
黄仁勋发声:或推中国特供版最强AI芯片,3500亿市场诱惑大






黄仁勋表示,将把Blackwell带到中国市场。
短短两天,寒武纪两度超越贵州茅台,成为A股第一高价「股王」,AI市场的持续火热推动着用户预期不断攀升。
与之相反,英伟达在公布2026财年第二季度财务业绩后,股价大跌,不过其成绩单依然亮眼:营收达467亿美元,较第一季度增长6%,同比增长56%;数据中心收入为411亿美元,较第一季度增长5%,同比增长56%;Blackwell数据中心收入环比增长17%。这家曾经的游戏显卡厂商,如今市值突破4万亿美元,成为AI时代当之无愧的「卖铲人」,不少人将本次财报视为解答AI泡沫疑虑的答卷。

被「宠坏」的市场预期,和永远在路上的下一代产品
英伟达正受困于过去的成功,这是一种甜蜜的诅咒。过去多个财季,英伟达每次都超越营收预期,这种固定模式让市场习惯了期待一次次的超预期。然而,当英伟达总是给出110分的答案,100分就显得像不及格。
财报前夕,市场焦点集中在新一代Blackwell GPU和NVL72机架的大规模部署上。从技术角度看,这种期待并非毫无根据。英伟达花费数年打造了Blackwell NVLink 72系统,这是一种机架级计算平台,可作为一个单一的巨型GPU运行。

从NVLink 8过渡到NVLink 72,不仅带来了性能的大幅提升,还意味着更高的能效和更低的Token生成成本。英伟达创始人兼CEO黄仁勋表示:「Blackwell是全球期待已久的人工智能平台,带来了卓越的一代飞跃 —— Blackwell Ultra正在全速量产,市场需求极为强劲。」
新一代核心Blackwell架构的B100/B200系列,性能相比H100提升了2.5倍。GB200 NBL系统正在被广泛采用,已在国内外云服务商和互联网公司大规模部署。包括OpenAI、Meta等厂商也在数据中心规模上使用GB200 NBL72,不仅用于训练下一代模型,也用于生产环境中的推理服务。

由于GB200与GB300在架构、软件和物理形态上的兼容性,主要云服务商向新一代基于GB300的机架架构过渡十分顺畅。据英伟达CFO Colette Kress透露,7月下旬和8月上旬的工厂产线已顺利完成转换,以支持GB300的爬坡生产。「目前已全面进入量产阶段,产能恢复到满负荷,每周大约生产1000个机架。随着更多产能的上线,预计在第三季度内产量还将进一步加快。我们预计在下半年实现大规模市场供应。」
按照惯例,Blackwell之后还有代号「Rubin」的下一代架构,预计2026年推出,随后是2027年的「Rubin Ultra」。这种快速迭代的节奏,既保持了技术领先,又让竞争对手始终在追赶。

英伟达CFO Colette Kress对AI市场的发展有更大的野心,她在财报电话会议上表示:「我们正处在一场将改变所有行业的工业革命开端。预计到本十年末,AI基础设施的投入将达到3到4万亿美元。这一增长主要来自云厂商到企业的资本开支,仅今年就预计在数据中心基础设施和算力上的投资将达到6000亿美元,两年间几乎翻倍。」
这也是英伟达长期强调的——英伟达已不再是单纯的GPU公司,而是一家AI基础设施公司。黄仁勋称:以1GW规模的AI工厂为例,造价可能在500亿至600亿美元之间,其中约35%左右由NVIDIA提供。客户获得的不只是GPU。过去十年,英伟达已转型为AI基础设施公司。打造一台Rubin AI超级计算机,需要六种不同类型的芯片;扩展到1GW规模的数据中心,需要数十万GPU计算节点和大量机架。因此,英伟达定位为AI基础设施公司,希望推动行业发展,让AI更有用。
在黄仁勋看来,英伟达的优势在于GPU能效最佳。在电力受限的数据中心,性能功耗比决定收入,而英伟达的性能功耗比远超其他计算平台,所以买得越多,成长越快。尤其是推理型与智能体AI的发展普及带来算力需求呈指数级增长,这种对AI计算能力「永不满足」的需求,是英伟达营收增长的主要引擎。
此外,英伟达提供的CUDA并行计算平台、推理加速库、各行业AI模型框架等,已成为AI开发者必备工具。这种生态壁垒意味着客户一旦采用英伟达方案,就难以替换。也就是说,英伟达提供了面向AI工厂的完整全栈解决方案。
黄仁勋: 将Blackwell带到中国市场
这季度财报中,中国市场的影响十分明显。英伟达2026财年第二季度财报显示,来自中国市场收入27.69亿美元,比2025财年第二季度的36.67亿美元缩水近9亿美元。相应地,黄仁勋表示,中国市场在数据中心总收入中的占比已降至「低个位数百分比」。
英伟达的当务之急或许是推出一系列性能降低、符合出口管制的「合规芯片」。这一策略始于基于Hopper架构的H20,并延续至基于新Blackwell架构的产品线。

据路透社报道,英伟达正在准备专为中国定制的Blackwell架构削减版GPU(代号B30A)。该芯片性能介于受限H20和国际版高端GPU之间,如获批准将瞄准中国高端算力需求。此外还有一款规格较低的推理芯片RTX6000D,专门针对中国市场的特定需求。
黄仁勋表示,中国市场今年对英伟达来说大约有500亿美元(折合人民币3577亿元)的机会,且每年会以50%左右的速度增长。他认为,来自中国的开源模型质量非常优秀,如DeepSeek在全球声名鹊起,Qwen和Kimi也很出色,还有许多新的多模态大语言模型不断涌现,这些开源模型推动了全球企业对AI的采用。

黄仁勋还表示,将Blackwell带入中国市场是有可能的。上个月他亲自来华斡旋,表态将不遗余力优化产品以符合监管要求,并坚定服务中国市场。
但国内力量也在加速崛起。最近,DeepSeek发布了最新版本V3.1,被称为「迈向Agent时代的第一步」。更重要的是,DeepSeek V3.1引入了一种称为「UE8M0 FP8 Scale」的新参数精度格式,明确表示这是「针对即将发布的下一代国产芯片设计」的精度格式。
DeepSeek采用的UE8M0 FP8格式针对国产芯片的硬件逻辑特点设计,在8 bit位宽限制下丢弃尾数,极大扩展指数动态范围。这一设计让国产芯片在大模型训练中更稳定,能高效利用算力。对于许多在HBM高带宽内存上不及英伟达的国产芯片而言,FP8格式有效缓解了带宽瓶颈,让硬件性能得到充分发挥。
巧合的是,英伟达最近提出的NVFP4(4位数值格式)在大模型预训练领域实现了突破。相比于以往训练常用的16位(FP16/BF16)或8位 (FP8)精度,NVFP4将精度进一步压缩到4位,在保持模型精度的同时大幅提升训练速度和算力利用率。
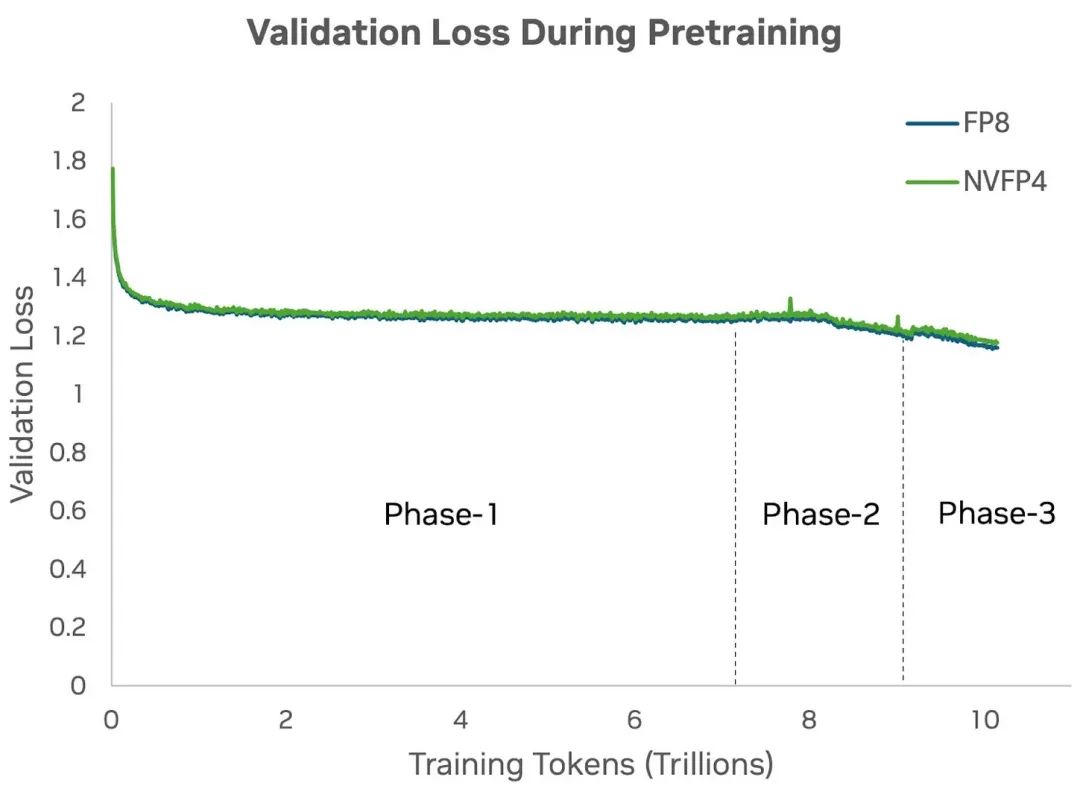
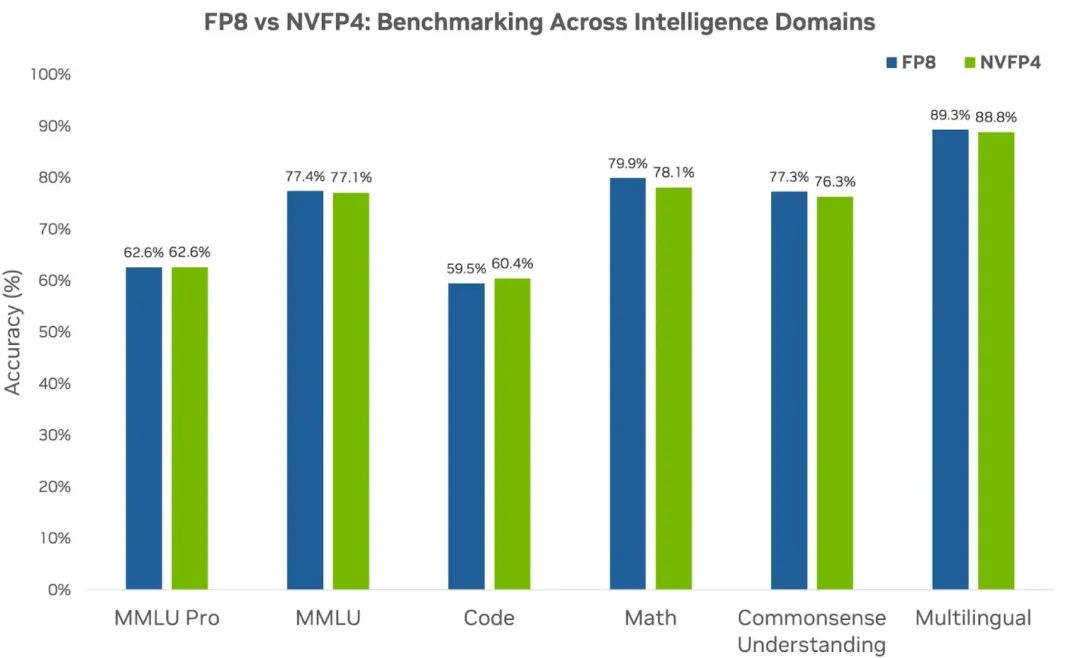
实验结果显示,在120亿参数的Mamba - Transformer混合模型上,NVFP4能完整训练到10万亿token,收敛效果几乎与FP8一致,下游任务测试精度也基本相同。
当国产头部芯片厂商组建「朋友圈」,共同打造适配本土芯片的软件栈、工具链,有望提升下游客户对国产方案的信心。英伟达虽是淘金热中稳赚不赔的「卖铲人」,但如今矿场边涌现出越来越多本土铁匠铺,用本地矿石和工艺打造更适合本地矿工的工具。
本文来自微信公众号“APPSO”,作者:发现明日产品的,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com