
Gemini 3新增智能体视觉能力 以代码执行实现像素级图像操控





【导读】Google DeepMind为Gemini 3 Flash赋予智能体视觉能力,通过代码执行让AI从被动看图像转向主动深度调查。
Google DeepMind刚为Gemini 3 Flash上线重量级能力——Agentic Vision(智能体视觉),这一技术彻底改变了大语言模型理解世界的模式:从过去的‘猜’变为如今的‘深度调查’。

该能力由Google DeepMind团队打造,核心产品经理Rohan Doshi介绍,传统AI模型处理图片时多为静态观察,遇到微芯片序列号、模糊路牌等细节时只能依赖猜测。而Agentic Vision引入‘思考-行动-观察’闭环,让模型能主动操纵图像获取清晰信息。
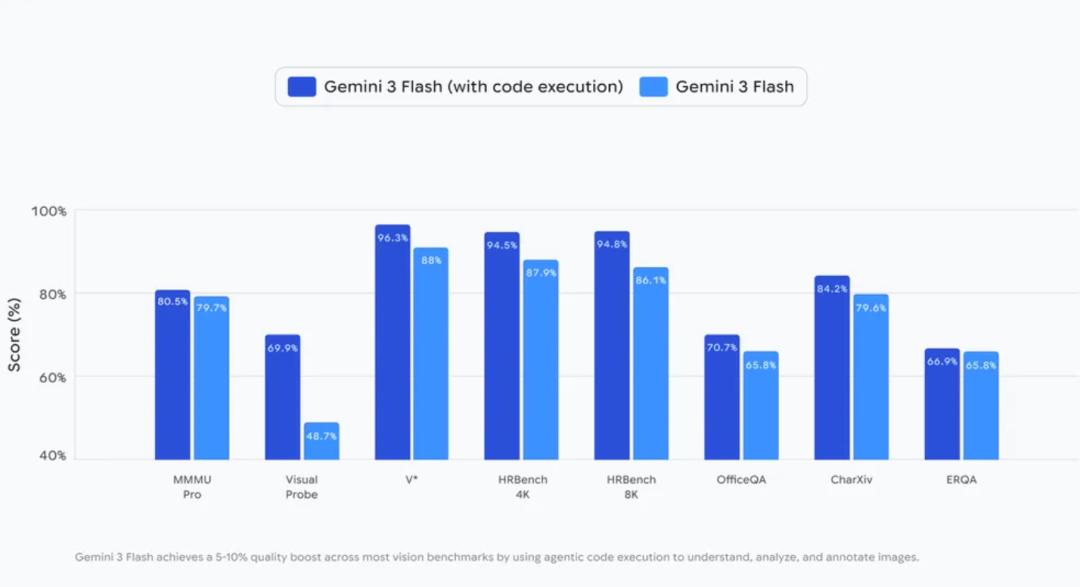
这项能力使Gemini 3 Flash在各类视觉基准测试中性能提升5%至10%。
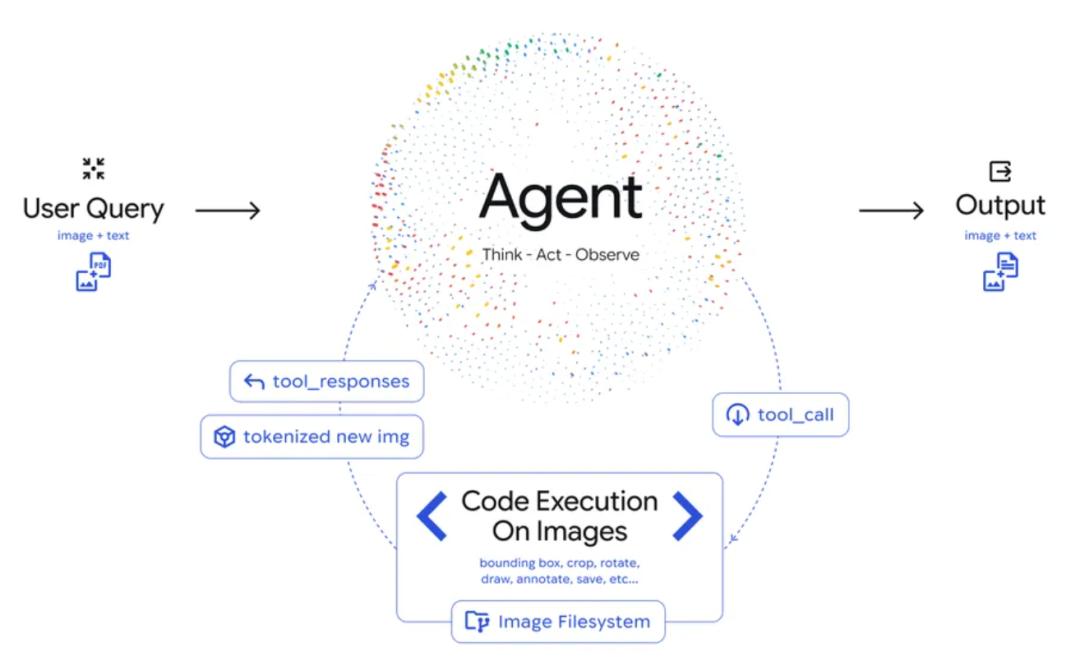
Agentic Vision:智能体视觉新方向
DeepMind的方法核心是将代码执行作为视觉推理工具,把被动视觉理解转化为主动智能体过程。当前SOTA模型通常一次性处理图像,而Agentic Vision构建了循环机制:
1.思考(Think):模型分析用户查询与初始图像,制定多步计划。
2.行动(Act):生成并执行Python代码,主动进行图像裁剪、旋转、标注或分析计算、计数边界框等操作。
3.观察(Observe):变换后的图像被添加到上下文窗口,让模型在生成最终响应前获取更充分的信息。
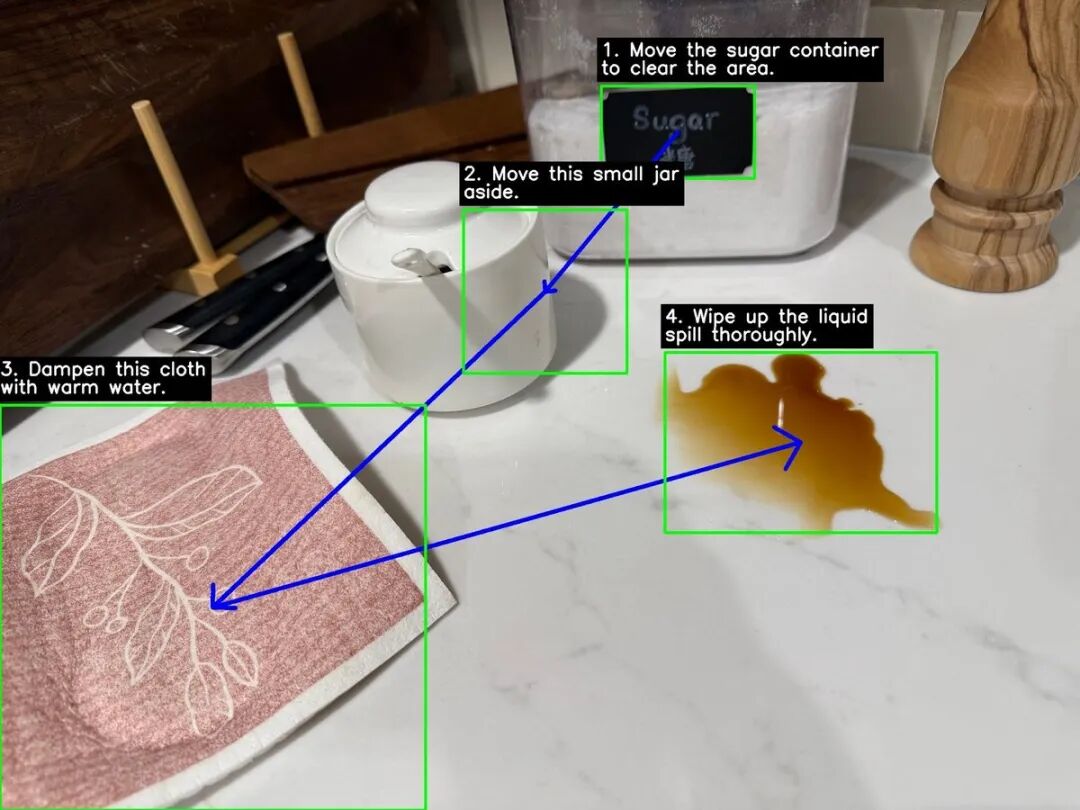
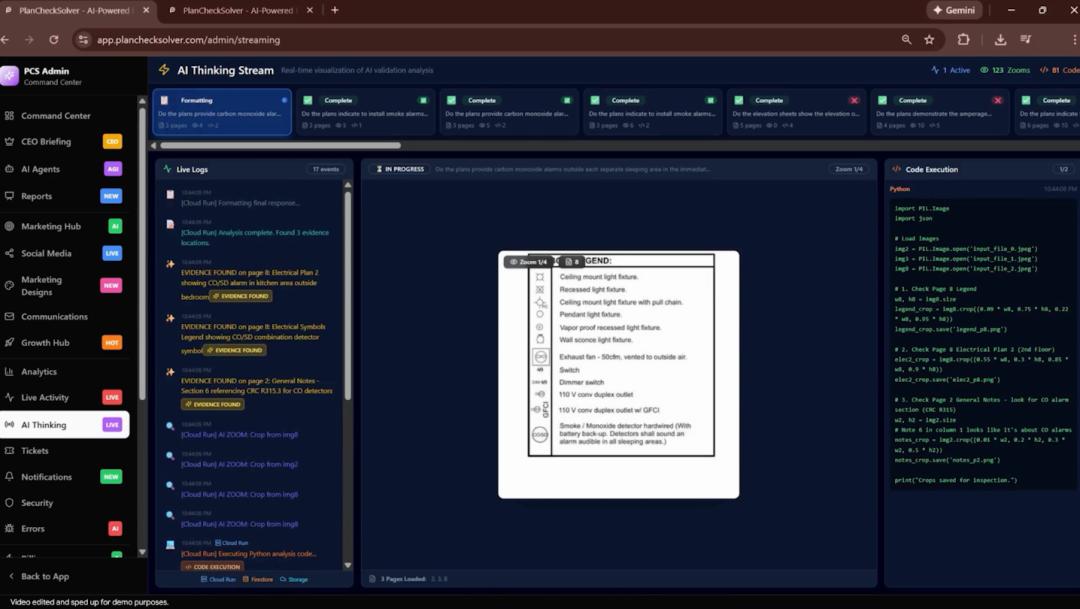
Agentic Vision实际应用
开启API代码执行功能后,开发者可解锁多种新行为,Google AI Studio的演示应用已展示相关效果:
1. 缩放检查
Gemini 3 Flash能在检测到细粒度细节时自动缩放。建筑计划验证平台PlanCheckSolver.com启用该功能后,通过迭代检查高分辨率输入,准确率提升5%。后台日志显示,模型生成Python代码裁剪分析屋顶边缘等特定区域,将结果追加到上下文以确认是否符合建筑规范。
2. 图像标注
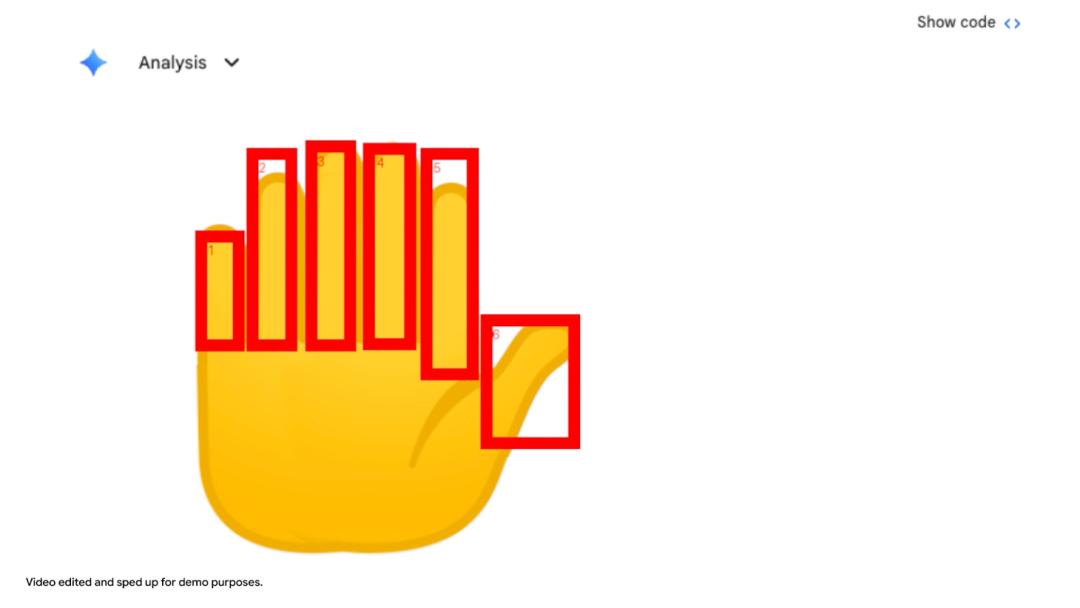
模型可通过标注与图像交互。例如数Gemini应用中手上的数字时,它用Python在每个手指上绘制边界框和数字标签,以‘视觉草稿纸’确保答案基于像素级理解。
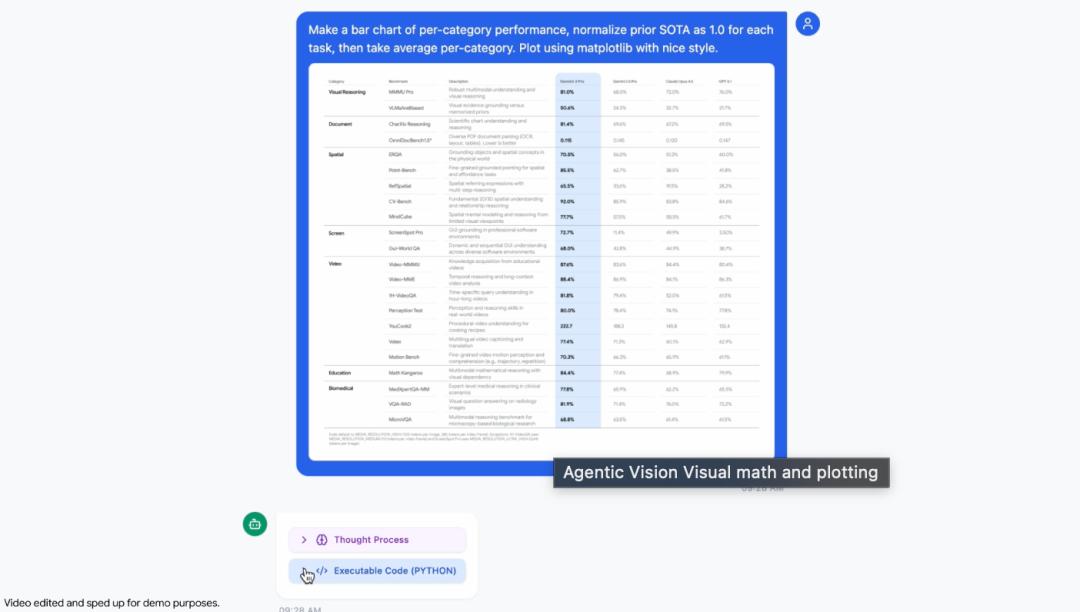
3. 视觉数学与绘图
模型能解析高密度表格并执行Python代码可视化结果。标准LLM在多步视觉算术中易出错,而Gemini 3 Flash通过确定性Python环境避免问题。演示中它识别原始数据,编写代码将SOTA结果归一化为1.0,生成专业Matplotlib条形图。
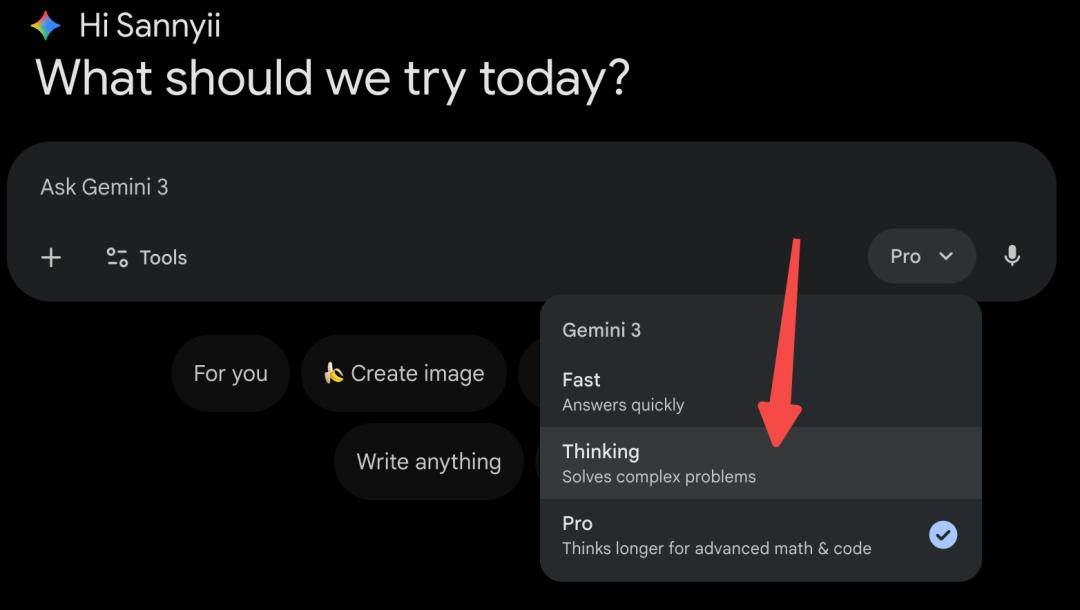
使用指南
Agentic Vision现已通过Google AI Studio和Vertex AI的Gemini API提供,也开始在Gemini应用中推出(从模型下拉菜单选Thinking访问)。
以下是调用该能力的Python代码示例:
- fromgoogleimportgenai
- fromgoogle.genaiimporttypes
- client = genai.Client()
- image = types.Part.from_uri(
- file_uri="https://goo.gle/instrument-img",
- mime_type="image/jpeg",
- )
- response = client.models.generate_content(
- model="gemini-3-flash-preview",
- contents=[image,"Zoom into the expression pedals and tell me how many pedals are there?"],
- config=types.GenerateContentConfig(
- tools=[types.Tool(code_execution=types.ToolCodeExecution)]
- ),
- )
- print(response.text)
未来发展
Google表示Agentic Vision尚处初期阶段。目前Gemini 3 Flash能自动判断何时放大细节,旋转图像、视觉数学等功能需显式提示触发,未来将实现完全自动化。此外,团队还在探索为模型添加网络搜索、反向图像搜索等工具,并计划扩展到更多模型尺寸。
彩蛋:与DeepSeek的关联?
值得注意的是,DeepSeek刚开源DeepSeek-OCR2,谷歌就发布了Agentic Vision,时间点巧合引发猜测。推测谷歌此次更新或受DeepSeek推动,理由如下:
1.时间契合:1月27日DeepSeek发布DeepSeek-OCR2,同日谷歌推出Agentic Vision,似在视觉技术竞争中回应。
2.技术路线竞争:DeepSeek-OCR2通过DeepEncoder V2让AI按逻辑阅读,谷歌则用代码执行实现主动操作,分别代表感知优化与交互能力提升两条路线。
3.定义机器视觉:DeepSeek-OCR2证明小模型优化视觉逻辑可超越大模型,谷歌则以代码执行强化理解深度,双方争夺机器视觉的定义权。
无论是否为竞争驱动,这场技术比拼都将惠及开发者。
参考资料:
https://blog.google/innovation-and-ai/technology/developers-tools/agentic-vision-gemini-3-flash/?linkId=43682412
本文来自微信公众号“新智元”,编辑:定慧,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com