
AI大神卡帕西力挺!全球首个直播生成模型问世,实时生成无时长限制





编译 | 李水青
编辑 | 漠影
智东西7月19日消息,7月18日,以色列AI创企Decart推出了首个直播扩散AI视频模型——MirageLSD。和Veo等市面上时长受限、存在延时的视频生成模型不同,Mirage能够实时转换无限长的视频流,响应时间小于40毫秒。
前特斯拉AI总监、OpenAI创始团队成员安德烈·卡帕西(Andrej Karpathy)在社交平台X上表示:“Veo等视频扩散模型很出色,但生成需要数秒甚至数分钟,而MirageLSD带来的是实时的魔法。”他觉得这会是一项通用且强大的技术,有望改变游戏、直播、视频通话、影视、会议、AR/VR等多个领域。
Decart于2023年创立,Andrej Karpathy参与了投资,Mirage是Decart继“AI版我的世界” Oasis之后推出的第二个模型。目前,由MirageLSD模型驱动的Mirage平台已上线,iOS、Android版本预计下周推出。
体验地址:
https://mirage.decart.ai/
Andrej Karpathy强力推荐:
实时魔法,变革游戏直播行业
在社交平台X上,AI大神Andrej Karpathy兴奋地说:”扩散视频模型如今支持实时生成了!“
Andrej Karpathy提到,以前简单的视频滤镜能实时生成,但大多只能进行基本的重新着色和样式设置。市面上已有的Veo等视频扩散模型很神奇,不过生成需要数秒甚至数分钟。MirageLSD则是实时魔法。和简单的视频滤镜不同,扩散模型能理解正在查看的内容,所以可以智能地设置视频源各部分的样式,比如给头上戴上帽子,或给手上配上光剑等。
Andrej Karpathy还称,该模型可任意操控,比如通过文本提示来操作。可定制的智能视频滤镜未来会解锁很多酷炫的玩法:
-将摄像头画面转化为虚拟实景;

▲摄像机拍摄画面实时生成视频(源自:Decart官网)
-执导并拍摄自己的电影,用道具演绎场景,实时拍摄并即时回看;

▲实景道具演绎视频实时变3D卡通动画(源自:Decart官网)
-围绕简单的球体或方块生成有氛围的代码游戏,再借助实时扩散模型为游戏添加纹理,让其更精美;

▲生成游戏画面(源自:Decart官网)
-对任意视频流进行风格化处理和自定义:游戏、视频等。比如,让《上古卷轴 5:天际》更有“史诗感”?让《毁灭战士 2》用一个提示词就达到现代虚幻引擎的画质?把恐怖片变成“只有可爱元素、粉色调与小兔子”的风格?都有可能!
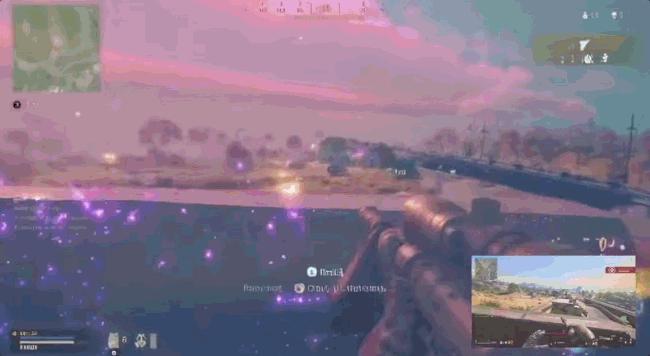
▲生成游戏画面(源自:Decart官网)
-Zoom通话背景实时虚拟更换。
-眼镜:比如,让你的视觉实时卡通化?
-现在能打造哈利·波特的厄里斯魔镜,在镜子里展现“原始画面”,还能增强你内心最深处的渴望(由AI推断)。
Andrej Karpathy称,可设想的应用场景太多,他可能遗漏了重要的。他还声明:“我是Decart的小额天使投资人,我很激动,因为在我看来,这项技术会很快变得非常好,感觉它很通用、很强大,但技术难度也很高。祝贺团队发布成功!”
突破视频生成“30秒瓶颈”
生成速度提升16倍
MirageLSD是首个实现无限实时零延迟视频生成的系统。它基于名为“实时流扩散 (LSD)”的定制模型构建,该模型能逐帧生成视频,同时保持时间连贯性。
和以往方法不同,LSD支持完全交互式的视频合成,允许在视频生成过程中持续进行提示、转换和编辑。
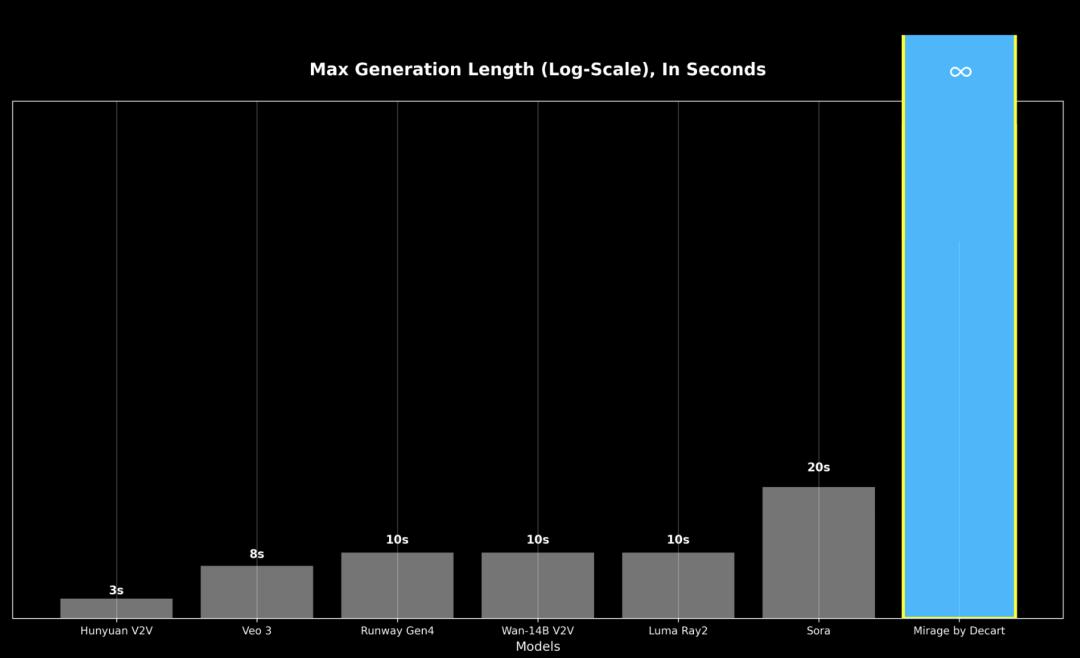
当前的视频模型无法生成超过30秒的视频,否则会因错误累积导致质量严重下降。它们通常需要几分钟的处理时间才能输出几分钟的视频。即使是当今最快的实时系统,通常也会分块生成视频,带来不可避免的延迟,影响交互使用。
为了实时生成视频,LSD必须以因果关系的方式运行,即仅基于前一帧生成每一帧。这种自回归结构确保了连续性,但也有个严重缺陷:误差累积。每一帧都会继承上一帧的缺陷,微小误差累积起来,会使质量迅速下降,直到帧变得不连贯。
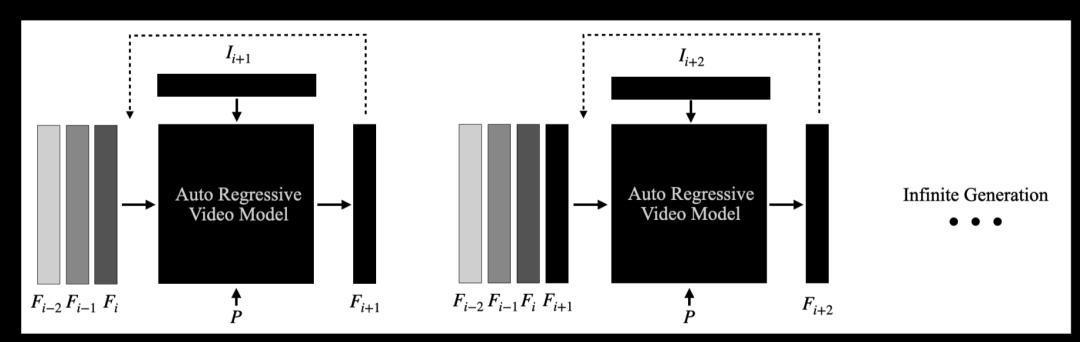
启用LSD需要解决两个以前从未在单个系统中同时解决的挑战。
1、基于扩散强制技术,实现无限生成
为了实现无限的自回归生成,Mirage研究人员以扩散强制技术为基础,进行逐帧去噪;引入了历史增强功能,使模型能够针对损坏的输入历史帧进行微调。这教会模型预测并纠正输入伪影,使其能够抵御自回归生成中常见的漂移。
这些操作让MirageLSD成为第一个能够无限生成视频而不会崩溃的模型,稳定、可提示,并且与场景和用户输入保持一致。
2、速度提高16倍,实时生成视频
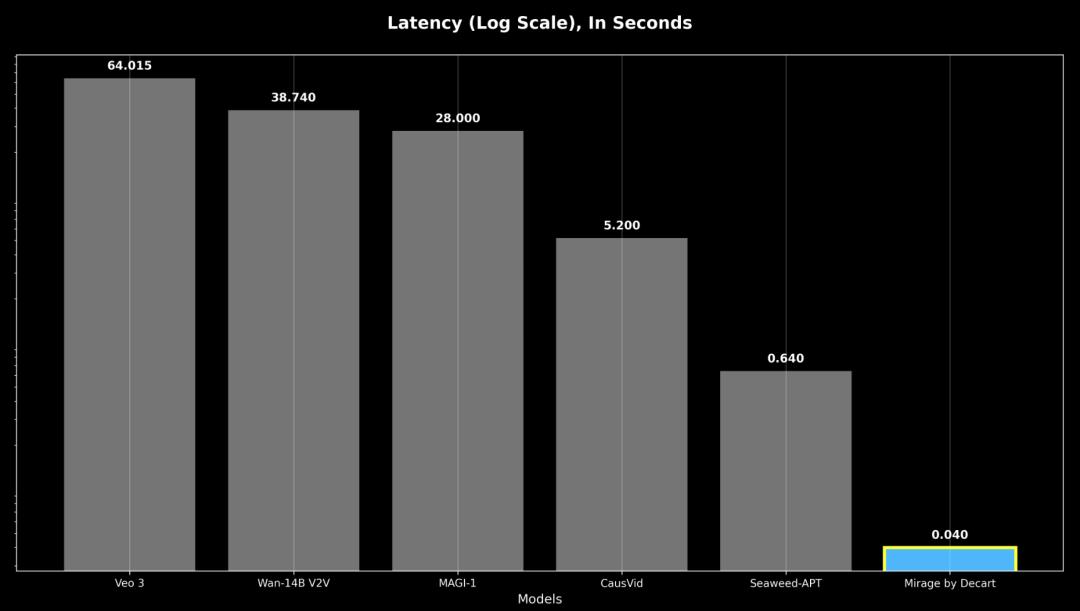
响应度被定义为最坏情况的响应延迟,即使是以前的自回归模型的响应速度也比MirageLSD慢16倍以上,无法实现实时交互。
实时生成要求每帧生成时间不超过40毫秒,以免人眼察觉。Mirage研究人员通过以下方式实现这一目标:设计定制的CUDA巨型内核,以最小化开销并最大化吞吐量;基于快捷蒸馏和模型修剪,减少每帧所需的计算量;优化模型架构以与GPU硬件保持一致,从而实现峰值效率。
总之,这些技术使响应速度比之前的模型提高了16倍,能够以24 FPS的速度生成实时视频。
与Veo走差异化路线
首个实时无限视频生成模型
当下,AI视频生成方面的模型在生成视觉质量和时长上有了提升,但大多数系统仍然缺乏交互性、低延迟和时间稳定性。
MovieGen、WAN和Veo等固定长度模型可以生成高质量的视频片段,但它们的非因果设计和全片段推理会引入延迟,并阻止实时交互或超出预定义长度的扩展。
CausVid、LTX和Seeweed - APT等自回归模型通过对先前的输出进行条件化来生成更长的序列,虽然这提高了可扩展性,但分块推理仍然限制了响应速度,并容易出现错误累积,限制了生成长度,最终导致无法进行真正的交互。
可控生成方法,包括ControlNet和基于LoRA的适配器,可以实现有针对性的编辑和风格转换,但需要离线微调,不适合实时逐帧提示。
Mirage自身之前的系统Oasis首次在受限域内实现了实时因果生成。MirageLSD则将其扩展到开放域、可提示的视频,具有零延迟、实时速度和无限稳定性,这是先前研究无法实现的组合。
结语:实时无限生成视频
精确控制仍然有限
MirageLSD虽然实现了实时、可提示且稳定的视频生成,但仍面临一些挑战。首先,该系统目前依赖于有限的过去帧窗口。引入长期记忆机制可以提高扩展序列的连贯性,从而实现更一致的角色身份、场景布局和长期动作。
此外,虽然MirageLSD支持文本引导的转换,但对特定对象、空间区域或运动的精确控制仍然有限。集成结构化控制信号(例如关键点或场景注释)或许可以在实时场景中实现更精细的用户控制编辑。
Mirage提出,团队需要进一步研究来提升语义和几何一致性,尤其是在极端风格转换的情况下的表现。解决这个问题需要在提示驱动的指导下建立更强大的内容保存机制。
本文来自微信公众号 “智东西”(ID:zhidxcom),作者:李水青,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com