
HBM面临挑战,未来存储走向多层级架构







高带宽内存(HBM)作为下一代动态随机存取存储器(DRAM)技术,其核心创新在于独特的3D堆叠结构。通过先进封装技术将多个DRAM芯片(通常为4层、8层甚至12层)垂直堆叠,使HBM的带宽(数据传输速率)远高于GDDR等传统内存解决方案。
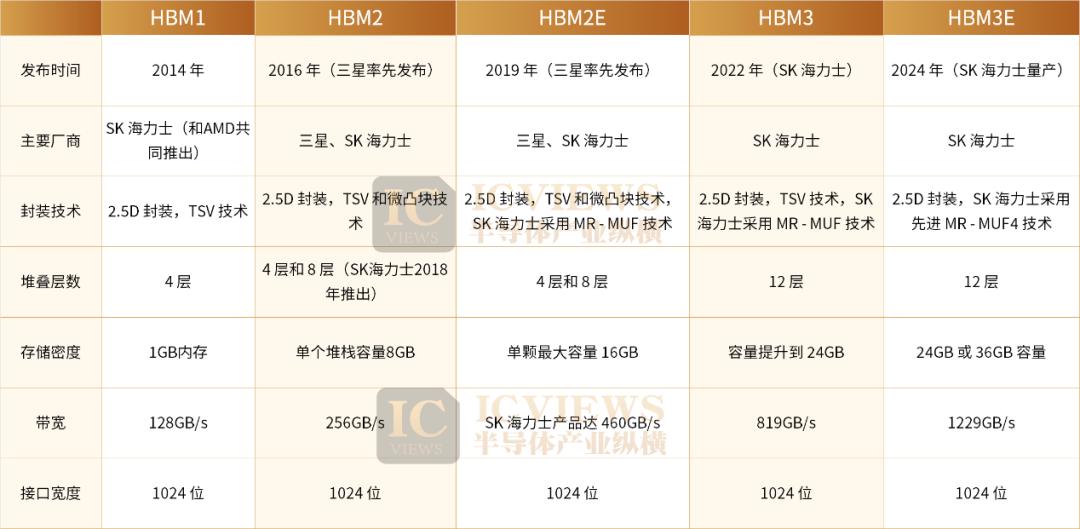
凭借高带宽、低延迟的特性,HBM已成为AI大模型训练与推理的关键组件。在AI芯片中,它扮演着“L4缓存”的角色,能显著提升数据读写效率,缓解内存带宽瓶颈,增强AI模型的运算能力。
01 HBM市场,SK海力士独领风骚
依托HBM技术的领先优势,SK海力士在行业中的地位不断攀升。市场数据显示,自2024年第二季度起,美光与SK海力士的DRAM市场份额持续增长,三星则逐步下滑。在HBM领域,原本与三星近乎平分秋色的格局被打破,截至今年第一季度,两者份额差距已扩大至两倍以上。
今年第二季度,SK海力士以约21.8万亿韩元的DRAM及NAND销售额,首次超越三星电子(约21.2万亿韩元),登顶全球存储销售额榜首。这主要得益于其HBM产品的强势表现。作为英伟达的主要独家供应商,SK海力士早期在HBM市场未脱颖而出,但随着全球AI开发热潮兴起,其高性能、高效率的产品需求激增。
第五代高带宽内存HBM3E是关键因素。该产品具备高带宽、低功耗优势,广泛应用于AI服务器、GPU等高性能计算领域。2023至2024年间,吸引了AMD、英伟达、微软、亚马逊等科技巨头竞相采购,而SK海力士是全球唯一大规模生产HBM3E的厂商,其2025年的8层及12层HBM3E产能已全部售罄。
反观三星电子,因向英伟达交付延迟错失良机,在AI市场应用最广的HBM3E领域大幅落后于SK海力士。市场份额从去年第二季度的41%暴跌至今年第二季度的17%,甚至有报道称其未通过英伟达第三次HBM3E认证。
光大证券预计HBM市场需求将持续增长,带动存储产业链发展;花旗证券则预测,SK海力士将继续主导HBM市场。SK海力士有望在AI时代成为“存储器恐龙”。
02 存储厂商开发HBM替代方案
面对SK海力士的强势,行业内其他厂商纷纷加速技术创新,探索HBM的替代方案。
三星重启Z - NAND
2025年,三星电子在搁置七年后,决定重启Z - NAND内存技术,并将其定位为满足人工智能(AI)工作负载增长需求的高性能解决方案。这标志着三星重新进军高端企业存储领域。
三星内存业务执行副总裁Hwaseok Oh表示,公司正全力重新开发Z - NAND,目标是将其性能提升至传统NAND闪存的15倍,同时把功耗降低多达80%。即将推出的新一代Z - NAND将搭载GPU发起的直接存储访问(GIDS)技术,让GPU可直接从存储器获取数据,无需经过CPU或DRAM,以降低延迟,加速大型AI模型的训练与推理进程。
Z - NAND的复苏,反映出快速扩展的AI模型已超越传统存储基础设施的承载能力。当前系统中,数据传输过程形成严重瓶颈,既导致性能下降,又增加能耗。而三星支持GIDS的架构可消除这些瓶颈,允许GPU将大型数据集从存储器直接加载到VRAM中,能显著缩短大型语言模型(LLM)及其他计算密集型AI应用的训练周期。
事实上,三星早在2018年就首次推出Z - NAND技术,并发布了面向企业级和高性能计算(HPC)应用的SZ985 Z - SSD。这款固态硬盘性能优异,读取速度快,延迟低,配备节能DRAM,额定写入容量高,可靠性强。
X - HBM架构重磅登场
NEO Semiconductor推出全球首款适用于AI芯片的超高带宽内存(X - HBM)架构。该架构基于其自研的3D X - DRAM技术,突破了传统HBM在带宽与容量上的瓶颈,或将引领内存产业迈入AI时代的“超级内存”新阶段。
相比之下,预计2030年左右上市的HBM5,仅支持4K位数据总线和每芯片40Gbit的容量;预计2040年左右推出的HBM8,也仅能实现16K位总线和每芯片80Gbit的容量。而X - HBM凭借32K位总线和每芯片512Gbit的容量,可让AI芯片设计人员绕过传统HBM技术需耗时十年才能突破的性能瓶颈。其带宽达到现有内存技术的16倍,密度为现有技术的10倍,能满足生成式AI与高性能计算的需求。
Saimemory开发堆叠式DRAM
由软银、英特尔与东京大学联合创立的Saimemory,正研发全新堆叠式DRAM架构,目标是成为HBM的直接替代方案,甚至超越其性能。
该公司聚焦3D堆叠架构优化,通过垂直堆叠多颗DRAM芯片并改进芯片间互连技术,提升存储容量并降低数据传输功耗。目标产品将实现容量较传统DRAM提升至少一倍,功耗较HBM降低40% - 50%,且成本显著低于现有HBM方案。
这一技术路线与三星、NEO Semiconductor等企业不同,后者聚焦容量提升,而Saimemory更侧重解决AI数据中心的电力消耗痛点,契合绿色计算的行业趋势。
在技术合作层面,英特尔提供先进封装技术积累,东京大学等日本学术机构贡献存储架构专利,软银则以30亿日元注资成为最大股东。初期150亿日元研发资金将用于2027年前完成原型设计及量产评估,计划2030年实现商业化落地。
闪迪联手SK海力士推进HBF高带宽闪存
闪迪与SK海力士近日宣布签署谅解备忘录,联合制定高带宽闪存(High Bandwidth Flash,HBF)规范。HBF是闪迪今年2月提出的专为AI领域设计的新型存储架构,融合了3D NAND闪存与高带宽存储器(HBM)的技术特性。闪迪将于2026年下半年推出首批HBF内存样品,采用该技术的AI推理设备样品则预计在2027年初上市。
作为基于NAND闪存的内存技术,HBF采用类HBM封装形式,能显著提升存储容量并降低成本,同时具备数据断电保留的非易失性优势。这是业界首次将闪存的存储特性与类DRAM的高带宽性能整合到单一堆栈中,有望重塑AI模型大规模数据访问与处理的模式。
03 多维度架构创新降低HBM依赖
除了存储技术创新,厂商们也在探索AI领域的架构革新,以降低对HBM的依赖。
存算一体架构
上世纪40年代,基于“存储 - 计算分离”原理的冯・诺依曼架构诞生,此后芯片设计基本沿用该架构。近70年里,芯片行业技术进步多集中于软件与硬件优化,底层架构未发生根本改变。
存算一体(Processing - In - Memory, PIM或Compute - In - Memory, CIM)架构应运而生。其核心理念是在存储器本体或邻近位置集成计算功能,规避传统架构中“计算 — 存储 — 数据搬运”的瓶颈。通过在存储单元内部直接部署运算单元,缩短数据传输距离,整合计算与存储单元,优化数据传输路径,突破传统芯片的算力天花板。这不仅能缩短系统响应时间,还能使能效比大幅提升。一旦技术成熟,有望降低对高带宽内存的依赖度,部分替代HBM的功能。
华为的AI突破性技术成果
华为近期发布的UCM(推理记忆数据管理器),是以KV Cache(键值缓存)为核心的推理加速套件。它融合多种缓存加速算法工具,可对推理过程中产生的KV Cache记忆数据进行分级管理,扩大推理上下文窗口,实现高吞吐、低时延的推理体验,降低每个Token(词元)的推理成本。通过这一创新架构设计,UCM能够减少对高带宽内存(HBM)的依赖,同时提升国产大模型的推理性能。
04 未来将是多层级架构的时代
在训练和推理场景中,算力与存储是率先受益的领域,将决定未来十年AI竞争格局。
与GPGPU产品类似,HBM(尤其是HBM3及以上规格)需求旺盛,且长期被国外厂商垄断。2025年初,HBM3芯片现货价格较2024年初暴涨300%,单台AI服务器的DRAM用量是传统服务器的8倍。从市场格局看,海外厂商仍占主导地位:SK海力士以53%的份额领先,且率先实现HBM3E量产;三星电子占比38%,计划2025年将HBM供应量提升至去年的两倍;美光科技目前份额为10%,目标是2025年将市占率提升至20%以上。
尽管HBM在高端AI应用领域表现卓越,但随着其他内存技术在成本控制、性能提升及功耗优化等方面的突破,其未来可能面临新兴技术的竞争压力。不过短期内,HBM仍是高带宽需求场景的首选方案。
从长期看,市场将随技术演进与应用需求变化而调整优化。未来AI内存市场不是简单的“替代与被替代”关系,HBM替代方案的创新呈现出“架构哲学的多样性”。AI计算与内存领域不会出现全面取代HBM的“唯一赢家”,而是会形成更复杂、分散化且贴合具体场景的内存层级结构,单一内存解决方案主导高性能计算的时代正在结束。
未来的AI内存版图将是异构多元的层级体系:HBM聚焦训练场景,PIM内存服务于高能效推理,专用片上内存架构适配超低延迟应用,新型堆叠DRAM与光子互连等技术也将在系统中占据一席之地。各类技术针对特定工作负载实现精准优化,共同构成AI时代的内存生态。
本文来自微信公众号“半导体产业纵横”(ID:ICViews),作者:鹏程,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com