
两家科技巨头“中科院系”合并:国产计算率格局要变天?








美国又开始了。
在过去的两天里,国内外媒体报道说,美国切断了对华半导体技术的出口。
有人说,这一次,美国政府切断了一些美国企业向中国销售半导体设计软件的途径。电子自动化设计(EDA)Cadencencen三巨头、Synopsys、Siemens 在中国电子设计自动化市场中,EDA都有可能“断供”,占80%以上。
在过去的几年里,人们仍然关心看得见的技术,如芯片制造。
但是现在,看不见的技术游戏,也不断地暴露在水面上。
最近,国内厂商也没有闲着。日前,国内算率行业发生了一场“地震”。:通过换股吸收海光信息合并中科曙光。
这一消息之所以如此引起振动,是因为两家公司都是业界的“巨头”:海光信息是国内芯片行业的主心骨,专注于高端CPU和AI芯片,市值超过3100亿元。中科曙光是服务器和云计算领域的老牌企业,市值超过900亿元。
国内厂商拉响了争夺算率“生态”的战斗。
生态的高墙
当前中美算率竞争,单纯竞争“硬算率”的时代正逐步成为过去,而下一阶段的竞争,则聚焦于“生态”。
首先看看美国最近在计算能力方面对中国做了什么:
5月14日,美国商务部果断撤销拜登政府阶段拟定的AI扩散规则,随后推出更严格的AI芯片出口管制新规。这个AI扩散规则最初将世界分为369等级,中国被无情地归类为GPU芯片全面禁运的第三个等级。
然而,对于这一政策,英伟达CEO黄仁勋在台北国际电脑展上表示,美国对中国人工智能芯片的出口管制实际上是“一败涂地”。
就算率市场份额而言,英伟达近年来在中国遭受了巨大的损失。
黄仁勋自己透露,在拜登政府开始进行AI控制的时候,英伟达是中国市场的“主导地位”,份额高达95%,是一个合适的行业霸主。但是现在,它的市场份额一路飙升到只剩下50%,几乎减半。
其背后的原因,正是美国的出口管制。

在媒体上,黄仁勋谈到了美国对中国人工智能出口的管制
在美国,英伟达不允许向中国销售先进的AI芯片,中国企业扭头支持本土芯片研发。
就像华为的升腾芯片和寒武纪的思源芯片一样,这些国产“新星”开始崭露头角,迅速占领市场,将一半的蛋糕活生生地从英伟达口中分离出来。
但是,市场份额的变化,并没有从根本上改变国内对英伟达计算能力的依赖。
说白了,芯片不仅仅是硬件,软件生态也是命脉。
在这方面,英伟达的CUDA平台是一个巨大的开发者生态系统,拥有PyTorch这样的全球无数AI模型和深度学习框架。、TensorFlow,全部围绕CUDA升级,国内相当一部分大厂的AI系统也大多是基于CUDA开发。
例如,当一家大型制造商推动AI计算服务时,他们经常使用英伟达的GPU集群作为卖点。例如,他们提供基于H20芯片的智能计算服务,并直接使用CUDA生态支持客户快速部署大型模型。
即使有些大厂商有自己的芯片,也只用于边缘计算或特定场景。真正的大模型训练还是要靠英伟达的硬件和CUDA软件栈。
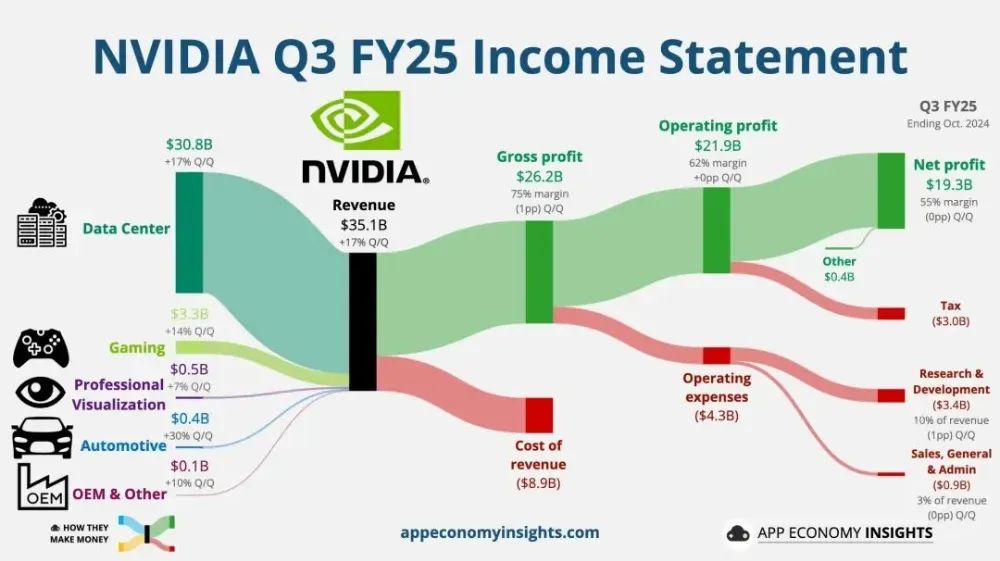
英伟达的触须已遍布各个领域
由于转化为华为的MindSpore或寒武纪等国产芯片的框架,意味着需要重写代码,重新适应,整个过程费时费力,导致很多公司为了防止生态切换的昂贵成本,优先考虑英伟达的H20或B40芯片,即使面对国产芯片的价格优势。
事实上,英伟达并不是唯一一个在AI计算上落后的英特尔,他也知道全栈生态的重要性。近年来,他获得了一条名为OneAPI的开发工具链,目标是“你写一套代码。CPU、GPU、FPGA、AI加速器都可以运行,降低了开发者的转移成本。
还有像Sovereignign Cloud、AI PC、AI开发套件,Gaudi训练平台,Edge AI解决方案等,目的是让您无论是从事边缘布署、云训练,还是从事本地推理,选择整套房子就可以打通上下游。
说白了,它就是让顾客“少折腾”,形成生态绑定。

单从计算率来看,国内很多公司都在计算单卡率上下了很大功夫,比如华为的升腾。 单卡算率直接突破900。 TFLOPS,英伟达达的性能降级版 H20狠狠地甩在后面;壁邈、兖原也声称训练卡的性能接近A100,但最终由于生态的不足,很难与英伟达相媲美。
而且这次海光与曙光的合并,正是我国建立计算生态的重要一步。
为何这么说?
越过高墙
海光、曙光都是中科院系公司。
两家公司各有千秋。
在计算率方面,海光信息专注于高端处理器,如深度计算系列DCU(数据中心计算单元,类似于NVIDIA的GPU)和X86结构的CPU。这些芯片是国产计算能力的“心脏”,非常适合需要超级计算能力的场景,如AI训练、科学计算、数据中心等。
海光的设计强度在于性能和功耗低。比如他们的深度计算是三号DCU,单卡峰值算率和英伟达H20差不多,但是价格比H20便宜很多,非常适合大规模布局。
中科曙光更擅长将芯片、存储、热排放等硬件组装成服务器、高性能计算机,甚至整个数据中心的解决方案。他们的优势在于系统级别的提升,比如如何让服务器快速稳定运行,如何利用液冷技术冷却机器,如何将硬件和云计算软件放在一起,从设备到服务提供一套完整的解决方案。
此前,曙光服务器与海光的芯片分为不同的主体,其中“芥蒂”的确很大,严重拖累了提升的后腿。
从技术适配的角度来看,在设计海光芯片时,没有办法完全针对曙光服务器的“脾性”。服务器内部空间布局、散热系统设计、供电线路规划等。都是基于一般芯片标准,导致海光芯片性能过热受限,无法充分发挥计算率。
在数据交互方面,曙光服务器的数据传输协议和缓存机制也是根据行业中常见的芯片设置的。当需要海光芯片的数据处理节奏和带宽时,很容易出现“堵车”,增加传输延迟,大大增加计算时间,极大地影响数据处理效率。
更重要的是,从供应链安全的角度来看,自2019年美国将海光和曙光列入实体名单以来,两者的整合无疑是弥补产业链、增强自主性的重要组成部分。
两者合并,技术上就像“心脏”与“身体”的结合,两者可以自然互补。
也许可以实现“ic设计-服务器制造-云计算服务”的全链条布局,如华为升腾芯片。

海光高性能国产处理器
比如华为升腾的鲲鹏CPU和泰山服务器,结合华为云的AI服务,可以让客户直接在云端运行复杂的大模型,成本比使用海外方案低30%-40%。
在海光与曙光合并之后,也有可能推出一套类似的组合拳,例如使用深度计算DCU。、天阔服务器和自己的云平台帮助客户运行AI任务,速度快,价格低,而且都是国产产品,非常适合对安全要求高的场景,比如“东数西算”或者金融电信。
在中国培育“算率森林”
黄仁勋、苏姿丰在当前中美算率博弈中,(AMD CEO)等待“华裔谋士”给美国的战略,确实有点东方智慧的味道,就像“以柔制刚”。
他们的想法是,美国在芯片和计算率方面处于领先水平,尤其是NVIDIA。、AMD的GPU,全球AI、这些“硬通货”对于数据中心和云计算是不可或缺的。
与其用“刚性战略”来掩盖技术,严格控制出口,不如放开手脚,让美国芯片和计算方案占领全球市场。
这个招数颇有“润物无声”的意思,通过市场渗透和技术锁定,悄悄地将全球计算生态系统绑在美国战车上。
而且中国目前的战略,与美国有很大不同。总而言之,更像是“高墙,广积粮”。
所谓“筑墙”,就是把算率产业链的每一个环节都握在自己手里,比如海光信息和中科曙光的合并,就是把ic设计(海光DCU)、CPU)与服务器制造(曙光的“天阔”系列)捏成一个整体,再加上云计算服务,打造整个从芯片到系统的链条。
这种整合是为了保证国内AI不被海外卡脖子,、使用国产商品的数据中心、政务、金融系统,稳定“基本盘”。
“积粮”就是产量和规模的激烈堆积,而所谓的“积粮”不仅仅是堆积,还要建一个“磨坊”,保证AI。、云计算这些核心场景的需求可以自己决定。并利用国内超大市场“倒逼”积粮。
具体来说,国内设备需要政务、电信、金融等领域。比如2024年三大运营商采购服务器中,60%使用国产芯片(海光、华为为主),直接带动海光DCU出货量增长50%。
而且华为的升腾910B,专门为大型模型优化而设计,去年国内推理市场份额也达到30%。
总的来说,在目前的算率博弈中,中国仍处于“守势”状态。
这个阶段,海光-曙光这样的整合,主要是为了节省产业链的“硬实力”,降低成本,提高性能。
但是要转变为战略相持,光靠硬实力是不够的,要在“软实力”的生态上下大功夫。
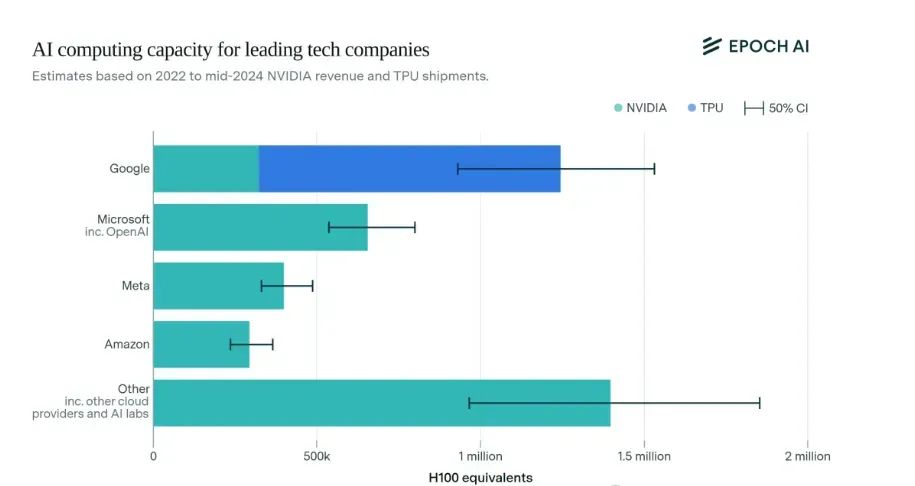
现在美国企业仍然占据着算率霸权
然而,生态就像一片农田。如果先种,总会有先发优势。后者不仅要面对时差的压力,还要面对前者本身的粘性挑战。
所以国内企业并没有试图一步一步取代CUDA,而是先在国内“深耕细作”,以低成本和场景优势吸引用户,然后慢慢向外扩散。
2024年,国内AI框架的粘性已初见成效,华为MindSpore在国内开发者社区中增长了50%。
刀子磨得越快。
中国制造商也看到了东南亚、非洲等新兴市场,利用低价 定做方案抢地盘,绕过欧美NVIDIA的“主场”,在实战中不断提升技术。
这种在缝隙中生长的韧性,并非一夜之间爆发的奇迹,而是像植树一样,脚踏实地,才能慢慢地生长出自己的“算率森林”。
本文来自微信微信官方账号“正解局”,作者:正解局,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com