
国产首个对标Gemini3的大模型来了!阿里千问Qwen3-Max-Thinking实测体验





国产首个对标Gemini3的大模型,正式亮相。
1月26日,阿里巴巴发布了旗下旗舰推理模型Qwen3-Max-Thinking。
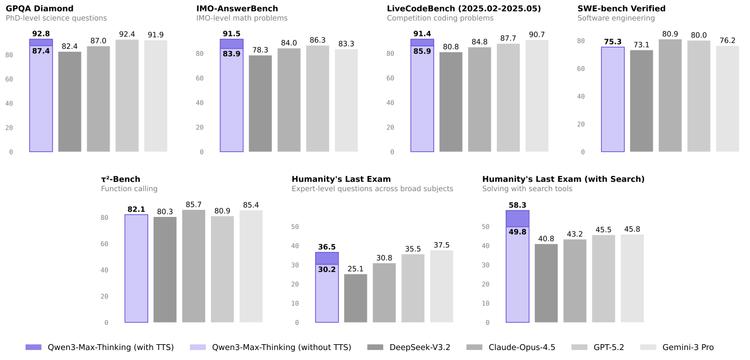
该模型总参数超万亿,预训练数据量达36T Tokens,在科学知识(GPQA Diamond)、数学推理(IMO-AnswerBench)、代码编程(LiveCodeBench)等权威评测中刷新全球纪录。它在数学推理AIME 25和HMMT 25中斩获国内首个双满分,在HLE测试中得分58.3,大幅领先GPT-5.2-Thinking的45.5与Gemini 3 Pro的45.8。
从发布时机来看,当前AI圈各大厂商均在蓄力,阿里此时推出Qwen3-Max-Thinking,显然意在抢占“国产首个Gemini 3级大模型”的先机。
尽管评测数据亮眼,但它能否真正媲美Gemini3?
测试发现,Qwen生成代码的初期失败率较高,但在阿里熟悉的电商场景中表现突出。例如搭建水果电商网站时,商品分类、购物车、结算等功能可一次完成,逻辑完整且体验流畅,这得益于淘宝天猫的海量场景数据积累。
不过在其他领域,成功率稳定性不足。若需求契合其优势场景,体验较好;反之则需多次调整提示词。
针对Gemini 3曾展示的体感控制打气球游戏案例(通过摄像头实现手势控制准星、捏合动作射击,包含天空背景、云层漂移、击中特效、连击反馈等细节),Qwen的表现令人意外。
千问的表现超出预期。游戏框架一次搭建完成:天空渐变背景、气球从底部生成并上升、不同大小气球速度各异、UI显示分数与连击数,基础逻辑均无问题。
交互设计颇具巧思。伸出食指时准星随手指移动,拇指与食指捏合即可开火。击中气球瞬间屏幕轻微震动,气球爆炸有粒子特效与“啵”的音效,反馈感充足。连续击中会显示combo数字,即时反馈增强代入感。
但实际操作存在明显缺陷:瞄准精度不足。手指对准气球时,准星位置常出现偏差,需多次尝试才能命中。这可能源于手部追踪与屏幕坐标映射的偏差,或校准算法精度不足。尽管Qwen实现了体感控制全流程(摄像头调用、手势识别、射击反馈等环节均打通),但核心的“指哪打哪”精度未达理想效果,影响游戏体验。
Qwen3-Max-Thinking的核心突破并非参数规模,而是推理方式的革新。该模型采用全新的测试时扩展(Test-time Scaling)机制,在提升推理性能的同时兼顾经济性。
传统AI解题方式类似“多答案投票”:生成10份答案后选择支持率最高的,但这种方法算力消耗大且易出现共性错误。Qwen3则采用类人思维:先完成解题,再复盘修正,如同人类使用错题本,二次解题准确率更高。这使其在工具使用测试中得分58.3,远超Gemini的45.8。
在工具调用方面,Qwen将工具使用能力“训练内化”。通义团队先通过微调教会模型使用工具,再在多样化任务中进行规则奖励与模型奖励的联合强化学习,使模型具备智能结合工具思考的能力。
这种三步训练法(工具使用教学→强化练习→形成条件反射)的优势在于:工具调用更高效流畅,无需重复学习工具说明,且模型能自主判断工具使用时机。这正是Qwen在HLE测试中领先12分的关键,尤其在连续使用多工具解决复杂问题时,这种“肌肉记忆”优势更为明显。
相比之下,Gemini采用传统软件工程思路:模型负责理解意图,工具调用依赖外部API框架。这种方式灵活性强(如接入沃尔玛购物功能无需重新训练模型),但每次调用需经过“意图理解→API翻译→执行→结果解析”流程,效率低且易出错。
Qwen的代码生成能力已超越“语法翻译器”,更接近理解需求的技术伙伴。它不仅能将需求转化为可运行代码,还具备工程直觉:懂得何时优化性能、简化实现或添加容错机制。
这种对“度”的把握,是AI从“工具”向“协作者”进化的关键标志。
本文来自微信公众号“硅星人Pro”,作者:Yoky,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com