
日本“最强AI”翻车:底层架构实为DeepSeek,网友集体失望








本文源自微信公众号APPSO,作者聚焦明日产品探索,原标题为《日本“最强AI”塌房!代码暴露源自DeepSeek,日本网友炸锅》
近期,日本X平台因乐天集团(Rakuten)的一则发布炸开了锅。这家科技公司在日本经济产业省(METI)GENIAC项目(日本AI政府资助计划)的支持下,高调推出号称“日本最大、性能最强”的7000亿参数大模型Rakuten AI 3.0。
然而发布后不久,开源社区便发现,该模型的底层架构实际来自中国的DeepSeek-V3,乐天仅对其进行了日文数据的微调。
在知名AI开源平台Hugging Face上,Rakuten AI 3.0的配置文件明确标注架构源自DeepSeek V3。
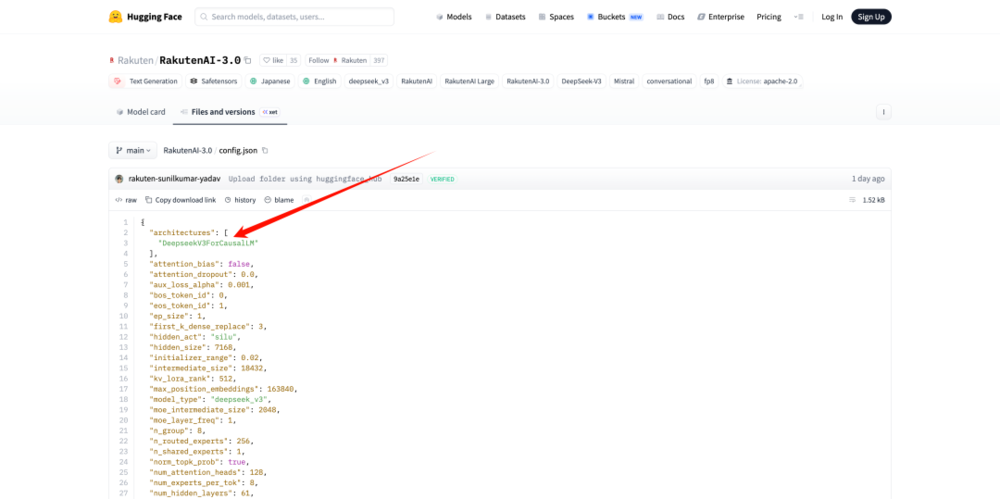
但在Rakuten AI 3.0的发布新闻稿中,却未提及任何关于DeepSeek的信息,仅含糊表示“融合了开源社区的精华”,让不少网友误以为这是日本自主研发的成果。
更关键的是,乐天为掩盖这一事实,在开源时悄悄删除了DeepSeek的MIT开源协议文件。直到被社区实锤后,才以“NOTICE”文件名重新补充。
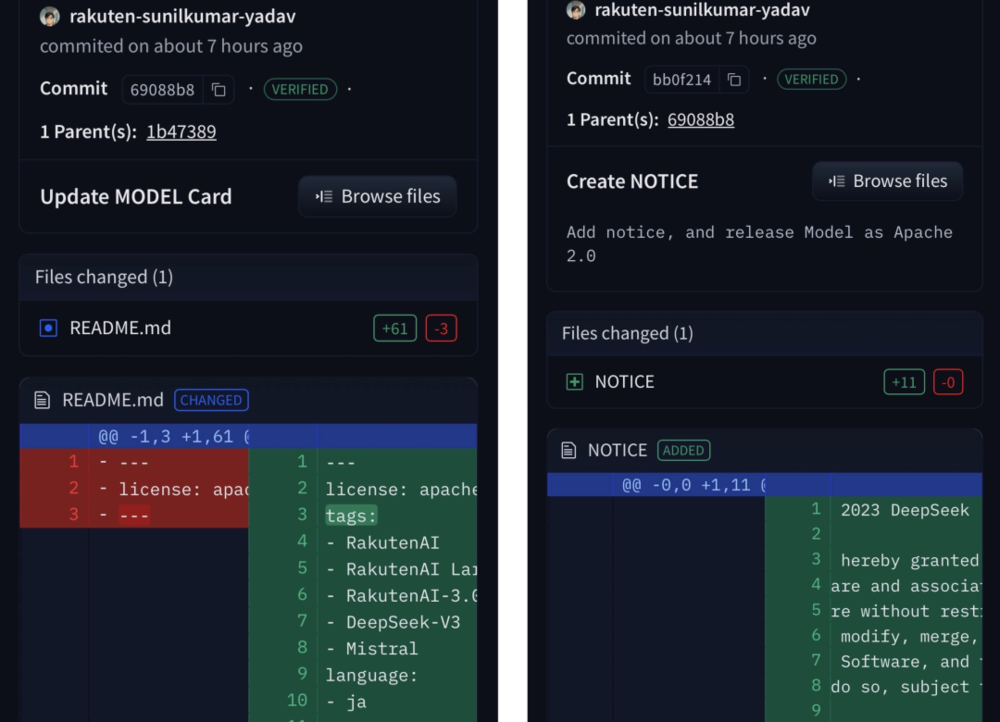
在Hugging Face上可查看项目文件的提交历史,显示相关修改记录。
日本网友纷纷表示无法接受:拿着日本政府补贴,竟只是微调了中国的DeepSeek;还有人吐槽,用DeepSeek就算了,偷偷摸摸的行为实在丢人。
自欺欺人的“日本最强”
单看乐天发布的公关稿,这款模型确实可视为日本在大语言模型领域的一次重要发布。
它是一款约7000亿参数的混合专家(MoE)模型,经开源社区确认,总参数671B、激活参数37B,与DeepSeek V3一致。乐天首席AI官Ting Cai称其为“数据、工程与创新架构在规模上的出色结合”。
Ting Cai的名字听起来不像日本人,有日本网友在评论区指出,使用DeepSeek已很过分,更过分的是主导该模型的负责人是移民强硬派。
经了解,Ting Cai曾在美国谷歌、苹果公司任职,在微软工作超15年,本科就读于美国石溪大学计算机科学专业。他在采访中提到,18岁首次出国去的就是日本,确实持移民强硬立场。
关于Rakuten AI 3.0的表现,官方公布的基准测试显示,它在日语文化知识、历史、研究生水平推理、竞技数学及指令遵循等维度得分优异,大有领先日本本土大模型之势。
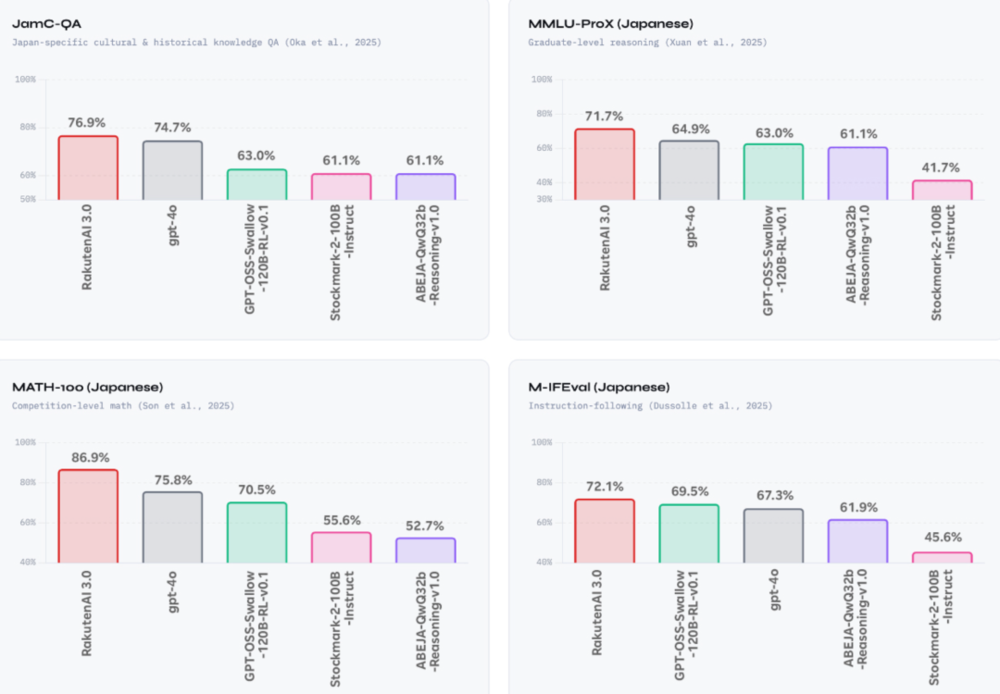
不过,其对比对象包括已下架的GPT 4o、仅1200亿参数的GPT OSS,以及日本新兴AI企业ABEJA基于千问开发的ABEJA QwQ 32b模型。
7000亿参数对阵最多1200亿参数,Rakuten AI 3.0自然优势明显。同时,作为经产省GENIAC项目的重点扶持对象,乐天获得了大量算力资源支持。
GENIAC项目的初衷是构建日本本土生成式AI生态,缓解对海外巨头技术的依赖焦虑。
凭借日本最大参数规模和“国家队”背景,Rakuten AI 3.0一亮相就被寄予“本土希望”的厚望。
核心仍是DeepSeek
但这份光环褪去得比预期更快。
7000亿参数、MoE架构的组合,在开源大模型领域指向性极强。开源社区开发者查看Hugging Face上的代码配置文件后,发现直接标注了DeepSeek V3。
从底层逻辑看,这就是“中国架构+日本微调”:DeepSeek提供了经全球验证的高效底层架构与推理能力,乐天则利用本土优势,通过高质量日文语料微调,使其更贴合日本文化。
客观而言,基于开源模型进行本土化微调在技术圈十分常见且合理。比如作为对比的ABEJA QwQ 32b模型,直接沿用Qwen的代号。

日经新闻报道称,日本公司开发的前十大模型中,有6个基于DeepSeek或Qwen二次开发。
若乐天此次坦诚使用DeepSeek底座,最多只是一次缺乏新意的“套壳”发布,或许还能借DeepSeek的热度。
但他们选择了隐瞒。
此前提及美团浏览器使用开源项目时曾介绍,DeepSeek采用的MIT协议是开源界“最宽松”的协议之一。
它允许用户免费商用、修改甚至闭源盈利,唯一要求是保留原作者的版权与许可声明。

Rakuten模型发布新闻稿|https://global.rakuten.com/corp/news/press/2026/0317_01.html
然而乐天不仅在发布博客中对DeepSeek只字不提,还在代码库中删除了该协议文件,高调宣称采用Apache 2.0协议开源。
尽管Apache 2.0同样对商业友好,但更正式,常被大厂用于构建开源生态和专利护城河。
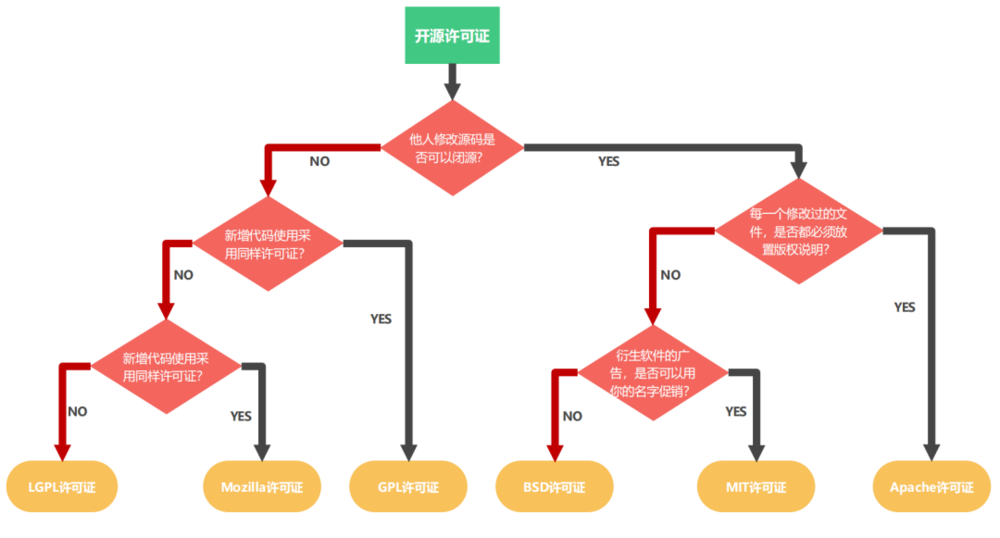
不同开源协议对比:MIT协议比Apache协议更宽松简短;Apache 2.0在赋予自由的同时,明确包含专利授权保护和更严谨的责任免除条款,适合大型、需规避法律风险的商业项目|图片来自互联网
乐天的算盘很清晰:抹去DeepSeek的名字,套上自己的Apache 2.0协议,包装成“开源7000亿参数大模型”的日本AI救世主。
此前喊了一年多的欧洲版、美国版DeepSeek均未落地。
乐天也想做日本版DeepSeek,但在算力与训练成本的压力下,以及全球大模型快速发展的背景下,既想利用中国技术的高性价比,又放不下“本土巨头”的身段,显然难以两全。
不如一起期待DeepSeek V4的到来。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com