
指责中国公司窃技术的Anthropic,竟是北美最大“偷子”?





中美AI竞赛舞台上,一场“贼喊捉贼”的年度大戏正拉开帷幕。
2月23日,TechCrunch爆出的新闻瞬间点燃全球AI领域舆论场。
报道称,以“AI安全”为招牌的明星创业公司Anthropic,公开指控DeepSeek、Moonshot AI和MiniMax三家国内顶尖AI大模型公司,通过系统性欺诈手段利用其Claude模型训练优化自身模型。
Anthropic公布的数据显示,三家公司共创建超2.4万个虚假账户,与Claude模型交互约1600万次。Anthropic声称这些行为旨在通过“蒸馏”提取Claude核心能力,“抄近道”提升自身模型性能。
这番控诉精准踩中中美AI博弈痛点,Anthropic给自己贴上“知识产权受害者”标签,还在舆论场给中国对手扣上“抄袭者”帽子。
讽刺的是,科技圈记忆未退化。就在去年,这位自诩“行业标杆”的控告者,刚因非法用盗版书籍训练模型,掏出15亿美元“买路钱”平息版权官司。Anthropic此举,颇有“洗白后反手举报前同行”的意味。
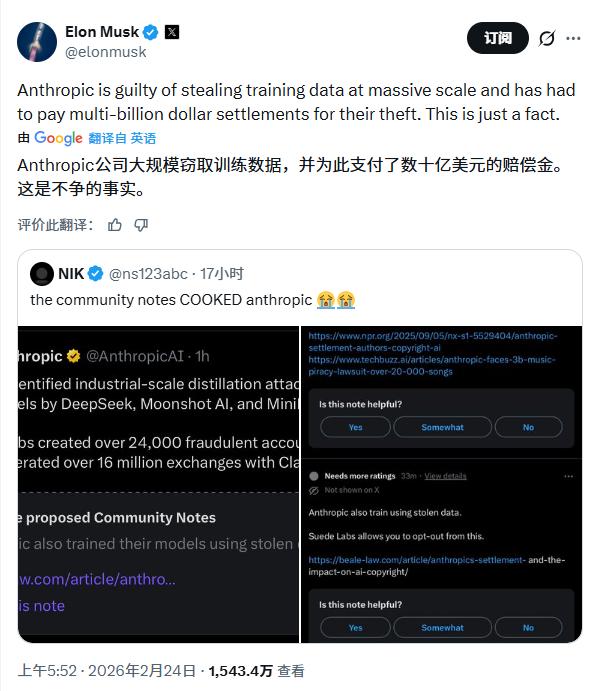
事件发酵后,特斯拉CEO埃隆·马斯克在社交平台X发出灵魂拷问:“他们(中国公司)怎敢窃取Anthropic从人类程序员那窃取的东西?”还表示“我们(xAI)不像Anthropic那样自鸣得意、道貌岸然、虚伪做作”。

当曾经的“大盗”指责别人“偷窃”,我们不禁要问:这是维护知识产权的正义之举,还是激烈竞争焦虑下,“前科犯”通过攻击对手掩盖自身“原罪”的公关策略?
硅谷AI宠儿Anthropic,到底是技术创新捍卫者,还是北美科技圈最大“偷子”?
“捉贼”的Anthropic,忘了自己发家路?
深入探讨Anthropic“黑历史”前,需先厘清这次指控核心“蒸馏”。
AI领域中,“蒸馏”是常见模型压缩和知识迁移技术,简单说就是用更大更强的“教师模型”输出来训练更小更轻量的“学生模型”。
通过模仿“教师模型”对大量问题的解答,“学生模型”能学习其逻辑推理和知识组织能力,实现性能快速追赶。
这种做法是否构成“窃取”?在法律和伦理上都存在巨大争议的灰色地带。
时间回到2025年初,DeepSeek凭借低研发成本的R1模型横扫全球、让硅谷恐慌时,OpenAI曾扮演今天Anthropic的角色,同样声称抓到DeepSeek“蒸馏”其先进模型的证据,引发一场口水战。
但从技术角度看,这并非直接复制模型代码或权重参数,更像学徒观摩大师作画,通过模仿学习风格技巧,而非直接偷画作。许多开源模型和研究项目都在探索模型蒸馏,以期用更低成本实现更高性能。
然而从商业角度,大型模型公司都在用户服务条款中明令禁止此类行为。它们投入数十亿乃至上百亿美元研发成本和算力资源,模型输出(或API调用)被视为核心商业资产。
允许竞争对手无限制“蒸馏”其模型,无异于默许对方用极低成本复制核心竞争力,显然不可接受。
因此,Anthropic的指控在“违反服务条款”上站得住脚,但将其上升到“窃取技术”甚至“商业间谍”高度,则有扩大商业纠纷的嫌疑。
毕竟若API公开可用,利用其输出来研究或训练,行为定性远比直接破解服务器、窃取源代码复杂得多。
这场争论本质是AI时代知识边界的重新定义:模型输出究竟是受保护的知识产权,还是可学习借鉴的公开知识?在问题无明确答案前,Anthropic的指控虽声量大,法理和道义基础却并非坚不可摧。
更何况,这位“原告”自己攫取知识用于模型训练时,手段远比“蒸馏”粗暴直接。
15亿美元和解金,撕开AI“原罪”遮羞布
在高举道德大棒敲打同行前,这位自封的“AI版权警察”,刚为自己的“盗窃行为”交完一笔惊天“罚款”。
时间回到2025年,Anthropic正深陷“Bartzv.Anthropic”法律危机。多位美国作家指控Anthropic训练Claude系列模型时,非法使用数百万本受版权保护的书籍。
这些书籍并非来自合法购买渠道,而是直接从LibGen、Sci-Hub镜像站PiLiMi等著名盗版网站大规模下载。
这是AI行业秘而不宣的“秘密”,为获得高质量、结构化训练语料,许多公司都将目光投向汇集人类几乎所有出版知识的盗版书库。
法庭上,Anthropic试图用“合理使用”原则辩护,称将书籍文本用于训练AI模型是“转换性使用”,目的是提取统计模式构建语言能力,不构成侵权。
但主审法官未完全采纳这一说法,法院裁决在AI训练数据合法性上划下关键红线。
判决认为,若数据合法获取(如购买并扫描书籍),用于AI训练或许可视为合理使用;但从一开始通过非法手段(从盗版网站下载)获取数据,行为本身就构成版权侵权,后续任何使用都无法用“合理使用”豁免。
简言之,法院裁决明确:AI“炼金术”再神奇,也不能建立在盗窃来的原材料之上。
这一判决直接判负Anthropic。据估算,若官司继续,所有侵权指控成立,按每部作品最高15万美元法定赔偿金计算,潜在罚金或为天文数字。为避免公司破产,Anthropic最终选择妥协。
2025年9月,双方达成和解协议,Anthropic同意向作家和出版商支付15亿美元和解金,覆盖约50万部作品,平均每本书“赎身价”约3000美元。作为和解一部分,Anthropic还被要求销毁所有从盗版渠道获取的训练数据。
这起案件是AI领域有史以来金额最大的版权和解案,也成了标志性事件,将以“AI安全伦理”领军者自居的Anthropic钉在“窃取数据”的耻辱柱上——他们为打造Claude的智慧,盗版了整个图书馆。
“百步笑五十步”的闹剧
一边擦着偷吃版权红利的嘴,一边义愤填膺指责别人“白嫖”,这场硅谷大戏荒诞感拉满。
Anthropic指控中国公司“窃取”其模型能力时,似乎忘了Claude本身的能力,有相当一部分建立在“窃取”来的书籍知识之上,这让其指控格外滑稽虚伪。
马斯克的嘲讽虽刻薄,却精准抓住事件核心矛盾:靠“偷”起家的公司,如今摇身一变成知识产权捍卫者,本身就是绝妙的黑色幽默。
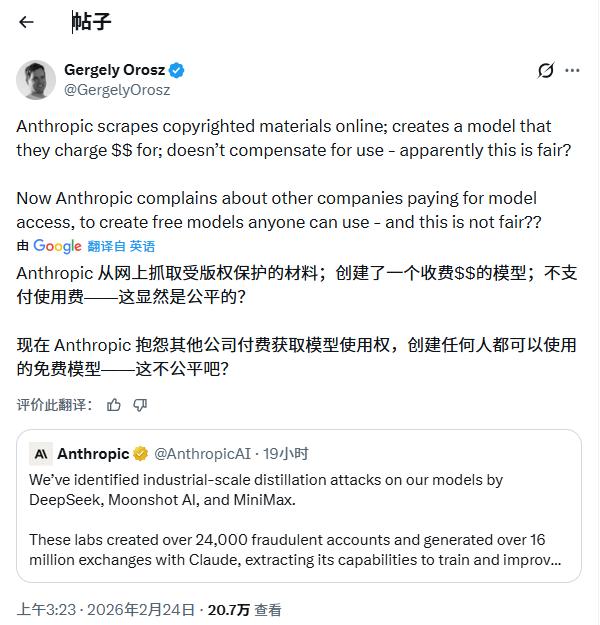
著名程序员、科技博主GergelyOrosz也发表类似看法:“抱歉,但Anthropic不能两面讨好……别忘了Claude是如何训练出来的?用的是受版权保护的书籍,直到被起诉后才向版权方付费。”
程序员社区和网络论坛上,类似质疑声此起彼伏。一位Reddit用户直言:“Anthropic盗版数百万本书籍,现在却大谈责任与合规……如果你真信他们那套说辞,未免太天真了。”
面对舆论反噬,Anthropic的辩解苍白无力,称训练数据包含部分合法来源,且已通过支付15亿美元和解金“解决”历史问题。
这套逻辑显然无法服众,支付罚款或和解金本质是对过往侵权行为的补偿,或许能了结法律纠纷,却无法抹去行为本身的不道德性。
这就像小偷被抓后退还赃物并缴罚款,转头就义愤填膺指责别人偷他东西,无论从哪个角度看都缺乏说服力。
更深层次的问题在于,Anthropic支付的15亿美元,究竟是真心悔过的“赔偿”,还是迫于无奈的“赎罪券”,抑或是获取海量高质量数据的“成本”?从其如今高高在上的道德姿态看,后者可能性更大。
他们似乎认为,一旦花钱“摆平”过去,就获得了道德新生,可站在制高点审判他人。
然而,互联网是有记忆的。
不过将Anthropic案例放大到整个AI行业,会发现更普遍的困境:几乎所有头部大模型公司的崛起,都离不开对海量互联网数据的“野蛮”抓取,其中必然包含大量受版权保护的内容,这几乎是整个行业的“原罪”。
从OpenAI到Google再到Anthropic,它们的模型能展现惊人智能,正是因为“阅读”了人类有史以来几乎所有公开文本和图像。在此过程中,是否获得每一份资料的授权,是被刻意模糊的问题。
但Anthropic的特殊之处,仅在于它做得太过火,直接端掉整个盗版图书馆,还被抓个正着,最终付出沉重代价。
从这个角度看,Anthropic对国内公司的指控,暴露了AI巨头们危险的双重标准:“我可以用全世界的数据训练我的模型,但你不能用我的模型输出来训练你的模型。”
这背后既有商业利益考量,也有地缘政治影子。
商业上,AI大模型公司正试图构建全新商业模式闭环,通过提供API服务将模型“智能”作为可计价商品出售。
若允许竞争对手通过“蒸馏”低成本复制这种智能,整个商业模式根基都会被动摇。因此,它们必须将“蒸馏”定义为非法行为,动用一切舆论和法律工具打击。
地缘政治层面,Anthropic的指控完美契合老美延缓国内AI技术发展的战略意图,通过将商业竞争上升为“技术盗窃”,为进一步技术封锁和出口管制制造舆论基础。
这使得Anthropic的商业行为带上浓厚“政治正确”色彩,既能打击竞争对手,又能迎合国内政治气候。
然而,这种建立在双重标准之上的指控,终将反噬自身。当行业领导者本身通过打破规则、游走法律边缘获得优势时,就丧失了为整个行业制定规则的合法性。
对于Anthropic来说,在教育别人如何“负责任”之前,或许应先向公众更坦诚地解释:自己正义凛然的“捉贼人”面孔下,曾是北美最大的AI“偷子”。
本文来自微信公众号“超聚焦foci”,作者:方文三,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com