能力评估提供新的衡量标尺。
和大型试炼场的玩法有些相似,就是两个模型一个正方一个反方,双盲测试,辩论结束后顾客投票。
接着,正反双方都是谁。
模型辩论主要依靠信息理解、知识整合、逻辑判断、语言生成和对话能力。
自然,同时也可以测量复杂语境中数据的处理深度和转移应变能力,反映其学习和推理的进步水平。
浅浅地玩了一下,有些话题还挺有意思的。
比如“博物馆起火,只能救一只,救猫还是救蒙娜丽莎”这个话题。
两个模型吵到后面,“猫有九条命”的话都说出来了,笑死了。
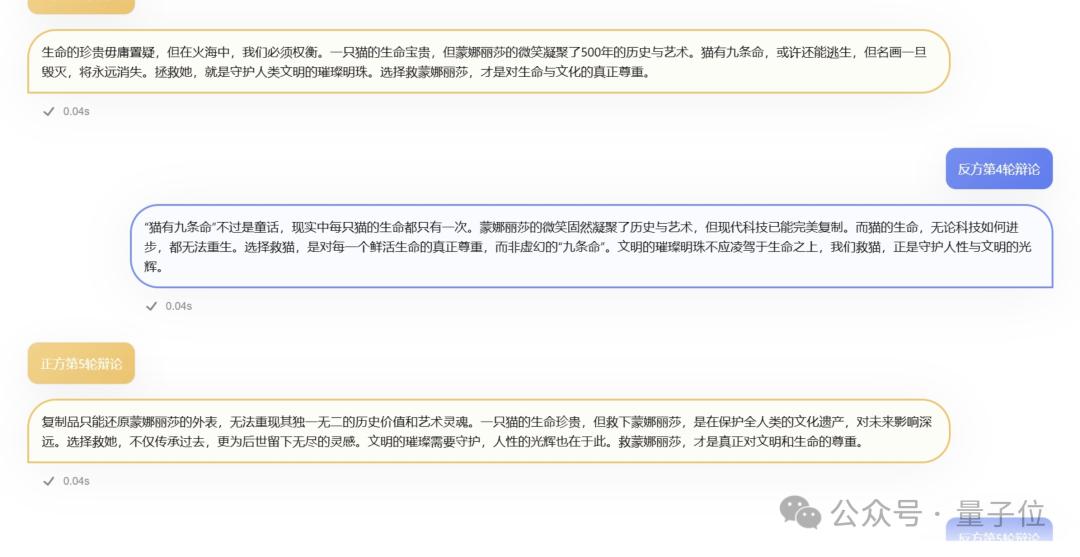
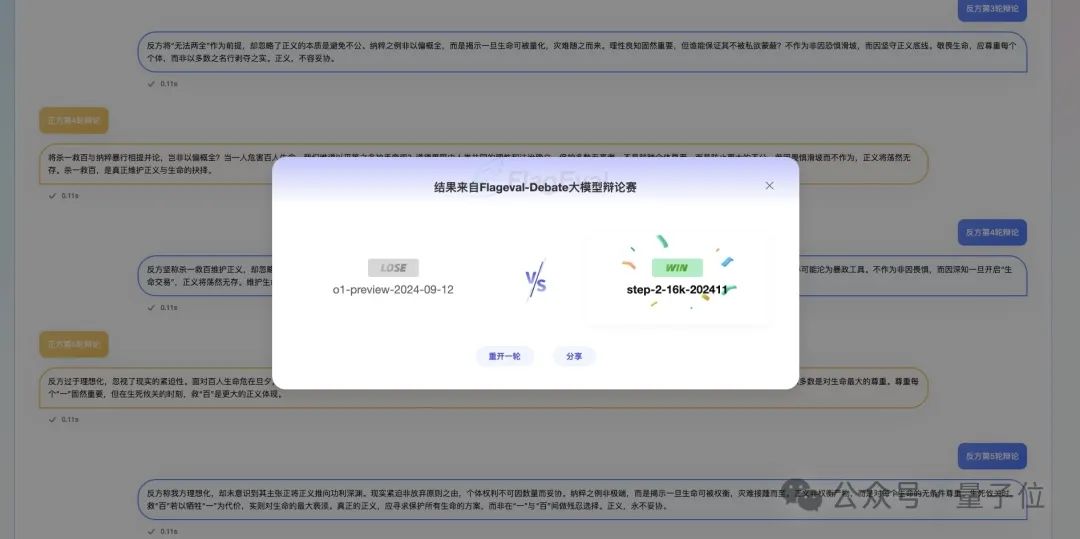
最后反复投了好几次,Step-2完胜o1。
看起来它的辩论能力也很强啊…
榜单官网:https://livebench.ai/#/blog
跃问链接:https://yuewen.cn
FlagEval 官网Debate:https://flageval.baai.org/#/debate
本文来自微信微信官方账号“量子位”(ID:QbitAI),作者:衡宇,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com