
全球两大核心AI监管规则同步落地 行业发展迎来明确新方向






本文来自微信公众号:格隆,作者:城北徐公
站在未来回望AI发展历程,2026年5月3日注定会被记入行业史册:
欧盟正式版《人工智能法案》、中国《生成式人工智能服务管理暂行办法(伦理审查修订版)》在同一天正式对外公布。
全球两大核心经济体不约而同对快速发展的AI行业立下明确规则,给此前野蛮生长的行业套上了清晰的规范框架。
两份规则的核心监管思路,相似度极高。
01
两份监管文件的监管逻辑,在三个核心方向高度统一。
1.明确禁止性应用边界
禁止使用AI对个人进行社会信用、道德层面的打分,并以此为依据限制个人贷款、出行公共服务等权益。
类似《黑镜》中评分过低就被社会排斥的场景,直接从规则层面被杜绝。
禁止深度伪造技术被滥用。
比如2024年美国大选时,新罕布什尔州选民接到AI合成的拜登语音,劝说选民放弃投票的事件,放在现在就属于明确违规行为。
在没有明确标注且获得授权的情况下,使用AI换脸、语音合成实施诈骗、操纵政治、抹黑他人,都属于严重违规违法行为。
同时禁止AI批量生成虚假信息,制造假新闻误导公众。

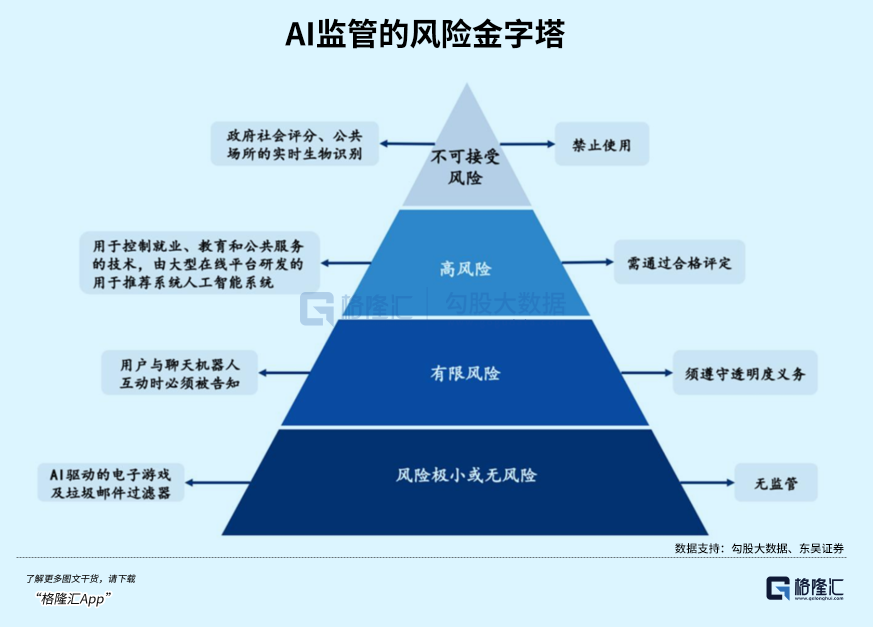
2.高风险应用场景的硬性要求
简单来说,AI输出必须清晰可理解,应用必须有对应的人类负责人。
尤其是医疗、教育、司法这三个和公众利益息息相关的领域,规则提出了非常严格的要求:强制要求AI决策可解释,并且必须有人类做最终监督。
什么是强制可解释性?
目前常用的深度学习神经网络本身属于“黑箱模型”,很多时候只能输出结果,没法说清推理逻辑。
比如AI给病人诊断,直接得出肺癌的结论,医生问为什么得出这个结果,AI只能给出一堆专业参数,没人能看懂。
未来这种情况是绝对不允许的。
AI必须用人类能理解的逻辑说明,自己看到了哪些特征、符合哪些诊断标准,才得出对应的结论。
人类监督很好理解:不管是AI辅助判案、辅助手术还是自动批改试卷,最终做确认、拍板的必须是人类,AI只有辅助执行的权限,没有最终决定权。
3.大模型必须满足透明度要求
第一个要求,是训练数据必须能做版权溯源。
过去几年很多AI创业者直接从互联网无差别爬取数据训练模型,相当于免费使用他人内容训练自己的产品,现在这条路走不通了,必须明确说明训练数据的来源,证明所有数据都拿到了合法授权。
第二个要求,必须提交完整的安全评估报告。
大模型上线之前,必须完成红蓝对抗形式的安全测试,出具完整详实的安全评估报告才能准入。
怎么才算达标?
比方说,机构需要专门安排测试人员,想尽办法诱导AI说出制造危险物品的方法,如果AI始终坚守安全底线不输出违规内容,才能证明自身安全性符合要求。
只有通过安全测试的模型,才能正式进入市场商用。
以上这些要求,如果违反,惩罚力度都非常大。
欧盟《人工智能法案》明确规定,违反禁止类AI应用规则,最高会被处以3500万欧元,或者企业上一财年全球总营业额7%的罚款,两个标准取金额更高的那个执行。哪怕是全球最严格的隐私法规GDPR,最高罚款也只到全球营业额的4%,可见这次AI监管的处罚力度。
国内的规则虽然表述相对温和,但落地执行的管控力度更强。
国内规则明确禁止个人社会评分、无授权深度伪造人脸语音、全自动生成虚假舆情信息,机构违规最高罚款1000万元,直接责任人最高处罚50万元,还可以同时处以行业禁入。
针对医疗辅助诊断、校园智能考评、司法智能研判这三类高风险AI产品,上市之前必须完成伦理审查备案,不备案就不能上市,违规的会被要求停产整改,取消所有行业补贴,6个月内禁止申报任何AI科创项目。
针对国内大模型企业,要求必须完成训练数据集的合规标注,标注覆盖率不能低于92%,开源模型必须公开完整的数据来源清单。
从2026年第四季度开始,没有完成版权溯源的大模型,禁止继续商业化迭代升级。
比起罚款,暂停API服务、下架应用、吊销算法备案这些处罚,对企业的影响要大得多。
监管这么严格,AI技术的发展会不会因此放慢脚步?
02
答案是不会。
但会推动行业发展方向调整。
根据Gartner发布的新兴技术成熟度曲线,生成式AI其实早就度过了资本追捧的期望膨胀期,正在进入看重实际投资回报的成熟发展阶段。
当炒作的热度退去,企业关注的重点自然会从“AI能力有多强”转变成“AI应用是不是足够安全合规”。
而规范行业发展,必须依靠强监管才能实现。
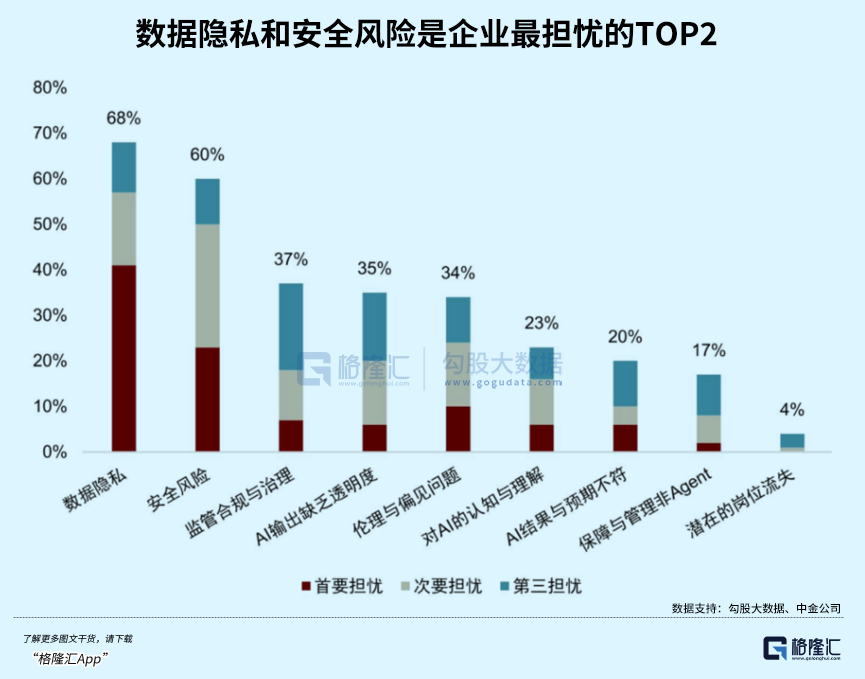
在监管落地之后,AI研发的重心已经开始转移。
1.从单纯追求参数规模,转向更重视RAG检索增强生成技术
之前所有AI厂商都在比拼参数大小,比拼谁的模型能记住更多全球知识,但这种发展路径带来了很严重的AI幻觉问题,模型也完全不透明。
未来,大参数模型依然有发展空间,但只会是少数头部科技巨头的赛道,RAG技术才是企业级AI应用的标准配置。
RAG的逻辑很简单:要求AI不能随意编造内容,需要先从企业指定的、已经完成版权清理的合规内部数据库中检索资料,再根据检索到的真实内容输出总结结果。
这样一来,AI输出的每一句话都能找到对应的原始文档出处,完全符合监管规则对透明度和可解释性的要求。
2.模型对齐与安全成为研发核心
打个比方来说,之前给大模型做基于人类反馈的强化学习,更像是给AI请了一个教它礼仪的老师,没有从根本上改变AI的底层逻辑。
现在有了严格的安全评估要求,AI需要的不是指导,而是必须遵守的刚性规则。
Anthropic提出的宪法AI理念一定会被行业广泛采用,未来大模型在设计之初,就需要把不生成违规内容、不歧视特定群体这些安全原则,硬编码到模型的损失函数中,从底层约束AI的输出。
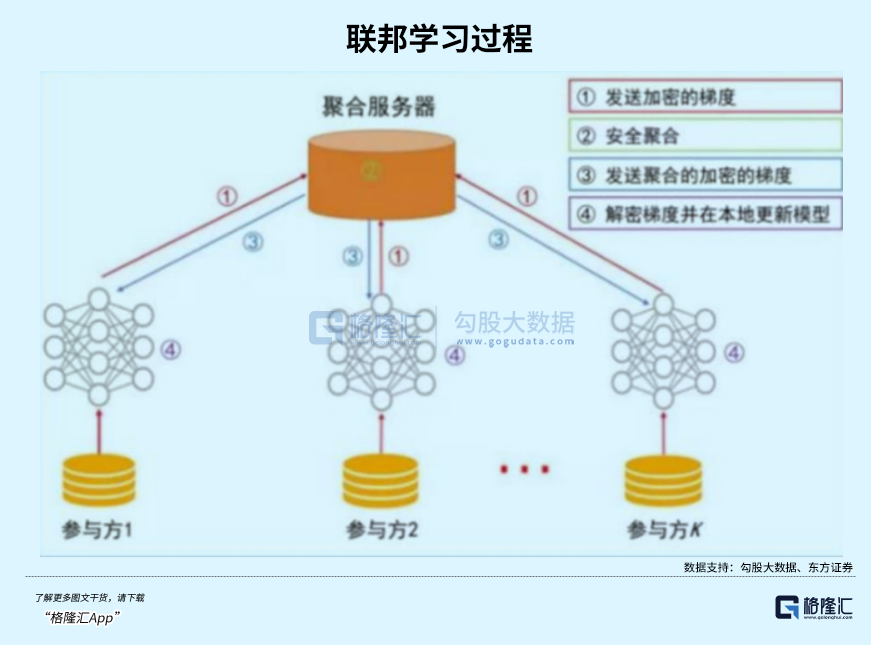
3.隐私计算技术会快速崛起
既然不允许随意爬取数据,又要求保护高风险场景下的用户隐私,该怎么解决这个矛盾?
联邦学习和差分隐私这些隐私计算技术,一定会成为行业刚需。
比如多家医院想要联合训练医疗AI模型,但又不能交换共享病人的隐私数据,这时候联邦学习就能实现“数据可用不可见”:模型可以在每家医院的本地服务器上分别训练,最终只汇总共享模型参数,不需要传输原始的病人隐私数据。
这类帮助企业满足合规要求的技术,一定会成为资本追逐的新热点。
换句话说,整个AI行业的格局很快就会发生明显变化。
先说新规之下的受益者。
最大的受益者,是现在已经布局AI的头部科技大厂。
行业里有个说法叫“监管护城河”,满足合规要求需要付出很高的成本:要梳理训练数据做版权溯源、要养活上百人的安全评估团队……这些硬性门槛,直接把绝大多数想要做基础大模型的中小创业公司拦在了门外。
头部巨头有充足的资金和专业的法务团队,能轻松跨过这些门槛,合规要求反而成了巨头阻挡竞争对手的最宽护城河。
其次受益的是To B企业服务软件巨头,还有AI合规工具开发商。
根据麦肯锡发布的报告,生成式AI每年可以给全球经济创造2.6万亿到4.4万亿美元的价值,这块市场不会因为监管消失,只会更快向企业服务市场转移。
企业客户最怕的就是违规罚款、声誉受损,所以能提供开箱即用、完全合规、自带可解释性的AI企业服务公司,还有做AI水印、深度伪造检测、AI合规审计的SaaS公司,接下来大概率会迎来业绩的高速增长。
再看新规之下受影响的群体。
只做套壳的创业公司首当其冲。
这几年市场上出现了成千上万的AI创业公司,只是调用大厂的API,套一个界面就出来融资,根本没有自己的核心技术。
现在新规要求高风险场景必须满足可解释性和透明度要求,这些套壳公司根本接触不到底层模型参数,也拿不出训练数据的来源证明,客户要安全评估报告的时候根本拿不出来,最终大概率会批量出清。
然后是之前野蛮生长的开源社区。
新规对透明度的要求对所有模型一视同仁,如果你开源了一个大模型,被别人拿去做诈骗,或者你的训练数据里有大量未授权的版权内容,开源作者要不要承担连带责任?
虽然新规对纯科研用途的项目有一定豁免,但很多游走在商业化边缘的开源项目,会面临很大的法律风险。
未来开源模型的发布一定会变得更谨慎,过去那种随便把代码扔到GitHub就不管的时代已经结束了。
03
看到这里我们可以得出结论:
强监管落地,不是AI创新的终点,反而会开启AI真正大规模商业化落地的新阶段。
市场最害怕的就是不确定性,监管落地之前,企业想用AI又不敢大胆用,就怕不小心踩了红线惹上官司。
现在规则明确了,禁区划清楚了,企业反而可以放开手脚,在合规框架内投入预算采购AI服务。
所以说,AI技术的发展不会因为监管放缓,只会在企业服务市场迎来更扎实、更稳健的增长。
只有给AI明确规则,让AI学会守住底线,才能让AI真正安全地走进每个人的生活。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com