
iPhone本地运行Gemma4引热议,零token时代还有多久?






本文来自微信公众号:机器之心,作者:机器之心,原文标题:《iPhone本地跑Gemma 4火了,0 token时代还有多远?》
谷歌日前开源的新模型Gemma 4,给业界带来了不小的惊喜。
该模型采用与Gemini 3同源的技术架构,支持原生全模态,在Arena AI排行榜上位列全球第三,且提供多个型号选择。其中较小的E2B(有效参数2.3B)和E4B(有效参数4.5B)型号可直接在手机端本地部署,上下文窗口达128K,堪称「可随身携带的Gemini平替」。
模型发布后迅速成为手机用户的新宠。
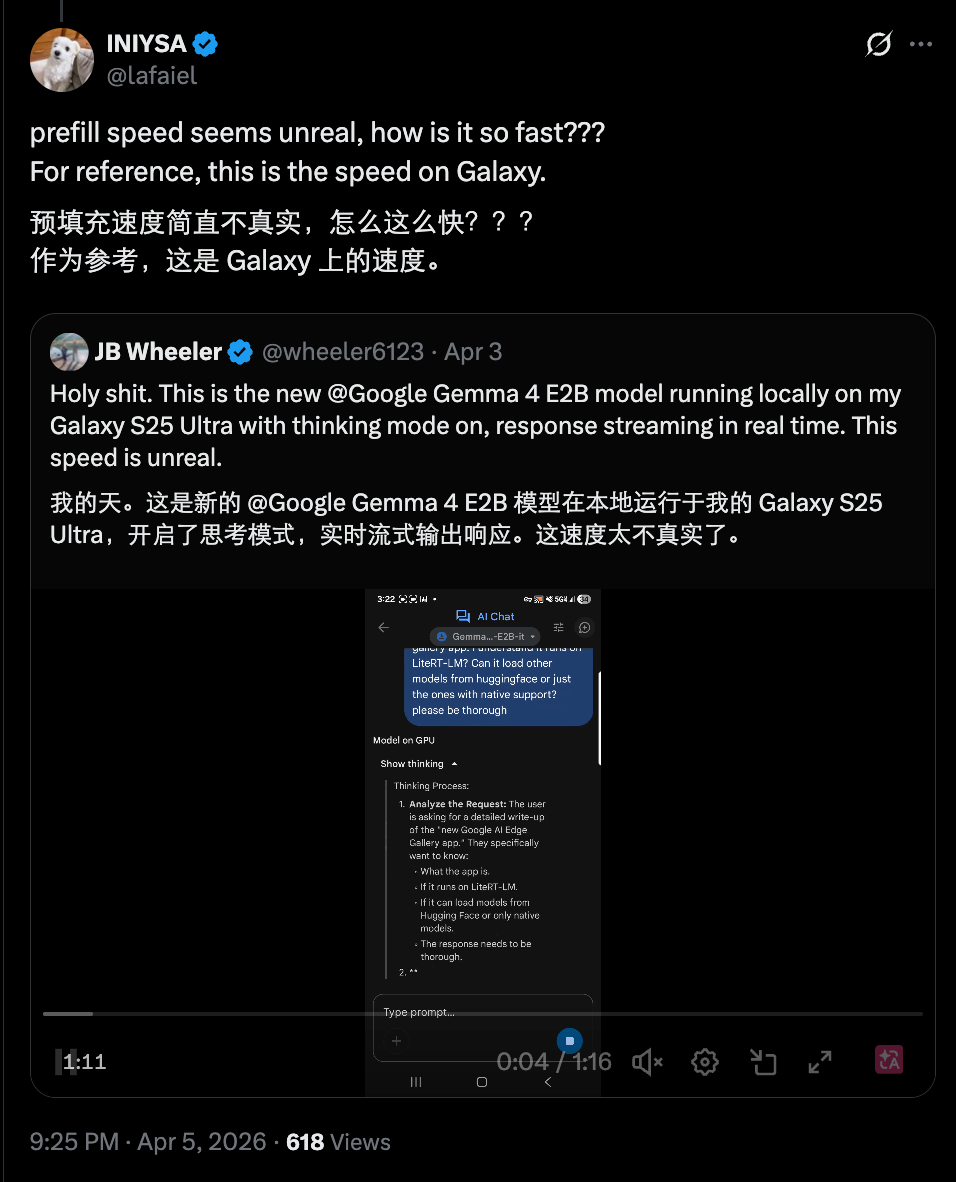
一位X用户的帖子获得数十万次围观,他在视频中展示了如何在iPhone上本地运行Gemma 4,包括处理图片、音频及控制手电筒开关,称其速度快得惊人,如同魔法。

有人在iPhone 17 Pro上测试了速度,指出若手机搭载苹果芯片,借助针对该芯片优化的MLX(苹果机器学习框架),模型推理速度可超40 token/秒。

还有人在三星Galaxy上也跑出了相近速度,且是在开启思考模式的情况下,让人感叹「快得不真实」。
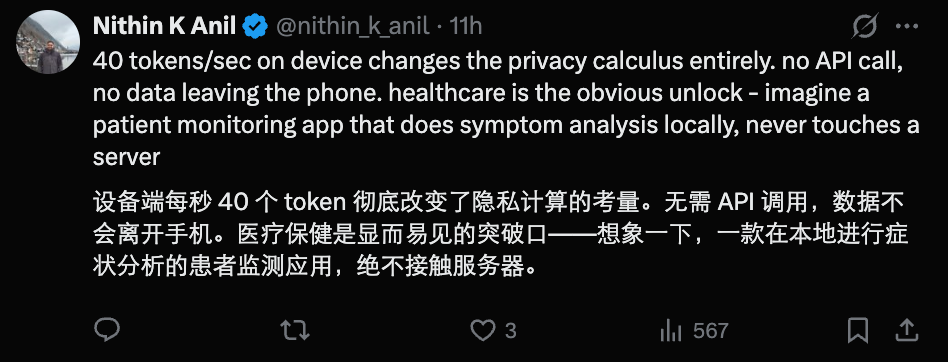
这样的速度让手机端运行AI模型成为未来可接受的选项,尤其在医疗等敏感场景中作用显著。
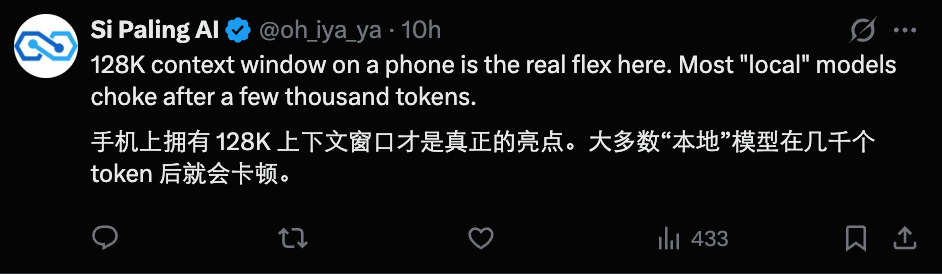
128k的上下文窗口也让这些小模型更具吸引力。
具体如何运行呢?其实很简单,并非极客专属,因为谷歌推出了官方App——Google AI Edge Gallery。想在手机上体验的用户可直接下载该App,选择并下载想要运行的模型版本,打开即可使用。

而且,作为谷歌官方发布的应用,安全问题无需过多担忧。
除了手机端运行的小模型,也有人在更强硬件上尝试更大版本的Gemma 4,比如在M5 Pro版本的MacBook Pro上运行Gemma 4 Mixture-of-Experts 26B。

直接对话时,该模型速度较快,文本生成、代码解释都很流畅。

但将其作为coding agent使用时,问题便显现出来。因为运行agent需要大上下文(Gemma 4 26B上下文窗口为256k)、复杂prompt和稳定的工具调用,Gemma 4在这些方面明显力不从心,常出现卡住、报错或输出结构错误的情况。

当他换成qwen3-coder模型后,同样环境下文件创建、命令执行、多步任务都能正常运行。他认为问题不在agent框架,而在于模型是否针对「工具调用+结构化输出」做过优化。Gemma 4在这方面可能做得不足,也可能是开发者尚未找到正确用法。

此外,也有人认为Gemma 4的智力水平略显鸡肋。
尽管如此,Gemma 4这类「性能小钢炮」的出现仍不容忽视。若未来大量日常查询、聊天、简单推理、代码生成、图像理解任务都能本地运行,无需购买token,那靠卖token的厂商处境岂不是很尴尬?
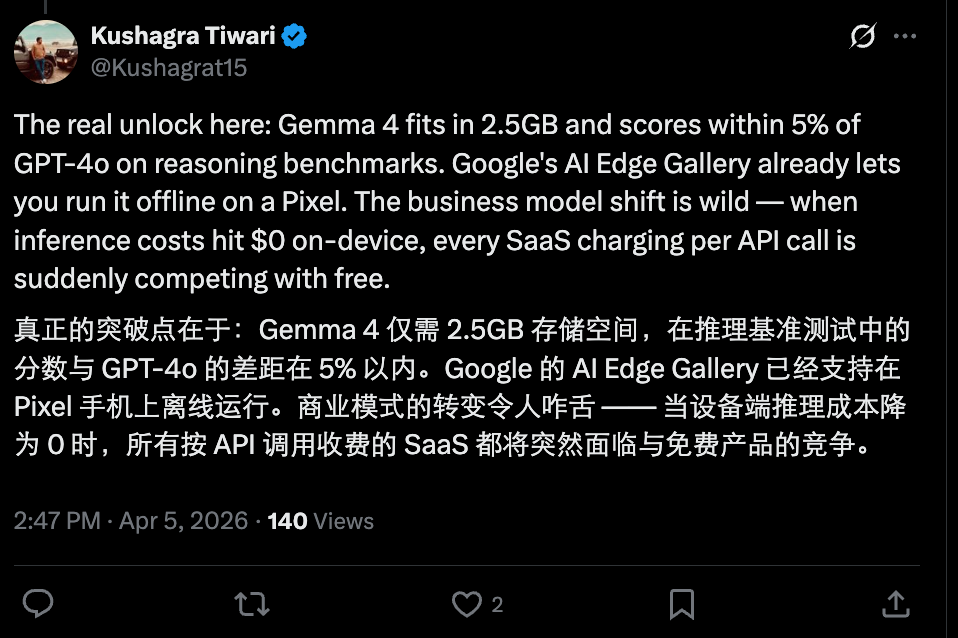
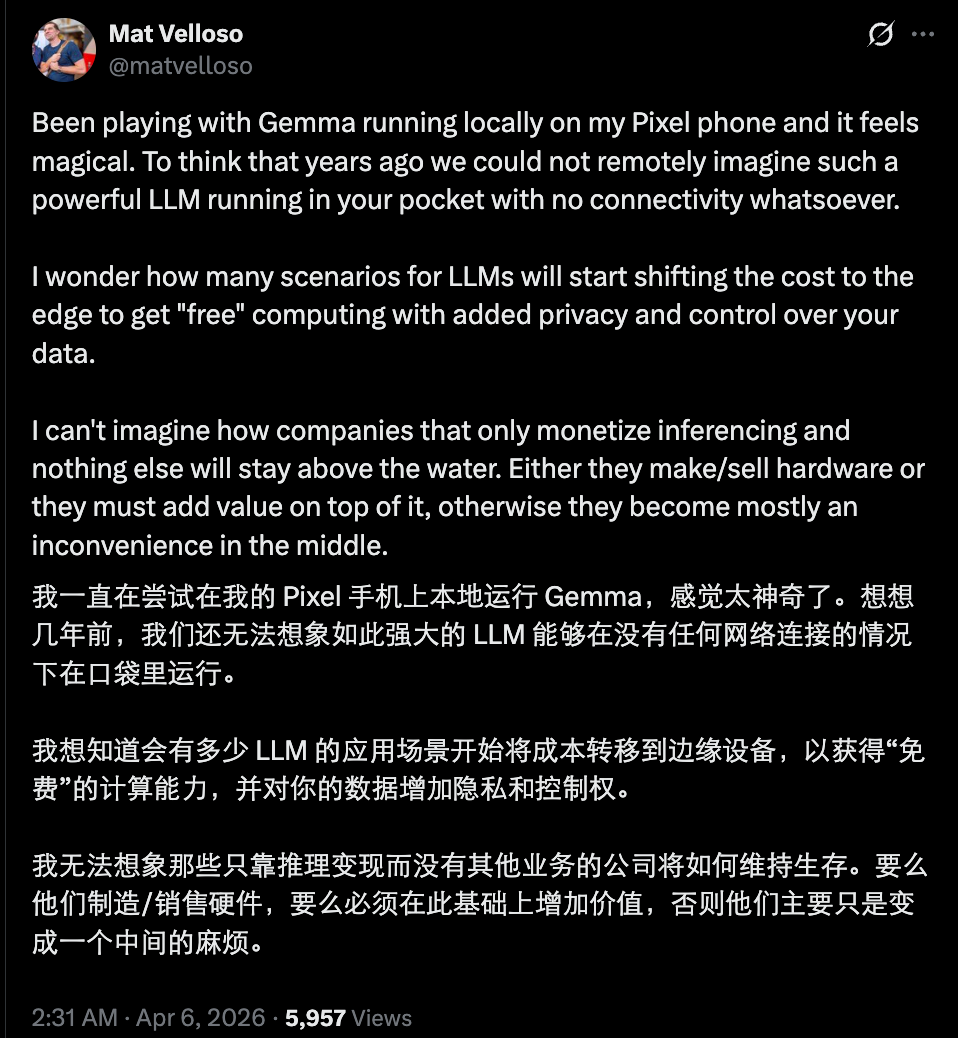
当然,目前情况尚未如此悲观,毕竟开源模型与前沿旗舰闭源模型仍有差距,且多数优秀开源模型受硬件能力限制,暂时无法在端侧达到可用水平。
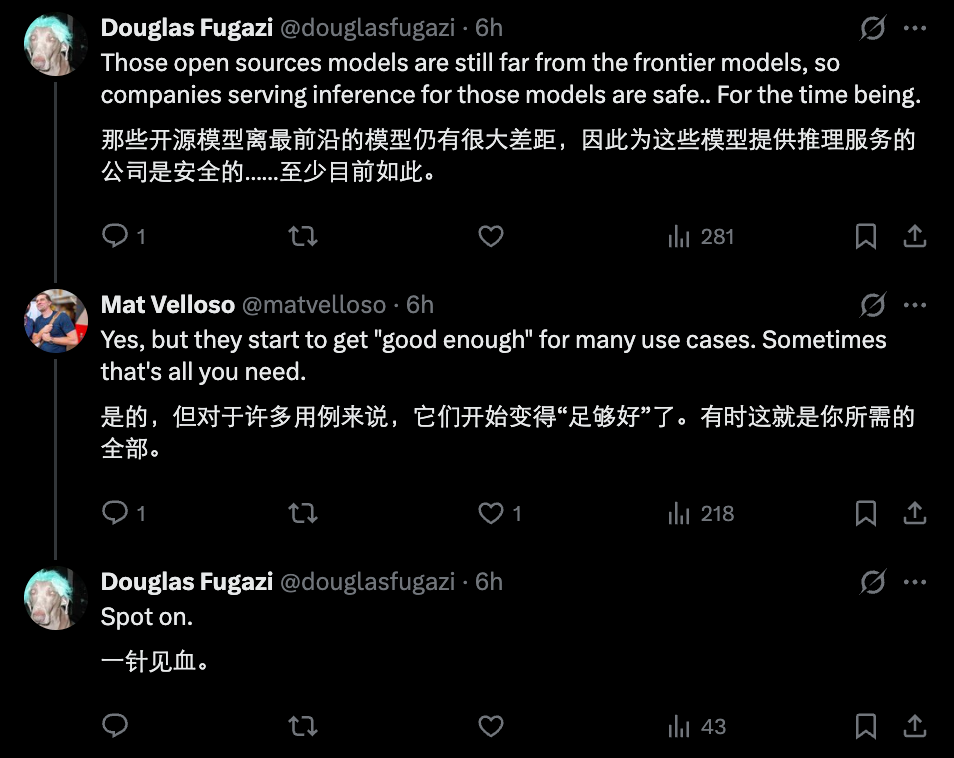
但未来趋势清晰:短期看,云端闭源模型在前沿复杂推理和超大规模多代理协作上仍领先;长期而言,随着硬件进步和量化技术优化,端侧模型会逐步占据云端的高频简单任务。
那些仅靠卖token、卖API订阅的厂商,将不得不更专注于「真正难啃」的领域——超强Agent、超长可靠上下文,以及需要海量实时数据的专有能力。
Gemma 4只是一个开端。下一个惊喜或许是某款端侧模型在日常使用中让用户完全感受不到「本地」与「云端」的区别。当那一天到来,整个AI产业的商业模式将迎来真正的洗牌。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com