
DeepSeek无需成为救世主






本文来自微信公众号:未尽研究,作者:未尽研究,原文标题:《DeepSeek不必是救世主 | 以Agent为马》
去年春节前夕,DeepSeek发布的R1模型震撼硅谷、牵动华尔街神经。它为中国大模型厂商重新专注研发与训练验证了可行路径,也开启了中国开源模型阵营狂飙突进的一年。
春节已成为新一年AI领域的前哨战。近期,Kimi、智谱、MiniMax与豆包等厂商,都赶在春节前发布了旗舰模型。外界猜测,它们担心若发布滞后,会在品牌形象与市场竞争中落于下风。
前沿模型“智能”水平排名
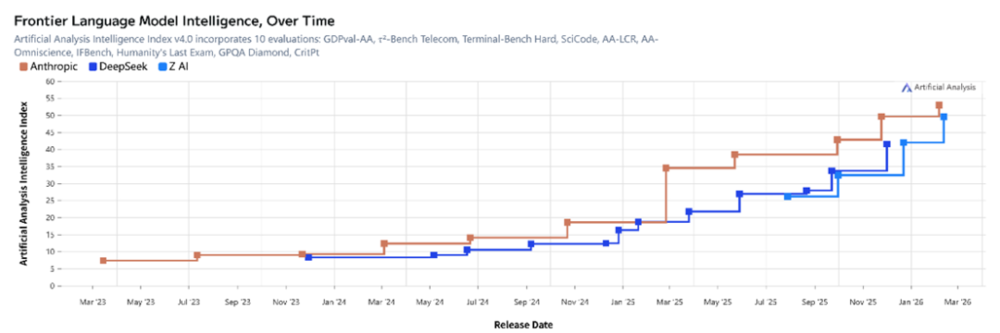
(根据ArtificialAnalysis,当前美国最强模型来自Anthropic,中国最强模型来自智谱)
如今,市场的目光聚焦于DeepSeek,期待它延续春节“英雄”的角色,甚至承担起中国AI生态“救世主”的重任。DeepSeek该如何回应这份期待?或者说,它必须回应吗?
DeepSeek确实在酝酿新动作。全新长文本模型结构测试正在推进,支持最高100万token上下文。这会是市场期待的DeepSeek-V4吗?事实上,去年5月、8月、10月与12月,市场曾多次抱有类似期待,最终DeepSeek推出了DeepSeek-R1-0528、DeepSeek-V3.1、DeepSeek-V3.2-Exp与DeepSeek-V3.2。
在此期间,DeepSeek还尝试了UE8M0 FP8、DSA、上下文光学压缩、mHC与Engram等技术方向的探索,核心思路之一是“稀疏化”,让“专家”“精度”“注意力”与“记忆”更具稀疏性。人们相信,即将到来的V4版本中,能看到这些改良技术的延续。
不过,市场的关注点已转向智能体(AI Agent),更准确地说是智能体化(Agentic AI)。这一方向追求自主决策、长期任务规划、智能体间交互及端到端执行的新范式。Anthropic表示,AI已能完成90%的代码编写,下一步便是实现90%端到端的软件工程(SWE)。火爆的OpenClaw让人们意识到,在获得足够权限后,Agentic应用的强大与潜在风险。
2026年的旗舰大模型,将以原生Agentic大模型为主。美国方面,Anthropic的Claude Opus 4.6与OpenAI的GPT-5.3-Codex相继上线,尤其是OpenAI推出的1000token/秒的Codex-Spark,将编码竞争推向白热化。国内,月之暗面的Kimi-K2.5、智谱的GLM-5、稀宇科技的MiniMax-M2.5以及字节跳动的Doubao-Seed-2.0,都在宣传自身的智能体能力。
其中,Kimi-K2.5引入智能体集群(Agent Swarm)技术,提出并行智能体强化学习(PARL),实现更高准确率与更短用时;GLM-5在编程能力上与Claude Opus 4.5对齐,还提出异步智能体强化学习算法,使模型能从长程交互中持续学习,以极少人工干预自主完成Agentic长程规划与执行;MiniMax-M2.5号称是首个无需考虑使用成本、可无限使用的前沿模型,“1万美元可让4个Agent连续工作一年”。
DeepSeek-V3.1早已宣告迈向Agent时代,但其将如何定义当下的Agentic时代?能否凭借推理效率、工具集成、记忆机制与极致经济性,在落地体验中再次树立新标杆?
或许,DeepSeek未必需要单独的“R系列”。R象征推理与认知,对标OpenAI的o系列模型;而Agentic时代更强调执行与工程,需对标OpenAI的Codex。DeepSeek原本就有Coder与Math系列模型,编码与数理证明是通往AGI(通用人工智能)的“元能力”,二者共同构成模型的自我改进系统,加速递归式进化。
市场也期待DeepSeek继续验证国产算力生态协同的潜力。长期以来,其探索主线是在有限资源下通过架构创新,最大化提升训练与推理效率。去年年底,DeepSeek-V3.2采用新架构DSA,在长上下文场景中实现端到端显著加速;今年年初,Engram的条件记忆有望“成为下一代稀疏大模型中不可或缺的基础建模范式”。
OpenAI的Codex-Spark证明响应速度至关重要,是创造价值的关键。它运行在Cerebras晶圆级引擎上,而这正是国内推理生态所缺乏的。DeepSeek能否用“算法”换“算力”,弥补硬件层面的差距?
而且,从算法入手精简步骤,不仅能提升响应速度(尤其是部分需高速精准响应的场景),还能减轻上下文压力。此前,中国开源模型常因“冗长思考”不受制约、token消耗过高而被诟病,这会逐渐削弱成本优势。DeepSeek曾提到,未来将聚焦提升模型推理链的智能密度,以改善效率。
比推理更重要的是训练,预训练仍是后训练的起点。英伟达的Blackwell架构正成为美国AI基础设施中的训练主力,谷歌的TPUv7也将在Gemini 4的训练中发挥关键作用。即便H200能尽快在国内部署,短期内中国大模型训练的算力来源仍处于Hopper时代。目前,国内AI芯片厂商的性能宣传主要围绕Hopper架构,但在大规模集群场景下的稳定性与综合效率表现,尚未有充分实践数据支持。
DeepSeek在论文中承认,因训练算力不足,DeepSeek-V3.2在世界知识覆盖广度上仍落后于领先的专有闭源模型。团队计划在后续迭代中扩大预训练算力规模,弥补这一知识差距。毋庸置疑,DeepSeek-V4发布时,国产AI芯片会实现Day0深度全栈适配;但市场更期待其预训练基于国产AI芯片,再次改写市场对英伟达叙事的定价。
人们欣赏DeepSeek的精致研究,也期待原生多模态的DeepSeek-V4。Gemini 3已是原生支持文本、图像、音频和视频输入的大模型,Kimi-2.5也强调文本与视觉的联合优化。要继续对标谷歌、OpenAI,DeepSeek似乎必须有所行动。
然而,技术创新必须基于可验证的物理边界,而非情绪边界。芯片、能源、网络及算法等整套生态决定了算力上限,而算力正限制中国开源模型进一步追赶的后劲,这在预训练和后训练中已有所体现。任何“算法乐观主义”在特定时间内,都只能在这一边界内优化。AGI更是一项系统工程,远超单一大模型的参数规模或版本更新。
DeepSeek的使命是探索AGI。仅做大模型(尤其是仅做语言大模型)无法实现AGI,其局限性日益明显。现在更接近现实的AGI形态是知行合一的,具备认知能力、执行能力、长期约束、现实反馈闭环等。Claude大模型常被中国开源模型集体刷榜超越,但它的收入以每年十倍的速度增长,在编程这一通用功能领域的突破,为通往AGI开辟了新路径。
或许,真正的长期主义期待是允许DeepSeek继续深度探索,而非让市场的所有焦虑与愿望在某一时刻集中投射到这一品牌上。公司创始人梁文锋认为,创新是昂贵且低效的,有时伴随浪费,需要尽可能少的干预和管理,让每个人有自由发挥的空间和试错机会。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com