
从对话智能到决策支撑:百川M3引领医疗大模型迈入新阶段








1月13日,百川智能发布并开源新一代医疗增强大模型Baichuan-M3。该模型在OpenAI主导的权威医疗评测集HealthBench及其困难子集上斩获全球最高综合成绩,显著超越GPT-5.2;在医疗幻觉率纯模型评估中达到当前最低水平;在聚焦全流程临床能力的SCAN-bench评测里,M3在病史采集、辅助检查和诊断等多个核心指标上均位列第一,展现出综合领先的医疗推理与问诊能力。
此外,M3首次具备原生的“端到端”严肃问诊能力。它能像医生般主动追问、逐层深入,挖掘关键病史与风险信号,进而基于完整信息开展深度医学推理。评测显示,其问诊能力明显高于真人医生的平均水平。
这场发布的意义不止于技术榜单上的超越。更重要的是,Baichuan-M3将医疗大模型推向新高度:它不再局限于对话和表达层面,而是开始真正具备支撑完整诊疗流程的能力,能够参与医疗决策本身。正因如此,其意义远超其他模型,大模型的技术进步终于能完整转化为医疗健康领域可规模化落地的现实价值。
“帮助患者产生辅助决策的价值就是有意义的。”百川智能创始人&CEO王小川在发布会上表示。

在医疗这个对安全性和责任要求极高的场景中,这样的变化并非偶然。它意味着有人选择了一条更漫长、更艰难且不那么讨巧的路径,将模型能力从展示智能逐步推向承载决策。
百川为何能实现这一突破?为何此次突破出现在医疗领域,而非代码、搜索或智能体等更热门赛道?又为何在当下,这些长期积累的技术选择与工程路线能同时收敛于清晰结果?
医疗大模型评价标准迎来重构
几乎从人工智能诞生起,医疗行业就被视为最有可能且最值得被AI改造的行业之一。
在HealthBench出现前,医疗相关AI能力几乎无法比较。各家模型都可宣称懂医学、能做医疗问答,但缺乏统一评价体系,难以横向对比。
今年5月,OpenAI推出HealthBench,这套标准汇集大量基于真实临床场景设计的多轮对话样本,让医疗能力得以量化评估,有了公共标准。因此在相当长一段时间里,它几乎等同于医疗大模型的最高标准,也成为各家模型展示医疗能力的共同参照系。
正因如此,在相当长一段时间里,谁在HealthBench上得分更高,谁就更懂医疗,几乎成了行业共识。这并非因为HealthBench覆盖了医疗的全部复杂性,而是因为在它之前,行业连标准本身都没有。
从某一时刻起,行业趋势发生转变。去年年中至今,当国内阿福、小荷医生等医疗助手纷纷上线,OpenAI推出ChatGPT Health,Anthropic推出Claude for Healthcare,医疗不再只是测试模型智能程度的benchmark,而成为大模型厂商必须正面投入的产品方向;模型也要直接面对回答能否作为决策依据的问题。
这不再只是排名问题。
也正是在这个阶段,HealthBench的局限性开始显现。它依然重要,但已不够全面。它能证明模型是否具备医学知识和专业表达能力,却无法回答更核心的问题:模型是否具备进入真实医疗决策流程的资格。
临床决策从来不是从标准化问题开始,而是从高度不完整、甚至混乱的信息开始。患者往往说不清重点,症状相互叠加,不同风险混杂,真正的难点不在于“怎么给答案”,而在于“怎么问问题”。医生的专业能力,很大一部分体现在对信息优先级的判断上:哪些是必须马上排除的高危信号,哪些可以暂缓;哪些信息缺失就无法下结论,哪些只是补充参考。
也正是在这一点上,百川做出了与主流路线明显不同的选择。一方面,它没有放弃在HealthBench体系中的竞争,仍持续追求在现有权威标准下做到最优;另一方面,它推出SCAN-bench,试图弥补对完整临床流程建模和评测这一此前长期被忽视的维度。
围绕SCAN原则,百川借鉴医学教育中常用的OSCE方法,联合150多位一线医生搭建SCAN-bench评测体系。该体系以真实临床经验为“标准答案”,将诊疗过程拆解为病史采集、辅助检查、精准诊断三大阶段,通过动态、多轮方式考核,完整模拟医生从接诊到确诊的全过程。相比于HealthBench,SCAN-bench是更全流程端到端的动态评测新范式。
也就是说,当行业还在比拼谁更会“答”时,百川已将关注点转向更底层的问题:模型能不能像医生一样“问”?
这正是M3发布真正特殊之处:在能力结构上形成闭环,既能推理,又不虚构,还知道如何问出关键信息。会推理解决“能不能判断”,不虚构解决“能不能信”,会问诊解决“有没有资格进入决策流程”。
当这三者同时具备时,医疗大模型才算从会说话的智能系统,走向可被托付部分医疗决策责任的系统。
从结果来看,M3仍是一款多项第一的模型。它在HealthBench上登顶,意味着在OpenAI亲自定义的医疗能力标准体系下实现全面超越;而在更强调复杂临床决策能力的HealthBench Hard子集中,M3以44.4分夺冠,首次系统性超过GPT-5.2,这一成绩更具说服力,因为它验证的不只是回答是否专业,更是模型在高度不确定、高推理难度场景中的稳定性与可靠性。
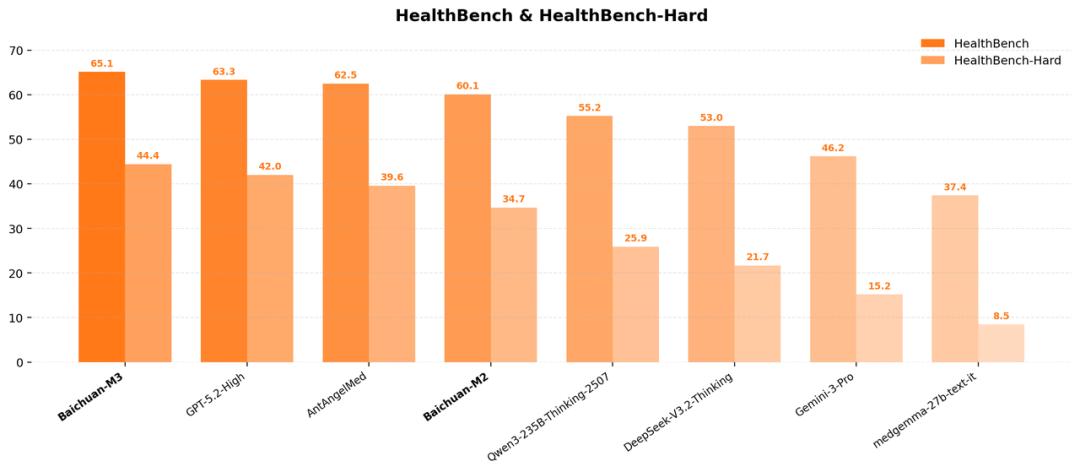
同时,M3在无工具条件下实现全球最低幻觉率,意味着安全性被内化为模型自身能力,而非依赖外部检索、规则约束或工程补丁来弥补。更关键的是,在以完整临床流程为目标的SCAN-bench评测中,M3同样取得第一,尤其在最核心的问诊环节显著超过GPT系列模型和人类医生基线水平,这表明模型真正补齐了临床信息获取这一长期被忽视、却决定医疗决策上限的核心能力。
AI医疗的真正分水岭
如果说过去两年行业更多是让模型“像”医生一样说话,那M3此次给出的判断是:仅有表达还不够,必须具备医生的思维结构。
大量“AI医生”仍停留在角色扮演层面,对话流畅、语气专业,但提问更多是让对话显得完整,而非为临床决策收集关键信息。模型往往顺着患者描述展开对话,却很少像真实医生那样先做风险分层、排查危险信号、围绕诊疗路径反向设计问题。结果是,对话看似专业,却不足以支撑严肃判断,最终只能给出“建议尽快就医”这样的安全性结论。
这正是“会说话”和“会做临床决策”的本质差别,也是百川提出“严肃问诊”“SCAN原则”的背景。王小川在发布会上分享:“在医疗行业,患者往往无法完整表达自己,只知道表面症状,所以要去问医生,通过问诊把过去的病情发展问清楚。有了足够数据后,才能做好后续的检测、诊断和结论。今天的大模型并不具备这样的能力。”
百川想做的是将临床医生长期依赖经验完成的工作方式,拆解成可被模型学习、评测和通过强化学习直接优化的工程目标。
具体到工程上,百川没有选择堆砌功能,而是集中解决三个最底层的问题。
首先是全动态强化学习系统。
在M2阶段,强化学习更多依赖相对静态的验证规则,模型能力提升到一定程度后,验证体系本身就成了上限。而在M3中,Verifier被设计成可随模型能力共同进化的系统:模型暴露出新的错误模式,验证器就生成新的约束;旧的、低价值规则被淘汰,高价值规则被持续强化。规则与模型共同抬高上限,解决了能力后期容易封顶的问题。
第二是SPAR算法。
医疗问诊天然是一条极长的决策链路,如果只看最终诊断是否正确,模型根本无法知道问题出在哪里:是病史没问清,还是检查建议错了,或是推理路径偏了。SPAR通过分步惩罚和相对基准机制,把长链条决策拆解为可追责的局部过程,让模型在有限轮次内就能学会把关键问题问准、问全,而不是靠拉长对话轮数。
第三是Fact-aware RL。在医疗场景中,推理能力越强,模型越容易“肯定自己”;说得越肯定,一旦事实基础不牢,就越危险。传统做法往往是靠外部检索或规则系统纠偏,而M3把低幻觉直接作为强化学习的优化目标,让事实一致性成为模型自身能力的一部分。同时,通过动态权重调节,避免模型为了少犯错而退化成少说少错的保守状态,使强推理与高可靠能够同时实现。
这三套设计背后,指向的是同一个目标:能力和安全,强推理和高可靠,不做取舍,百川都要,并且要让二者成为同一套工程体系里的协同指标。
这样一来,AI医疗才真正跨过了那条分水岭。
从健康助手到决策支持
当模型能力完成会推理、不虚构、会问诊的完整闭环时,百川的重心也必然开始转变:从模型本身的展示,转向能力在真实医疗场景中的落地。
这也是为什么从外部观察会发现,百小应近期的产品节奏明显加快,多种功能陆续完善,逐步搭建起可以承接医疗工作流的系统框架。模型需要的不再是展示窗口,而是一个可以沉淀信息、支持长期使用、对接真实决策链条的载体。
这样一来,百川所坚持的“严肃医疗”与行业中大量“泛健康”产品之间的差异,开始变得格外清晰。
以阿福、小荷医生为代表的产品,更接近健康咨询、医学科普、导诊建议和情绪陪伴,它们解决的是信息不对称和患者就医前焦虑的问题。
而百川试图进入的,是完全不同的链路:医生可借助它推演问诊与诊疗思路,患者及家属也可通过该应用更系统地理解诊断、治疗、检查与预后背后的医学逻辑。
这是一条高风险、高责任、高价值密度的决策支持路径:在这里,模型不再只是提供参考信息或情绪安慰,它给出的每一次判断,都可能影响患者的下一步选择;它提出的每一个问题,都在决定关键信息是否被完整收集;它形成的每一个结论,都必须具备可复核性,能够真正被纳入医疗决策流程之中。
根本区别在于,当行业里大多数产品仍停留在帮用户搜集健康信息层面时,百川选择了一条更难、更慢但天花板更高的路。
回看百川押注医疗的时间线,其选择是一种提前布局的判断。
在沟通会上,王小川概括了他对医疗行业几个核心痛点的判断:优质医生资源长期紧缺,医疗服务在不同地区与人群之间高度不均衡;在美国有家庭医生体系承接基层诊疗,而在中国,患者更集中地涌向三甲医院,优质医疗资源被进一步挤压。正是基于对这些现实矛盾的长期观察,百川从一开始就把目标放在解决医疗本身的问题上。
2023年,在大模型产业最火热的阶段,百川并没有选择优先切入代码、搜索、内容创作这些更容易验证商业化价值的赛道,而是明确把医疗作为最核心方向。这在当时并不讨巧:医疗数据敏感、场景复杂、责任边界模糊、产品落地周期长,很难形成快速反馈。“当时也受到行业很多人的质疑。”王小川告诉我们。
2026年开年,OpenAI发布ChatGPT Health,Anthropic也正式推出Claude for Healthcare,国际头部模型厂商开始集体进入医疗领域,全球范围内所有公司都意识到医疗才是大模型必争之地。
在这场竞速中,作为国内唯一专注医疗的大模型企业,百川持续突破低幻觉率、端到端问诊和复杂临床推理等核心能力,在医疗大模型底座上完成了代际领先,已从“跟随者”跃迁为行业“引领者”与新范式的“定义者”,正以硬核实力扛起中国AI医疗发展的旗帜。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com