
字节跳动携Helios大模型:破解AI视频生成的“不可能三角”









Seedance 2.0登顶Sora之后,AI视频生成领域便陷入狂热与焦虑交织的状态。
即便强大如Seedance 2.0,依旧难以突破该领域的“不可能三角”:
模型规模、生成时长与推理速度始终难以兼顾。
若想拥有Seedance 2.0般的电影级画质,就必须依赖字节这类大厂打造的百亿参数多模态模型,代价却是最长15秒的视频时长、高昂的单次生成成本以及十几分钟的等待时间。
若追求快速出片,就不得不向参数量妥协,采用约10亿参数的小模型,结果便是画面模糊、细节缺失,超过10秒就会出现崩溃。
要是无法实现高质量、实时的长视频,AI视频生成就永远无法触及电影级应用。
不过,推出Seedance 2.0这一划时代作品的字节跳动,野心远不止于此。
由北京大学与字节跳动等机构联合研发的Helios大模型,正试图以利刃劈开这一“不可能三角”。
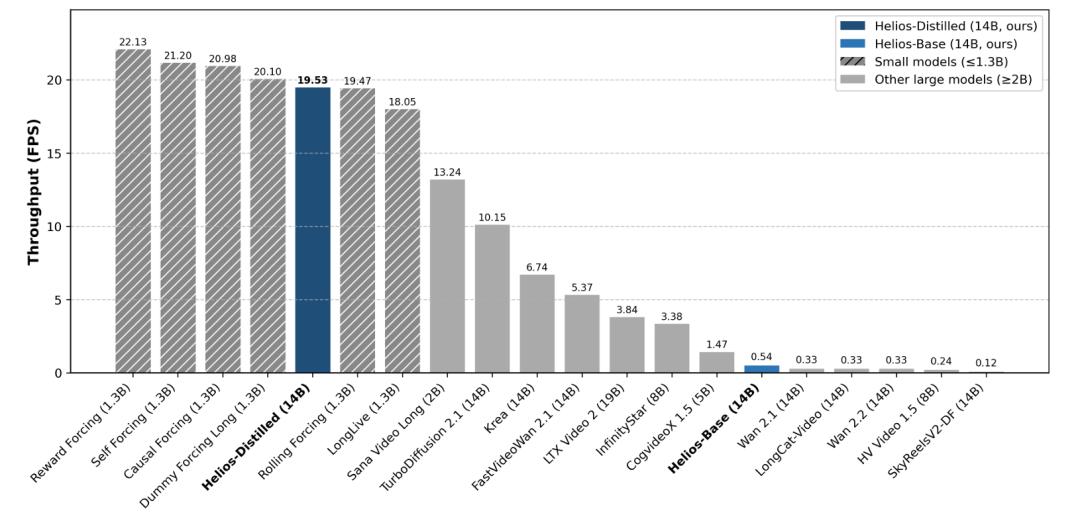
Helios是首个能在单张英伟达H100显卡上,以19.53帧/秒(FPS)速度运行的140亿参数大模型。
这个参数量虽不算轻量级,但与各大AI厂商的旗舰大语言模型相比,只能算是“迷你版”。
尽管“身材”略显单薄,但其画质可与当前顶尖模型媲美,还能以接近“实时”的速度连贯生成长达数分钟的视频。
01 令人头疼的“长程漂移”
使用过即梦、可灵、Sora的用户或许都有过这样的疑问:为何视频生成最多只有10秒或15秒?即便用户再富有,也无法突破这一限制。
实际上,这不仅是算力问题,即便强行延长生成时间上限,视频效果也未必理想:
AI生成的视频往往前几秒画面惊艳,但随着时间推移,画质会迅速下降,比如主角面部特征无法保持、肢体结构突变、背景扭曲、动作违背物理逻辑等。

这就是“漂移”现象。
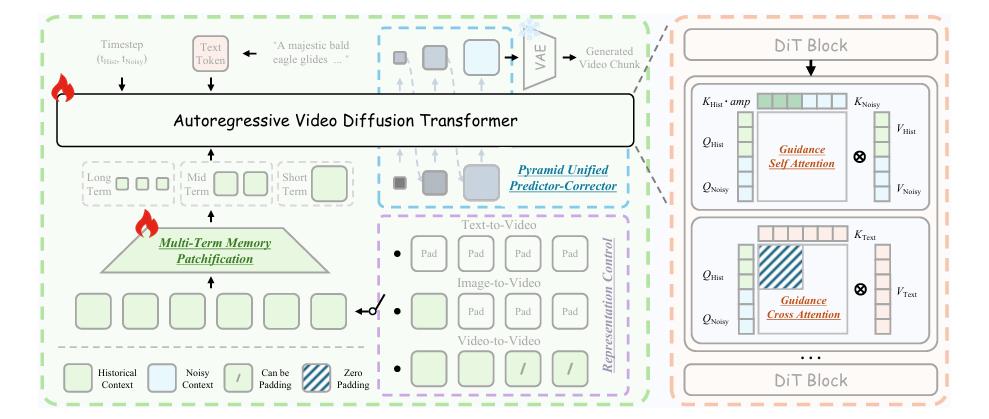
AI生成视频的过程,与大语言模型问答类似。大语言模型需依据记忆和上下文给出后续回答,多模态模型同样需要“基于历史,绘制未来”。
在FPS固定时,视频越长,帧数越多,意味着AI需从每一帧中记忆的信息呈几何级增长。
在此过程中,哪怕前期生成的画面存在一丝微小瑕疵,也会在后续生成中不断累积放大,最终导致全面崩溃。
为解决这一问题,早期学术界最直接的方法是在训练AI时让其一次性生成长片段,以避免瑕疵扩大,但这种强化学习方法易出现欠拟合和过拟合问题,算力成本更是高得难以承受,百亿参数大模型根本用不起,10亿参数已是极限。
因此,Helios的研究团队意识到,需从视频生成过程中寻找突破口。
他们首先发现,长视频崩溃常伴随画面亮度和色彩的整体失控,而视频开头几秒通常不会出现这种问题。
于是,“首帧锚点(First Frame Anchor)”机制应运而生。
研究团队将视频第一帧定为整个生成过程的“定海神针”,AI在后续漫长生成中必须紧紧“盯住”第一帧,锁定全局外观分布。
无论提示词要求后续画面如何发展,第一帧确立的整体色调和人物身份都能随时将AI拉回正轨,避免“画风突变”。
但即便如此,瑕疵仍不可避免,因此必须让AI学会处理这种“不完美”。
Helios在训练阶段采用了一种特殊手段:帧感知破坏(Frame Aware Corrupt)。
简单来说,就是随机向AI依赖的历史画面加入各种瑕疵,让AI通过强化学习降低对历史画面的绝对依赖,并学会依据常识修复各类问题。
经过这种训练,Helios对误差的容忍度极高,视频再长也不易崩溃。
最后一个需解决的问题是位置偏移和重复运动。
AI生成视频时的位置编码是绝对的,当生成视频长度超过训练时见过的最大长度,注意力机制紊乱会导致画面闪回初始位置。
Helios将位置编码改为相对参考,不再关注“这是第X帧”,而是关注“这是过去几帧的延续”,从根源上杜绝了动作的周期性重复。
02 算力的“魔法”
画质崩坏问题在软件层面得到解决,但更严峻的挑战来自硬件层面:
140亿参数说多不多、说少不少,如何让它在单张显卡上实现19.5 FPS的实时运行?
AI视频生成本质与大语言模型无异,普遍采用的Diffusion Transformer(DiT)架构同样运用自注意力机制捕捉视频的空间细节(单帧内容)和时间连贯性(帧间运动)。
但由于向量空间中图像维度高于文本,视频每一帧内容的计算量远大于大语言模型的一次问答。视频延长短短几秒,计算量和显存占用就会指数级增长,必须借助GPU集群分摊压力。
用算力换取画面质量和视频时长,Sora的关闭以及Seedance 2.0发布后的“降智”已给出明确答案:从商业角度行不通。
Helios果断选择了其他路径,这套名为“深度压缩流(Deep Compression Flow)”的底层重构方案,从token缩减、步数蒸馏到显存管理,几乎榨干了GPU的所有潜能,如同变魔术般上演了“见证奇迹的时刻”。
1. token视角:时空维度极致压缩
首先要解决的是视频上下文过长导致显存不足的问题,Helios给出的方案是对时空维度进行非对称压缩。
前面提到,AI生成视频是“基于历史,绘制未来”。因此,准备多久的“历史资料”是关键问题。
对人类而言,记忆类似数据结构中的“栈”,后进先出:我们对前一秒的事记忆犹新,对十分钟前的事则记忆模糊。
Helios完全借鉴了这种仿生学的多期记忆分块机制,将AI需回顾的历史画面分为短期、中期和长期三种。
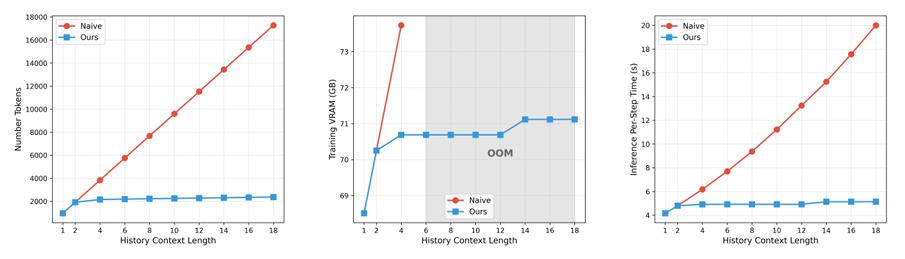
对于几帧前的画面,Helios保留最高清细节;对于多帧前较久远的画面,Helios进行高强度压缩,仅保留最粗略的全局布局。
这个简单思路让Helios在回顾久远历史画面时,token消耗仍保持在极低的恒定水平,历史信息的显存占用直接压缩至原先的八分之一,彻底解决了单卡运行“爆显存”的难题。
生成画面时,Helios也未直接在最高分辨率下开始,而是采用自底向上的开发策略。
这类似画家绘画,先在低分辨率下快速勾勒整体颜色和布局轮廓,再逐层放大,精雕细琢边缘和纹理等细节。
早期去噪决定宏观结构,后期去噪优化细节,通过这种任务拆解机制,计算量可降至一半以下。
2. 步数视角:对抗性分层蒸馏
AI视频生成速度慢,是因为传统扩散模型需要约50步反复去噪。
过去的视频生成模型在学习一步到位时,为防止忘记历史画面“断片”,必须通过“模拟展开推理”训练。
模型生成一段视频后,不仅要靠奖励模型评判好坏,还要续写几段模拟未来的长视频。
毫无疑问,这种做法会导致耗时极长和显存爆炸。
但Helios采用“纯教师强制(Pure Teacher Forcing)”模式,让模型无需模拟未来视频,而是直接将海量真实连续视频切片作为唯一参考标准喂给模型。
模型每次训练,仅专注于在给定真实历史画面下“完美画出下一小段”,去除复杂模拟过程后训练效率指数级提升。
去噪过程中,也存在类似大语言模型的蒸馏机制。
但知识蒸馏总有一个致命缺陷:学生上限不会超过老师,下限却可能低于老师。一旦缺点被放大,生成视频质量自然下降。
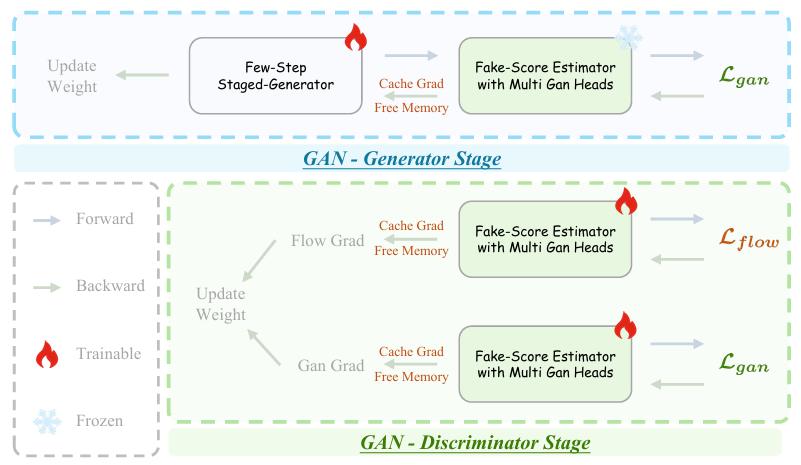
为此,Helios引入基于真实视频的对抗性后训练,如果学生去噪结果只是模仿老师,缺乏真实物理细节,就打回重做。
这种严格训练方式,奇迹般地将原本需要50步才能实现的画面保真度压缩到仅3步。
3. 显存视角:重构调度机制
GPU显存是固定的,但模型中有多个子模型需串行计算。
为此,研究团队设计了一套高级调度机制,利用专属数据通道,仅在GPU中保存正在计算的子模型,计算结束闲置时,立即将参数转移到CPU待命。
对于PyTorch等现代AI训练框架,前向计算时中间变量会保存到显存以备反向传播。
研究团队注意到这一环节后,直接打破了框架底层计算逻辑,只要梯度计算完成,立即手动触发程序并在毫秒级释放激活状态,硬是节省出一倍以上的空闲显存。
此外,官方深度学习框架还有许多隐藏的数据传输损耗。
为进一步加速视频生成,研究团队直接绕开PyTorch,用底层编译器语言Triton编写核心代码,甚至在传统注意力机制计算中,直接剔除了内存占用复杂度中的一个乘数维度。
正是这一系列从算法底层到显存调度的极致优化,让140亿参数的大模型在H100上创造了奇迹。
03 Helios:重构AI视频的商业格局
一项底层技术的突破,往往可能引发产业链变革,而Helios恰好诞生于研发Seedance 2.0的字节跳动。
这个规模适中的模型,却具备“高质量+实时+单卡+长时间”这一前所未有的特性组合,精准突破了AI视频商业化的壁垒。
Sora的关闭、Seedance 2.0发布后不久被发现“降智”的事实,表明阻碍AI视频大规模ToC端落地的最大障碍是高昂价格。
近一年来,市面上效果较好的视频生成模型,生成一次10秒左右的视频都需消耗极高算力成本。
采用订阅制时,现有调用量只会让AI公司亏损;即便向B端企业开放API,不仅技术上存在差距,靠模型产出商业化成品的费用也让开发者望而却步。
但Helios将140亿参数模型的运行门槛直接降至单张H100,且吞吐量极高。
尽管消费级显卡仍无法胜任,但这意味着云厂商和SaaS平台的单路并发成本将大幅降低,API商业模式可能迎来质变。
现有的按生成次数付费的积分制,未来可能转变为与大语言模型一样的按token计费。
只有当生成成本足够低时,多模态模型才能从“奢侈品”转变为像大语言模型一样的基础设施。
Helios带来的另一个颠覆性商业想象是,AI视频生成即将摆脱“离线渲染”标签,成为实时互动引擎。
无论是Seedance 2.0还是Sora,本质上仍是高级离线渲染器:用户输入提示词、模型开始生成、等待一段时间、获得一段“开盲盒”式的视频。
这种非实时交互,注定只能作为内容制作的素材生产工具。哪怕效果不佳,费用也得照付。
但Helios已展现出实时互动引擎的雏形。19.5 FPS的速度和连贯的上下文记忆,简直是为交互式生成量身定制。
若未来用户能在视频生成播放过程中动态修改指令,将直接打开世界模型、沉浸式体验甚至具身智能等商业空间。
Helios的出现,为整个AI视频生成赛道的参与者指明了新方向:
与其通过削减参数换取生成速度,不如在记忆管理、蒸馏机制和显存调度上多下功夫。
技术的护城河,构筑于对底层架构的极致重构之上。
本文来自微信公众号“硅基星芒”,作者:思齐,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com