
英伟达200亿布局推理赛道:携手Groq补短板,应对TPU挑战







Jay 发自 凹非寺量子位 | 公众号 QbitAI
面对谷歌TPU带来的竞争压力,英伟达迅速出手,以200亿美元投资芯片新贵Groq,这一举措既是其面向AI新时代的重要布局,也侧面反映出对新兴芯片技术的重视。
那么,Groq究竟能为英伟达带来什么?知名科技投资人Gavin Baker的分析指出,答案指向英伟达的推理短板。
推理领域,Groq的LPU速度远超GPU、TPU及多数ASIC。

Gavin Baker
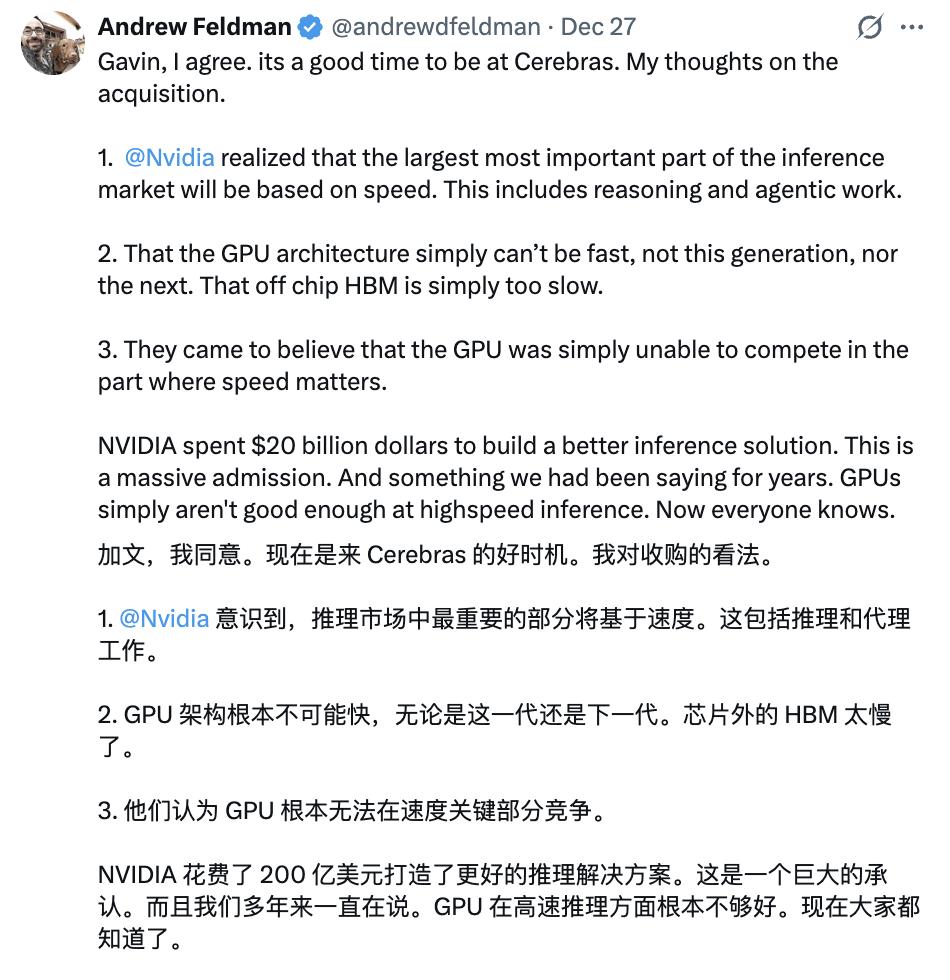
这一观点获网友认可:
GPU架构难以满足推理对低延迟的需求,HBM显存速度是瓶颈。
网友观点
有网友质疑LPU的SRAM在长上下文处理上的局限,Gavin认为可通过产品混搭解决。
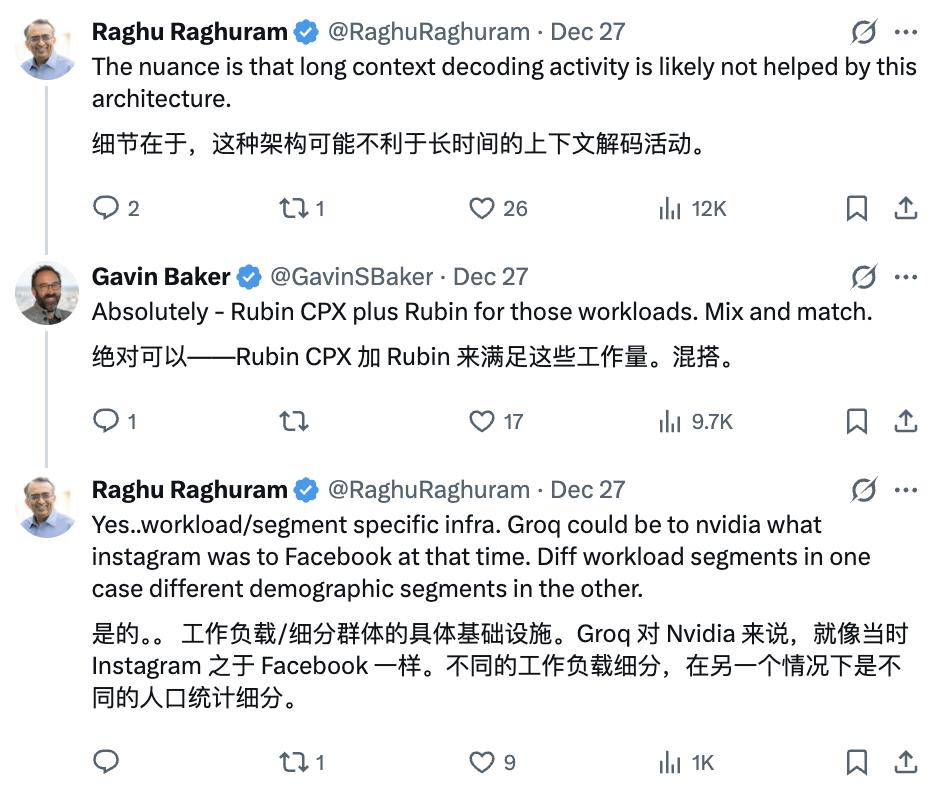
Gavin Baker
具体来看:
Groq:英伟达200亿购入的推理“疫苗”
Gavin指出,GPU在推理场景的适配问题源于prefill和decode两个阶段的不同需求。
prefill阶段:模型“读题”,一次性处理所有输入token,适合GPU的并行计算能力,更需大上下文容量,延迟可通过“思考中”提示掩盖。
decode阶段:串行生成token,用户直观感受输出过程,延迟影响体验。GPU依赖HBM显存,生成每个token需反复读取数据,导致算力闲置、效率低下。
Groq的LPU采用片上SRAM,无需外部读取,速度比GPU快100倍,单用户场景下每秒可生成300-500个token,且能满负荷运行,速度领先GPU、TPU及多数ASIC。
但LPU存在内存短板,单芯片SRAM仅230MB,远低于英伟达H200的141GB HBM3e显存。运行Llama-3 70B模型需数百颗LPU,而GPU仅需2-4张,导致LPU整体硬件成本较高。
用户是否愿为“速度”买单?
从Groq的业绩看,“速度”需求真实且增长迅速。对英伟达而言,这不仅是新业务机会,更是防御竞争的关键——若错失推理风口,可能重蹈当年被颠覆的覆辙。
“铲子”进入新时代
谷歌TPU的成功证明GPU并非AI唯一选择,其自研芯片降低了训练和推理成本。随着AI竞争转向应用层,推理速度成为体验关键。
英伟达投资Groq,既是承认推理短板,也是扩张布局。但推理芯片属于高销量、低利润领域,与GPU 70-80%的毛利率形成反差,英伟达在新赛道或难延续过往优势。
参考链接:[1]https://x.com/gavinsbaker/status/2004562536918598000[2]https://www.uncoveralpha.com/p/the-20-billion-admission-why-nvidia
本文来自微信公众号“量子位”,作者:关注前沿科技,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com