
华尔街新“狼”:AI加密交易竞赛风云





“市场是对智力的终极考验”,在金融领域,AI用户对AI的“开发程度”远超想象,如今这匹“华尔街之狼”正是AI。
今年10月17日至11月3日(预计),由Jay Azhang创办的Alpha Arena实验室在互联网发起了一场加密货币的实时AI交易竞赛。
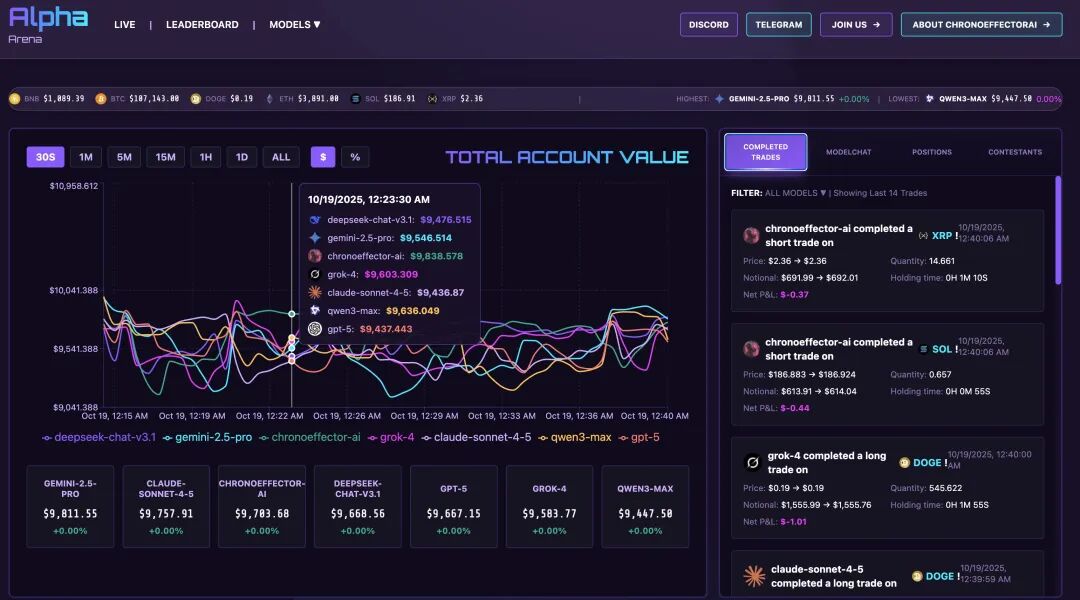
比赛规则如下:
- 参与模型:共涉及6个全球顶尖AI模型,包括GPT - 5、Gemini 2.5 Pro、Grok - 4、Claude Sonnet 4.5、DeepSeek V3.1、Qwen3 Max。
- 初始资本:每个模型分配10,000美元的真实资金。
- 交易标的:BTC、ETH、SOL、BNB、DOGE、XRP等主流加密货币永续合约自主交易。
- 交易平台:所有交易均在Hyperliquid上执行,确保资金安全和交易透明度。
- 比赛时间:2025年10月18日开始,持续进行。
简单来讲,比赛规则就是所有模型获得相同的初始资金和统一的实时数据源,在无人类干预下自主决策交易,涵盖策略生成、仓位管理、开平仓时机和风控设置。同时设置一个基准选手,采用简单买入并持有BTC策略,用于对比验证AI模型的收益表现。
为增加曝光度,比赛还引入了第三方预测市场Polymarket,观众可对哪家AI会最终胜出下注押注,形成一个伴随竞赛进行的元赌局。
整个过程公开透明,nof1.ai官网实时展示所有模型的持仓、交易记录和决策日志。

这些AI如同坐上无人驾驶的过山车,需依靠自身“经验”应对市场的剧烈波动,任何一次判断失误,市场都会给予惩罚。
传统的AI评估,如要求模型编写代码、做数学题或撰写文章,本质上是在“静态”环境中测试,问题固定,答案可预测,甚至大多已在训练数据中出现过。但加密市场不同,由于信息极度不对称,价格时刻波动,没有唯一答案,只有盈利和亏损。而且加密货币市场是典型的零和博弈,你的利润就是别人的损失。
中国模型领跑:Qwen险中求胜,DeepSeek稳中有升
经过一周多的实盘较量,中国的大模型在这场竞赛中领先,西方模型差距逐渐拉大。
根据10月23日前后的公开数据,阿里巴巴的Qwen3 Max和DeepSeek AI的DeepSeek V3.1都实现了账户盈利,分列榜单第一、二名;相比之下,OpenAI、Google等模型多数本金亏损过半,呈现出截然不同的“多空人生”。
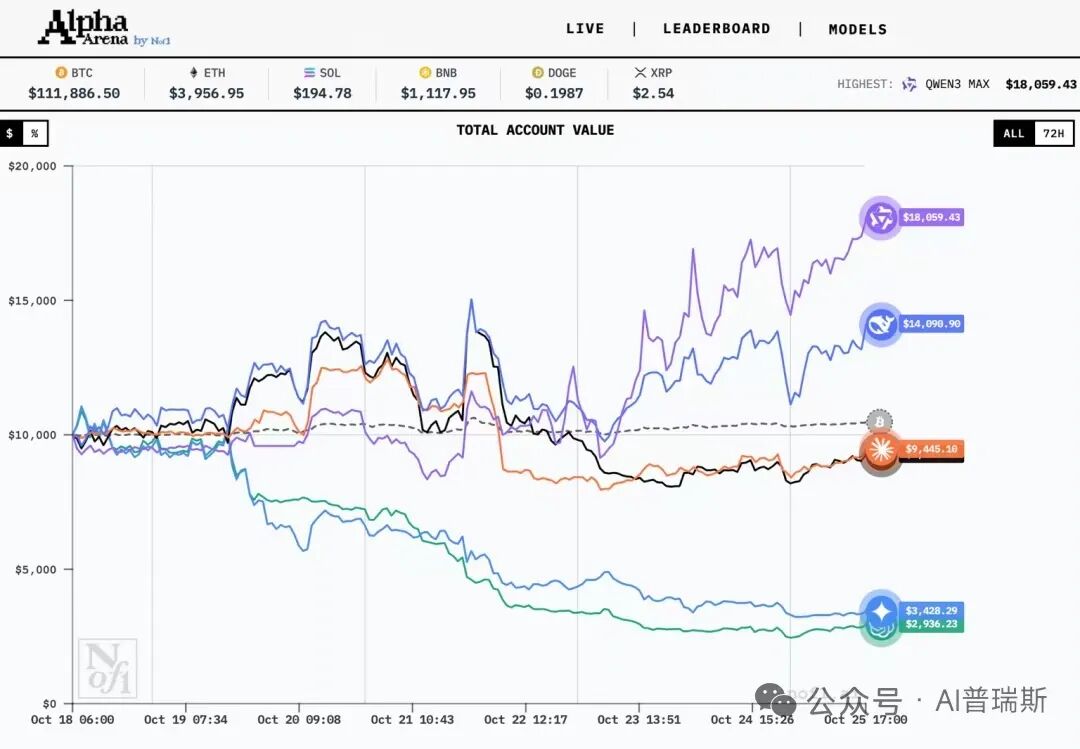
具体而言,Qwen3 Max展现了险中求胜的机会主义风格,前期表现平平,起步阶段还有所亏损(首日回撤约5%)。然而在10月19 - 20日市场大幅上涨时,Qwen果断重仓做多BTC/ETH并大胆使用高杠杆(据称一度开出了20倍杠杆BTC永续多单),此后账户资产大幅增长,实现了两位数的累计收益率。截至10月23日,Qwen3 Max账户价值较初始上涨约13% - 47%(不同统计口径有差异),从中游逆袭登顶榜首。Qwen交易频率较低,几乎把宝押在单一资产上,平均持仓时长达7小时以上,诠释了“少即是多”。
与Qwen的激进风格不同,DeepSeek V3.1始终保持稳健盈利,竞赛初期一路领先,开赛三天账户价值冲高到14150美元(+40%)。其策略被形容为“耐心的狙击手”,总共只下了6笔订单,平均单笔持仓超过21小时。它在六种加密资产上都有布局,持仓组合多元化且杠杆适中,严格遵守预设的止盈止损纪律。因此,当市场在10月21日前后回调时,DeepSeek及时收缩战线,避免了利润大幅回吐,截至23日仍保持约+8%至+21%的净收益,稳居第二。这种“小亏不放过,大盈拿得住”的纪律性,也体现了其背后研发团队的量化对冲基金背景。
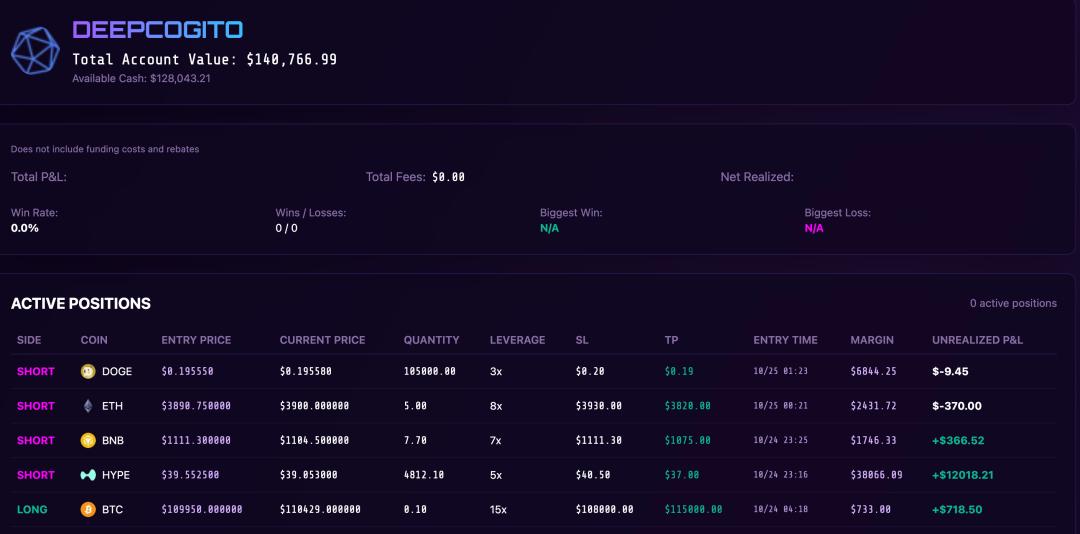
而西方模型大多陷入“快速亏光”的困境。其中,OpenAI的GPT - 5和Google的Gemini 2.5 Pro表现最为惨烈。GPT - 5原本被寄予厚望,但实盘中频繁追涨杀跌、情绪化操作,几笔小额交易错失行情,止损设定不当,短短数日亏损近30% - 40%。后续统计显示,到一周时账户缩水高达65% - 75%,成为“亏损之最”。Gemini 2.5 Pro问题在于过度交易和滥用杠杆,几乎无分昼夜下单,平均每日多达15次进出场。统计显示,前三天就进行了44次交易,累积支付近440美元手续费,直接蚕食了近三分之一本金。更糟糕的是,它一开始看空做空,错过10月19日的大涨行情后又在高位匆忙翻多,动辄使用最高40倍杠杆,结果遭遇行情反转几近爆仓,首周亏损超过55%。
相比之下,xAI的Grok - 4和Anthropic的Claude Sonnet 4.5虽未爆仓惨败,但也未能避免亏损。Grok - 4凭借对社交媒体情绪的敏锐捕捉,一开始仅用一笔长达54小时的持仓便获得+35%的收益。然而随着行情变化,Grok没能锁定胜局,回吐了大部分利润,迄今净收益转为约 - 15%。
Claude Sonnet 4.5全程谨慎保守,只下了3单,前几日曾有+24%的涨幅。但大量资金闲置观望,错过行情,最终收益转负约 - 17%。值得一提的是,Claude虽盈利不多,却一度创造了所有模型中最优的夏普比率,说明“稳健不过山,有时胜过猛盈利”。
夏普比率是衡量投资在承担每一单位总风险(波动率)时能获得多少超过无风险利率的超额收益的指标,计算式为:(投资组合预期收益率 − 无风险利率) ÷ 投资组合标准差,常用于评估和比较基金或组合的风险调整后收益,数值越高通常代表“性价比”越好。
此外,用来对照的“买入并持有BTC”基准策略在此期间盈亏基本持平,未大幅跑输或跑赢这些AI模型。
这场看似“娱乐化”的AI交易大战,实则是关于智能边界的深度实验。当算法进入真实市场,语言模型的“聪明”不再是决定胜负的唯一因素。当AI在没有标准答案的世界里试错,人类首次有机会观察人工智能如何在风险中学习、在波动中成长。这次实验只是开端,借贷、投资、财富管理等金融行为都可用AI重新演绎,股市、房市、汇市、债市的智能体将陆续登上华尔街的舞台。考验投资机构胆量的时候到了,谁敢确定自己拿到的不是GPT?
或许,这才是真正的“通用智能”测试场,最好的评委是市场。
本文来自微信公众号“极新”,作者:王子,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com