
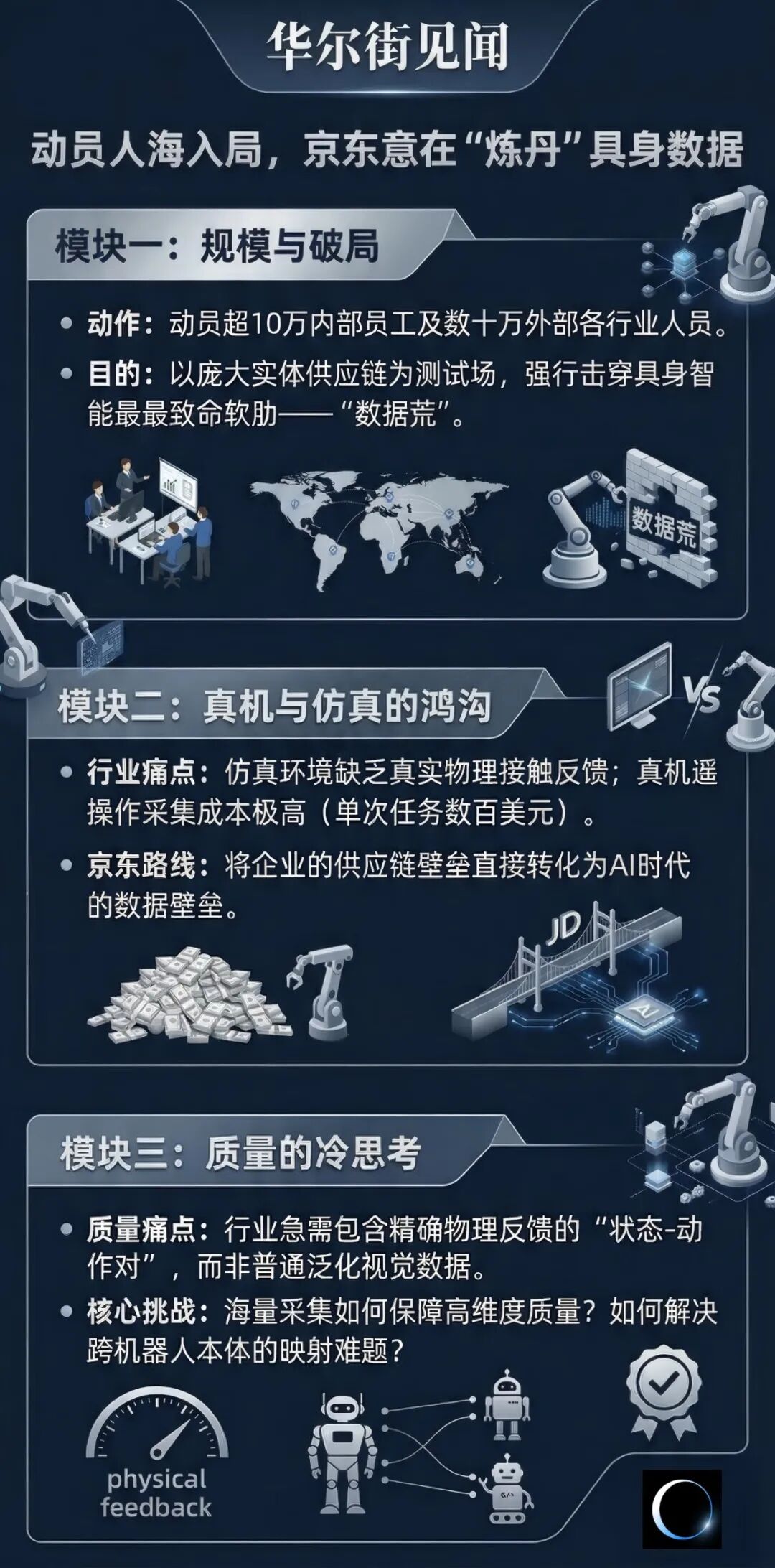
京东启动大规模数据采集:以人海战术破解具身智能数据困局








3月16日,京东宣布建成全球规模最大、场景最全的具身智能数据采集中心,这一消息在一度沉寂的机器人赛道引发关注。此次行动动员了内部超10万员工及外部最多50万各行业人员,甚至在宿迁一地就动员超10万市民,试图以规模化方式解决具身智能面临的“数据荒”难题。
在模型架构逐渐成熟、算力门槛相对透明的当下,高质量物理交互数据已成为机器人能否广泛应用的关键。这场被称为“人类历史上规模最大的数据采集行动”,反映出行业共识:当具身智能的运动控制能力不断提升,如何用高质量数据培养其对物理世界的理解能力,成为决定行业格局的核心。
卷入的参与者
京东发起这场数据采集行动的核心支撑,是其庞大且复杂的自营实体供应链。与纯软件企业不同,京东自身就是物理世界的互动场,具身智能的成熟直接关系到其未来履约成本与运营效率。这一布局与北京亦庄的机器人产业生态深度结合,亦庄已集聚300余家机器人相关企业,开放40余个应用场景,京东作为“链主”企业,此前已发布机器人产业加速计划,此次投入数据采集中心意在补齐产业链短板,形成从数据到硬件迭代的闭环。
数据采集场景覆盖物流、工业、零售等领域,实际操作可能依赖京东现有的数字化管理网络,例如让一线员工佩戴传感器设备作业。不过,目前相关实施细节尚未传导至员工层面,部分京东员工表示尚未收到通知,认为若有合理报酬,参与与否取决于个人选择。同时,数据合规问题也引发关注,快递配送、零售场景涉及大量隐私数据,脱敏与清洗的合规成本可能极高。
破解莫拉维克悖论
1988年,机器人学家汉斯・莫拉维克提出,计算机在智力测试或下棋中达到成人水平较易,但拥有一岁婴儿的感知和运动能力却极难。如今,具身智能面临的“数据真空”正是这一悖论的体现。大模型依赖互联网积累的文本语料,而物理世界缺乏现成的“数据互联网”,具身智能要实现规模化应用,需突破数据壁垒。
当前行业获取数据的主流方式存在局限:仿真环境虽成本低、速度快,但“仿真到现实”存在鸿沟,物理引擎难以模拟真实世界的复杂物理反馈;遥操作采集数据质量高,但硬件和人力成本高昂,难以规模化;机器人硬件碎片化导致数据难以跨本体复用。在此背景下,拥有真实落地场景的企业更具优势,京东依托物流网络和实体体系,试图打造半自动化数据流水线,将供应链壁垒转化为数据壁垒。
高质量数据的稀缺性
针对京东“两年积累超1000万小时真实场景数据”的计划,业内人士保持冷静。具身智能中,数据的质量和模态比时长更重要,行业缺的是包含精确物理反馈的“状态-动作对”,而非单纯的视觉数据。普通可穿戴设备难以捕捉人类动作中的触觉、力觉等隐性知识,若仅采集视频数据,转化为机器人可执行动作的损耗率可能很高。此外,行业缺乏统一的数据标准,京东采集的人类动作数据如何映射到不同构型的机器人本体,仍是难题。若缺乏标准,这些数据可能仅服务于京东自研机器人,难以推动全行业进步。
京东的举措标志着国内企业尝试以规模化手段解决数据短缺问题,但要实现机器人“智能涌现”,需保障数据的高维度与高质量,建立统一标准,并妥善处理隐私合规问题。这些是行业迈向商业化必须解决的课题。
本文来自微信公众号 “全天候科技”(ID:iawtmt),作者:王小娟,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com