
开源与闭源争论的背后,是大模型未来商业生态演进的严肃思考。





"开源模型将越来越落后."Create 百度创始人、董事长兼首席执行官李彦宏在2024百度AI开发者大会上的这句话,以及在大会上发布的PPT,在网上广为人知,引发了科技界关于大模型开源vs闭源的争论。
关于大模型是否要开源的系统性讨论,以及李彦宏发表的一些关于大模型开源的观点:
"开源模型已经很多了,不缺百度一家。"
「以前大家都觉得开源便宜,其实在模型场景中,开源是最贵的。」
而且模型开源也不是一个人心齐泰山移的情况。像Linuxx这样的传统软件开源、安卓之类的很不一样,因为是模型带来的开源,不知道为什么参数会变成那样。在这种情况下,很难实现齐泰山的移动。虽然Llama也鼓励每个人提供各种各样的数据和代码,但事实上,每个人都知道Meta是最重要的开发者,它并不是真正由每个人共同开发的产品。”
360创始人周鸿祎一直是开源教徒。巧合的是,他在4月13日在哈佛发表了一篇演讲,他还在演讲中提到了“没有开源就没有Linux、PHP、MySQL甚至互联网”的态度。如果当时没有谷歌开源Transformer,就不会有OpenAI和GPT,包括人工智能的发展。由于开源的发展,我们都是个人和企业。”
网民猜测周鸿祎正在“暗杀”李彦宏。4月20日后,周鸿祎再次发文澄清,“这两天有人挑事,说我攻击李厂长,我不是为了李厂长,我还是从产业发展的角度来看开源和闭源。”
事实上,两家科技企业的创始人关于大型开源vs闭源的争论,关于复杂系统的争论,不是简单的开源好,也不是关于闭源好的二元论,涉及多个问题:
① 开源模型能力在模型领域是否总是落后于闭源模型能力?
② 开源模型,有没有可能出现商业化的闭环?
③ 在真正使用大型模型时,究竟是开源还是闭源性价比更高?
④ 从科技发展的角度来看,大模型的开源和传统的开源有什么区别?
开源不仅仅是开源代码那么简单
开源(Open Source)它的起源可以追溯到计算机技术的早期阶段。当时软硬件就像一对连体婴儿,客户经常要自己编写或修改软件来解决问题。到了1955年,IBM做了一个“IBM用户组分享”,让大家深入研究他们的操作系统。
在70年代中期,随着计算机技术的发展,软件已经成为一种商品,而不是与硬件一起免费提供。软件共享文化开始受到这些变化的限制。为反对这一趋势,自由软件运动(Free Software Movement)开始兴起,Richard 1983年,Stallman推出了GNU项目,并于1985年创立了自由软件基金会。(Free Software Foundation, FSF),促进自由软件的发展。
1998年,Eric Raymond和Bruce Perens建立了开源促进会议(Open Source Initiative, OSI),并提出了“开源定义”(Open Source Definition),它是开源软件的正式定义。OSI旨在推广开源软件,并为开源项目提供认证。
根据开源促进会的说法,开源软件不仅要公开源代码,还要满足一些条件,比如允许大家自由使用、更改和共享这个软件,甚至基于它创造新的物品。然而,开源软件并不是什么都不在乎。就像我们经常听到的GPL一样,它必须在某些开源许可证下发布。、Apache、这些许可证,BSD和MIT。
为什么周鸿祎会特别提到没有开源就没有Linux?、PHP、与MySQL,这三者与开源的关系是什么?这与当前的科技产业有什么关系?
●Linux:Linux是一个由Linusus开源的操作系统核心。 1991年,Torvalds首次发布。 L inux核心是包括Android和大多数服务器操作系统在内的许多现代操作系统的基础。 开发Linux的方法——开放源代码,社区驱动,合作开发——成为开源软件运动的代表性案例。
●Apache HTTP Server:处理HTTP请求并提供Web页面的强大Web服务器软件。Apache HTTP Server是互联网上最常用的Web服务器之一,因其性能和可配置性而受到青睐。
●PHP:PHP是一种开源服务器端开发语言,尤其适用于Web开发,是建立动态网站和Web应用的常用工具。PHP的开源特性使开发者能够自由地使用、修改和改进其功能,从而促进了Web开发技术的发展。
●MySQL:MySQL是一种流行的开源关系数据库管理系统。(RDBMS),数据存储广泛应用于网站和在线应用。MySQL的开源特性使其能被社区广泛使用和定制,成为许多网站和网络应用后端的关键组成部分。
它们共同构成了所谓的LAMP。(Linux, Apache, MySQL, PHP/Python/Perl)堆栈的一部分,是建立动态网站和网络应用的常用技术组合。作为操作系统,Linux,Apache作为Web服务器,MySQL作为数据库,而PHP(或Python或Perl等其它语言)作为开发语言,共同支持网络上的大量网站和应用。
流行的语言解释是,LAMP就像一个团队,里面有打桩的Linux,招待用户的Apache,管理数据的MySQL,以及PHP(或Python)。、Perl)。这支团队合作无间,算是因特网世界的基础。
除了这些技术的发展和普及,开源还为全球开发者社区提供了一个共享知识、合作和创新的平台。通过开源代码,这些项目可以快速迭代,汇聚全球开发者的智慧,形成强大的生态系统,促进整个软件行业的进步。
到了大模型时代,开源变了吗?
那么,在大模型时代,开源有什么区别吗?在早期的软件时代,开源一般是由个人和小团队推动的,关键是共享代码与合作解决问题。开源项目一般由爱好者和志愿者社区维护,商业化程度较低。例如,Linux操作系统的诞生和GNU项目的推广都是这一时期开源生态的代表。
伴随着因特网的兴起,开源生态开始加速发展,开源项目开始得到更广泛的认可和应用,比如上面提到的LAMP,它们已经成为构建网站和网络应用的基石。另外,开源也开始与商业模式相结合,例如通过提供技术服务和支持来获利。
在云计算时代,OpenStack和Docker等云服务提供商开始大量采用和贡献开源技术,这些技术已经成为云计算基础设施的重要组成部分。开源软件开始与云服务紧密结合,提供更灵活、更可扩展的解决方案。与此同时,云服务提供商通过提供基于开源软件的云服务来创造AWS等商业价值、Azure等等。
在一定程度上,大模型的技术浪潮也是由开源开启的,谷歌开源了Transformer,之后OpenAI点爆行业就有了ChatGPT。
图片:大语言模型进化树。
但是OpenAI不再是Open,谷歌也不再是Open,大型开源旗帜,而是由于其Llama系列模型,Meta将马斯克开源Grok模型,位于法国巴黎的Mistral。 AI,成为另外两个最受关注的大模型开源力量。
然而,在Llama2刚刚发布之后不久,就有人指责Llama2不符合开源促进会。(OSI)Llama2的许可证包含了一定的限制,例如,禁止使用Llama2来训练其他语言模型,如果该模型用于每月超过7亿客户的应用程序和服务,则需要获得Meta的独特许可证。
大型时代的开源,也变得更加复杂。
第一种是开源方式,仅从Llama系列模型和Mistral系列模型来看,它们的开源方式就不一样。一位熟悉开源生态的专家指出,它们之间的主要区别在于Restrict License(限制许可)VS Apache。Llama的开源属于前者,从前面描述的Llama2的限制模式可以看出,这种开源模式是指在开放源代码的同时,对该模型的使用、修改和分发给予一定的限制。
MIT等完全开放的开源许可证(例如、Apache 不同的是,后者一般用户可以在几乎没有限制的情况下使用和修改软件,而Mistral、谷歌的开源模型Gemma采用了这种方法,不仅开源了模型的权重,也开源了模型的结构。但是训练数据和训练过程不是开源的。
除了不同的开源方式,训练一个大模型通常需要大量的数据、计算资源和专业知识来实践和优化,这些资源往往只能由大型科技公司或科研机构提供。因此,大模型时代的开源主体通常是大型科技公司,或者是资源优势较强的创业公司,而不是个人;这也导致开源可能会吸引更广泛的社区参与,但由于技术门槛和资源需求,实际贡献可能集中在有限的专家中;一些大公司的开源也考虑到了竞争生态,所以开源条款的设计会更加复杂。
这一变化与文章开头提到的李彦宏的观点相呼应,“模型开源并非一个人心齐泰山移的局面。它就像Linuxx、Android和其他传统软件的开源非常不同,因为它们是模型带来的开源,我们不知道为什么参数会变成这样。虽然Llama也鼓励每个人提供各种数据和代码,但事实上,每个人都知道Meta是最重要的开发者。这并非真正由每个人共同开发的产品。”
然而,大模型的生态才刚刚萌芽。从目前的角度来看,少数能获得有限资源的人确实促进了大部分的技术进步。然而,随着计算率资源成本的降低和门槛的降低,目前还不可能得出“人心齐泰山移”的结论。
然而,大模型的生态发展会如何演变?与开源历史相比,会有哪些不同的特征?这是一个值得科技界长期关注和深入探讨的问题。
根据Benchmark,对比开源闭源模型的能力。
基于大模型开源生态的演变,还有一个讨论焦点,“开源大模型的能力,真的会越来越落后吗?”
Llama3,被称为最强开源模型,于4月19日发布,拥有8B和70B版本,并预测大版本的超过4000亿参数模型也将在晚些时候发布。Llama 3 最先进的性能体现在多个性能标准上,提供了包括优化推理能力在内的新功能。
就Benchmark而言,只有70B的Llamamark 根据推测参数为175B的Gemininini在各项指标上已经可以和 Pro1.5联合Claude 数据显示,70BLlama3即使对抗GPT4,在各种benchmark中也已经非常接近了。这种情况仍然是在Llama3没有进行微调的情况下完成的,这表明它在后续还有很大的改进空间。
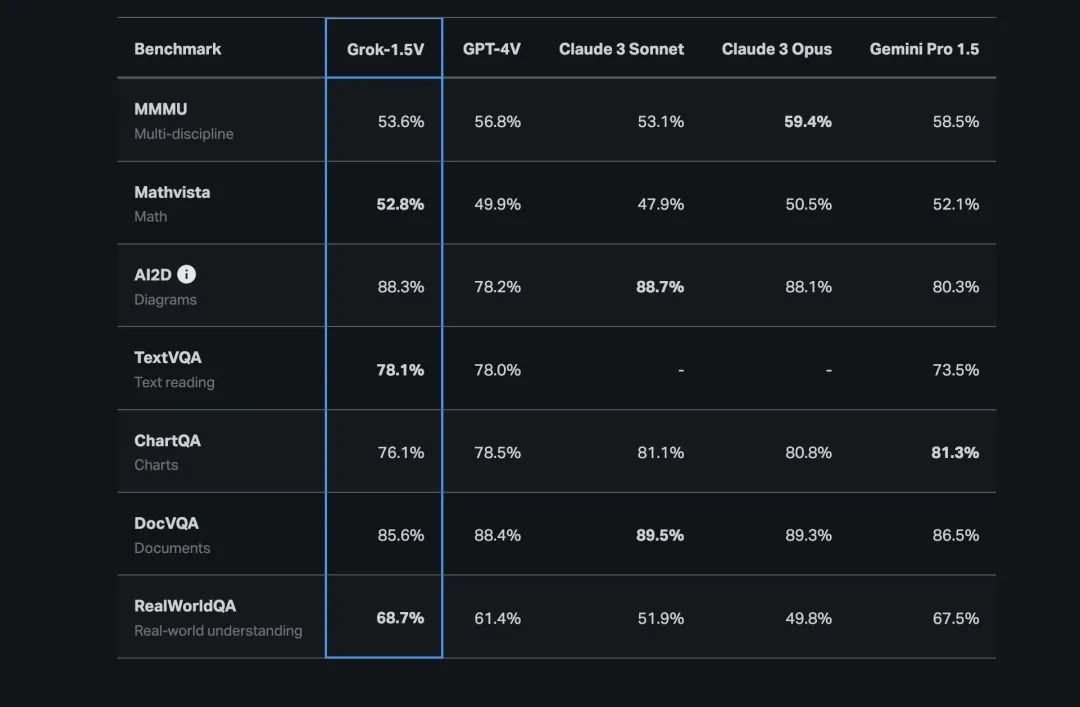
同样,Mistreal,开源界的另外两大巨头。 和 Grok最近发布的模型也显示出与GPT-4“同代”的水平。Grok1.5V具有多模态能力,各项指标与GPT4不相上下。Mistreal最近基于Llama2训练的Miqu 根据EQbenchmark的测试,70B模型也与GPT4相似。
2023年,国外媒体报道谷歌曾以“主题”为主题,流出一份文件。我们没有『环城河』,OpenAI 没有。在我们还在争吵的时候,第三方已经悄悄地抢走了我们的饭碗——开源。”
根据这份文件,一些开源模型和闭源模型之间的差距正在以惊人的速度缩小。开源模型更快,可定制性更强,更私密,功能性不落后。“几乎每个人都可以根据自己的想法微调模型,然后一天内的训练周期就会变得正常。以这种速度,微调的积累效应将迅速帮助小模型克服规模上的劣势。”
就连谷歌也不得不面对这样的问题。开源模型在能力上不断接近闭源模型,而在商业上,它也在侵蚀和威胁闭源模型。
从技术发展的历史规律来看。技术发展的曲线必然会经历从危险到放缓的时期,这意味着即使领导者一开始“遥遥领先”,后来者也会逐渐赶上,与领导者的差距也会逐渐缩短。
和Llama3一起发布的一次采访,以及扎克伯格,他对Scaling的大模型进行了采访。 law有一个悲观的态度,他认为从现在开始,进步将是渐进的。2025年之前,不会有通用人工智能。(AGI)出现。
也就是说,大型技术的迭代速度可能会变慢,开源也会变慢吗?开源与闭源的差距,会缩小吗?
开源还是闭源,究竟怎样选择?
选择开源还是闭源?对企业客户而言,最优先的问题只有一个,哪一个性价比更高?
在一次公开演讲中,清华大学汪玉教授给出了使用GPT系列模型的推理费用,如图所示:
假设GPT-44采用闭源模型进行API操作, Turbo每天为10亿活跃用户提供服务,每年的计算费用可能超过2000亿。目前很多公司的收入规模都在1亿。即使用户数量没有那么大,计算能力的成本也很难支撑自己的业务,最终形成盈利的商业闭环。
但是如果使用GPT3.5,推理价格将大大降低。为了打压竞争对手,OpenAI将GPT3.5的定价定得非常便宜,100万token只需要1美元,而Llama2则与其相对应。 在许多情况下,70B模型使用快速API,价格为1美元/100万token甚至更高。Mixtral-与OpenAI相比,8x7b的价格也是0.7美元/100万token,价格优势有限。当然,开源模型也有本地部署的优点。在本地运营的情况下,其成本只有硬件成本和电费,这绝对是有云服务水平或硬件基础的大公司最经济的选择。但并非每个人都有这样的基础。
对初创企业而言,要做个性化应用,首先要有自己专有的微调模式。这个问题涉及到微调训练的费用。如果Llama22在开源模型上进行相应的练习和微调, 优势显而易见。Anyscale云服务商 在提供的价格中,70b版只需要4美元/100万token。GPT3.5则比整整贵一倍,要8美元/100万token。因此,当你想要真正为自己的业务建立一个特殊的模型时,从成本的角度来看,开源模型仍然具有一定的优势。

在降低成本方面,创业公司可以进一步细化。许多企业选择混合各种模型。虽然通用大模型性能优异,但在实际应用中,使用中小型开源模型,并用特定数据进行微调,最终效果可能会更好。
若采用闭源模型,100万token的消耗速度非常快,每小时的成本远远高于0.6美元。在一次闭门活动中,LeptonAI创始人贾扬清分享说:在北美,许多企业首先使用闭源模型进行测试(例如OpenAI模型)。测试规模约为数百个million(百万token),费用约为数千美元。数据飞轮一旦运转,再保存现有数据,用较小的开源模型对自己的模型进行微调。如今,这已成为一种比较标准的方式。
国内另一家使用大模型建设业务的公司的相关负责人也表示,“企业级应用不太可能使用单一模型,现在已经开始按照应用目的进行分模,但跨系统调度的带宽成本更高。因此,在一个系统中,高、中、低(参数)模型混合的方法是企业应用当今合理的方案。”
开源和闭源不是公司考虑的核心因素。最好的性价比和公司的数据安全可以促进企业未来战略的发展,这可能是选择的优先事项。
开源闭源之争,到底是什么争论?
之所以如此关注李彦宏的开源观,是因为目前各企业都在探索如何在模型时代找到PMF。(Product Market Fit)。
对公有大模型生态的规划,百度比较早,对百度来说,模型本身就是商品。
根据媒体消息,金沙江创投主管合伙人朱啸虎在业界微信群中表示:“GPT-能够满足90%以上的商业需求并不重要。之后大型API就是自来水的价格。但用户需要的是纯净水、气泡水和乌龙……”
纯净水、泡泡水、乌龙茶是针对客户多样化需求的多样化产品形态思维。
新闻发布会第二天,贾扬清在朋友圈发表了一个观点,“我认为Robin是非常正确的。经过最初的应用尝试,模型特化将在效果和性价比方面更加makee。 选择sense。“一般大众的关注点可能是李彦宏在新闻发布会上说的对不对。业内人士其实关注的是,在开源闭源争论的背后,以模型为产品的公司如何打造商业闭环,未来的增长空间在哪里。通过平台化商品,实现模型的特殊部署,从培训到商业化,再到模型迭代再培训,实现最高效率和最佳性价比。”

开源模型的龙头企业,比如Meta,提供更原始的技术创新,没有包装。他们有强大的计算率资源、R&D部门和经济实力,可以通过技术知名度实现生态布局。最终可能不是产品本身带来商业价值,而是更多的技术服务费用和咨询费用来源于生态。
在接受扎克伯格采访时说,假如模型本来就是商品, Meta将考虑停止开源。,也许模型最终更像是产品本身。在这个时候,我认为是否开源是一个更加棘手的经济考虑。
坚持Scaling law的闭源模型面临着一个难以解决的矛盾,一方面,scaling law(规模法则)的道路还没有走到最后,巨额投资还会继续,技术的秘密无法公开;另一方面,免费、优质、性价比高的开源模式给持续烧钱的闭源模型带来了巨大的压力。
最近,OpenAI在压力下改变了API付费模式,从先用后付,改为pre。-paid。对于OpenAI来说,这种模式降低了坏账率,增加了资金周转的速度,在某些方面可以稍微减轻资金压力。但对于应用API的企业来说,按照之前最长60天左右的账期,相当于公司增加了60天的资金占用成本。OpenAI变相涨价。
在这一定价策略推出后不久,Llama3发布了中小型版本。一个可以类似于GPT-4,提高性能,在小计算率硬件下运行模型,甚至直接给闭源模型带来一堆竞争对手。
优秀的大规模开源模型为其他科研机构和目标更宏伟的商业机构提供了更好的技术参考路径,可能会大大提高科研效率,缩短到达目标的时间。中小型模型确实是商业闭源模型的竞争对手。
企业看到了基于开源的中小型模型,自己拥有私人模型,保证数据安全,建立应用,上下游通吃,完成自我闭环的希望。
事实上,所有这些链条都可以在模型公司的平台上一站式完成,这部分市场实际上被开源模型“无意”侵占了很多。
从竞争的角度来看,如果Meta采用闭源策略,OpenAI可能永远无法在同一条跑道上颠覆成为领导者,而另辟蹊径的开源策略,使Meta抢到了大型开源模型的头把交椅,暂时占据了另一个生态王座。而且快速开源Grok模型马斯克,也许暂时只是想给“Closed AI”和Sam 另一个竞争者是Altman制造的...

开源与闭源之争的另一个焦点人物是“开源的坚决支持者”周鸿祎。 事实上,周鸿祎和李彦宏,两人根本没有对立的看法。 “我们要善用开源,利用开源,通过开源学习,快速提升人工智能的核心能力,”周鸿祎主要是从行业发展的宏观方向来看。 ”他还补充了自己的想法,开源和闭源是两种不同的商业模式,没有必要互相抵制。 Android和iOS,Linux和Windows都是一个开源和一个闭源,他们都过得很好。 ”
从商业角度来看,360不是模型公司,模型也不是360的主要产品,这与百度有本质区别。目前,基于模型的AI浏览器和AI办公家庭水桶已经推出。开源生态越繁荣,企业的选择就越多。
还有一些企业选择了既开源又闭源的一体式两翼方式,以开源切入大型赛道的百川智能,在发布Baichuan-7B之后,、Baichuan-在13B开源大模型之后,Baichuan-53B闭源大模型被拿出来。在Baichuan-53B新闻发布会的媒体交流会上,王小川被问及为什么没有继续开源。他回答说:“模型增加后,没有这样的开源方式,因为每个人的安排成本都会很高,所以我们可以使用闭源方式在网上调用API”。
"1.关于开闭源之争,核心是看谁在开源。集成两翼,是一线AGI创业公司唯一的解决办法。”据第一财经报道,百川智能CEO王小川在行业微信群讨论中发表了上述观点。“从To来看,王小川感觉,” 从B的角度来看,开源闭源实际上是需要的。未来80%的公司将使用大型开源模型。因为闭源不能更好的适应产品,或者成本很高,闭源可以给剩下的。 提供服务的20%。两者并非竞争关系,而是不同产品之间的互补关系。”
开源与闭源,本来不是单选题,而是综合应用题。如果你有足够的资源和决心,你可以通过开源显示技术水平,获得更多的技术和数据反馈,创建开源生态。它还通过强大的闭源模型将其包装成产品,直接实现商业化。
王小川还认为,与手机中的iOS或安卓操作系统不同,开源和闭源只能从两者中选择。开源真的很容易“建立人品”和“朋友多”,让大家快速了解和评价大模型的质量。同时,开源也是为商业化做准备。如果用起来感觉不错,可以在需要更好的服务和更多的参数的时候探索进一步的商业化路径。
在开源与闭源的争论背后,实际上是科技企业在模型时代开始认真思考的生态演变过程。
大型生态发展到底会如何演变?大型时代的开源,又会呈现出什么不同的特征?
本文来自微信微信官方账号“腾讯科技”(ID:qqtech),作者:郭晓静郝博阳,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com