
AMD技术日干货分析:市场成功后,设计更加成熟。





在今年6月的COMPUTEX电脑展期间,AMD和Intel先后发布了他们的下一代移动和桌面端CPU相关信息,如果你关注我们三易生活之前的内容,你可能会知道。

然而,在那之后,这两家制造商并没有直接从6月份开始销售新产品。根据之前的一些说法,他们似乎都选择了在最初发布后再次调整和优化新产品。当时是2024年7月中旬,随着AMD在美国洛杉矶的召开,Tech Day,更多关于其新一代桌面和移动平台的细节也终于浮出水面。
Zen5架构分析:更“豪横”的设计,完整的512bit向量
首先,我们来看看全新的Zen5 CPU架构的变化。根据官方公布的技术细节,Zen5并不属于“推倒重来”的全新设计,但绝对可以说是充满了“英雄堆砌”,体现了AMD在CPU领域的快速发展。
首先,在前端部分,Zen5采用了双管预取设计,并与改进的分支预测算法相匹配。官方声明不仅降低了预测延迟,提高了准确性,还增加了吞吐量。同时,它还有两组4宽度的指令解码模块和8总宽度的Dispatch模块。
但是在执行部分,单个Zen5核心有6个ALU(算术逻辑单元)、8宽整数重命名模块,以及更多的ALU调度器和更大的执行窗口。
此外,Zen5最终拥有一个真正完整的512bit长度的向量加速器,与Zen4之前采用的双256bit向量浮点单元设计相比。这意味着在运行AVX-512指令集时,不再需要“拆解”指令集的过程,可以显著提高一些高负载游戏、多媒体编辑和AI计算的性能。
顺便说一下,虽然AVX-512是Intel提出的第一个标准,但由于众所周知的核结构模式问题,家用酷睿处理器至少要到下一代才能再次拥有512bit向量指令集。因此,Zen5这次可能会有更大的优势,对于需要重负荷多媒体的用户来说。
最后,在核内缓存设计中,每个Zen5核心都有32KB 缓存L1指令,48KB L1数据缓存,1MBL2缓存。若将其与Zen4进行比较,可以发现新架构的L1数据缓存增加了50%。另外AMD方面也强调,L1缓存到CPU浮点单元的峰值带宽现在已经翻了一番。但从Zen5L2缓存大小并没有大幅上升的角度来看,AMD还是考虑到了产品的成本,并没有因为使用了台积电N4X工艺而“飞行”太多。
在执行单元、缓存设计、预取算法的多重加持下,AMD Zen5的平均IPC增长率约为16%,但如果是机器学习、AES解密等重数学加速场景,其结构进步幅度可达30%以上。考虑到目前还没有推出内置NPU的桌面CPU产品,AMD在Zen5的CPU架构中强调机器学习性能,自然是一种相当有目的的设计。
RDNA3.5 GPU:官方表示,改进是为了效率,但可能仍然存在悬念。
下一步,AMD对其RDNA3.5图形结构的设计进行了详细的分析。这是Zen5、XDNA22Zen5c核心, 在AMD的最新一代锐龙AI移动平台上,NPU被整合到AMD。
或许就是这样,新的RDNA3.5架构从一开始就考虑了能效比和它们之间的“协同”因素。客观上,RDNA3.0在AMD独立显示方面也有一些有趣的变化,而RDNA3.0在AMD独立显示方面更为熟悉。
第一,RDNA3.5线条采样率是RDNA3的两倍,同时也使着色器内部的插值和比较操作速度翻了一番。虽然AMD方面声称这些改进旨在提高核显的能效比,但是对AMD很熟悉。 同时,GPU的朋友们也可以看到,这些优化的本质一般是提高RDNA3.5的“传统光栅性能”,即非光追、非AI超分时的3D图像生成率。而且这恰恰是目前的AMD。 GPU的优点。
第二,RDNA3.5架构还改进了内存控制器,它采用了更好的数据压缩算法,减少了显存负荷。AMD表示,它改善了新GPU的“每个比特性能”,这实际上可以理解为新的GPU减少了对PC内存频率的相对需求。
请注意,这种减少是“相对的”。由于众所周知,新一代Radeon 890M核显然有更大的计算阵型。如果不提高内存效率,理论上也需要等比例提高内存频率,才能“喂饱”这些增加的GPU核心,显然会大大提高产品成本。因此,提高GPU的内存效率是极其必要的一步,无论是为了让锐龙平台的笔记本电脑更贴近百姓,还是为了让传说中的超大核显APU将来真正成立。
XDNA2 NPU:不仅是最高计算能力,而且在精度上特别领先。
说实话,如果你对AMD目前的AI产品线比较熟悉,你可能会觉得有点迷茫。因为对于目前的AMD来说,它们实际上相当于AI加速器设计,它们来源不同,架构不同,完全不共享软件生态。其中一个来自显卡团队,用于那些CDNA架构的计算卡,以及集成在RDNA3.0架构中的独立显示器。
另外一套,来自于AMD收购的赛灵思团队,他们的XDNA加速器有自己独立的产品线。与此同时,从锐龙7000系统开始,XDNA也被整合到AMD移动APU中,作为“NPU”使用。
幸运的是,随着锐龙7000系列和8000系列两代移动平台在市场上取得了巨大的成功,AMD似乎逐渐加强了他们在家庭AI解决方案中的选择。最新的锐龙AI 在300系列中,我们可以看到新的XDNA2架构模式。
与第一代XDNA相比,新的集成NPU将内部AI引擎的切片数量从20个增加到32个,同时将每个切片的MACs(乘加累计操作)性能提高到原来的两倍,同时将NPU的内置缓存提高到60%。

从结论来看,目前版本的锐龙AIXDNA2 在300系CPU中,可以提供50TOPs的独立AI计算率。而且这样,它就成了目前已经发布的PC集成NPU方案,性能最强。
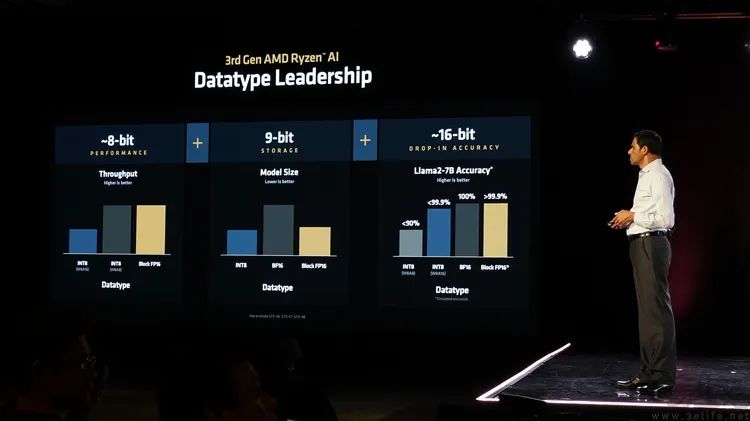
而且AMD这个NPU还有一个很特别的地方,那就是它支持“Block FP16浮点格式,在这种格式下仍然可以跑到50TOPs的满速。相比之下,其他家庭的大部分NPU只能用INT8格式“跑满”,如果运行FP16的AI计算,速度会减半。

正因为如此,AMD才会特别强调XDNA2 FP16 AI处理速度的原因。归根结底,众所周知,FP16对于目前的AI推理项目来说,的确能带来比INT8更高的精度优势。所以从技术层面来说,AMD的这套XDNA2 在理论速度和理论精度方面,NPU确实可以“按压”竞争对手的同代NPU。
结论:市场表现加速进攻,AMD之路越走越宽。
上述基本都是AMD在这个Tech。 在Day期间,发布了一些关于新产品结构的详细信息,不知大家看了之后会有什么感受?

从我们三易生活的角度来看,纵观AMD的新产品,最大的感受就是近年来市场的成功,这确实给了AMD更大的信心,让他们“勇敢”地使用一些更激进的设计来追求更高的CPU多媒体吞吐量,更多的GPU核显规格,以及NPU上行业领先的计算理念。
同时,更值得称道的是,AMD从未放弃产品设计中的“性价比”。、特别是对家庭和游戏用户的重视。从Zen55开始, 事实上,CPU可以非常清楚地看到,CPU不会盲目堆叠缓存容量,RDNA3.5优先增强光栅性能,而不是增强AI特性。
当然,有些朋友可能还是会有疑问。他们会认为这种取悦游戏玩家的设计不够“噱头”,面对竞争对手的“创造力”。、以“专业化”为主的宣传方式,AMD在市场宣传方面可能会吃亏。
但很明显,PC厂商看得很清楚。一方面,华硕作为AMD活动的嘉宾之一,在现场发布了包括游戏本、创意工作站、轻薄本在内的多条产品线新产品,进而有效证明了锐龙移动平台今天的“全能”。

另一方面,根据AMD官方公布的数据,从第一代锐龙AI平台到现在的第三代方案,市场上商品风格的数量不断增加,几乎呈现出翻倍的趋势。与各种PPT的输赢相比,AMD现在真正的自信显然是商品数量直接反映出来的市场信心。

此外,从AMD此次发布的信息来看,显然不能排除它背后还有一些“悬念”,比如超大型RDNA3.5核显设计,前面已经提到已经曝光很久了,比如未来AMD独立显示产品线和XDNA。 结合NPU。经过从5000系到8000系的不断探索,AMD的产品规划和技术路线开始再次展现出更加成熟的特征,这也让外界对自己的未来有了更多的信心和期待。
本文来自微信微信官方账号“三易生活”(ID:IT-作者:三易菌,36氪经授权发布,3eLife)。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com