
微软研究:AI 程序助手软件调试能力堪忧






IT 世家 4 月 13 日消息,OpenAI、Anthropic 与其他顶级人工智能实验室相比,越来越多的人工智能模型被用来协助编程任务,谷歌CEO桑达尔・去年皮查伊 10 月透露,该企业 25% 的新代码由 AI 生成;而 Meta CEO马克・在公司内部,扎克伯格也表达了广泛的部署 AI 编码模型豪情壮志。
但是,即便是目前最先进的一些。 AI 在处理软件漏洞这个问题上,模型仍然无法与有经验的开发者相媲美。微软研究所(微软研发部)的一项新研究发现,其中包括 Anthropic 的 Claude 3.7 Sonnet 和 OpenAI 的 o3-mini 内部的多种模型,在一个名字中 SWE-bench Lite 在软件开发基准测试中,许多问题无法成功调整。
共同探索的作者测试了九种不同的模型。这些模型作为“基于单个提示的智能体”的关键,可以使用。 Python 一系列调试工具,包括调试器。它们分配了一组筛选出来的智能体 300 这些任务都来自于软件调试任务。 SWE-bench Lite。
根据共同作者的说法,即使配置了更强大、更先进的模型,他们的智能体成功完成的调试任务也很少超过一半。其中,Claude 3.7 Sonnet 平均通过率最高,为 48.4%;其次是 OpenAI 的 通过率为o1 30.2%;而 o3-mini 的成功率为 22.1%。
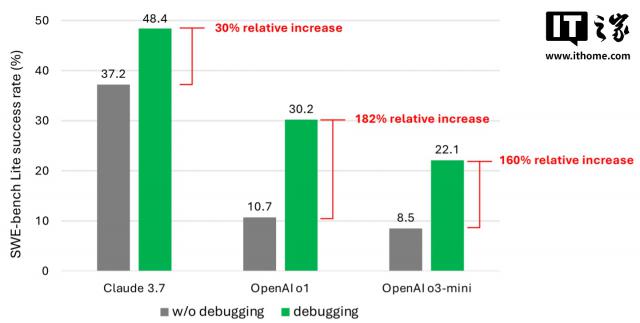
为何这些 AI 模型性能如此不尽如人意?有些模型很难使用可用的调试工具,理解不同的工具如何帮助解决不同的问题。然而,共同作者认为,数据稀缺是一个更大的问题。在目前的模型训练数据中,他们推断,缺少足够的“顺序决策过程”数据,也就是人类调整痕迹的数据。
“我们坚信,训练或微调这些模型可以使它们成为更好的互动调试器。”共同作者在调查报告中写道,“然而,这需要一些特殊的数据来满足这种模型训练的需要,例如记录智能体和调试器之间的互动来收集必要的信息,然后提出建议的轨迹数据来修复漏洞。”
这个发现实际上并不令人惊讶。许多研究表明,代码生成型 AI 安全漏洞和错误通常被引入,这是由于他们在理解编程逻辑方面的薄弱环节造成的。最近,一个受欢迎的 AI 编程工具 Devin 评估发现,它只能完成。 20 在项目编程检测中 3 项。
然而,微软的这项研究是迄今为止最详细的分析之一,在这个不断存在的问题领域。虽然可能不会削弱投资者。 AI 帮助编程工具的热情,希望它能让开发者及其上级领导三思而后行,不再轻易地完全交给编程工作。 AI 来主导。
IT 世界注意到,越来越多的科技领袖对此表示关注。 AI 关于将取代编程工作的观点提出了质疑。比尔微软创始人・盖茨曾经说过,他认为编程将作为一个职业存在很长一段时间。他也有同样的看法。 Replit 阿姆贾德CEO・马萨德、 Okta CEO托德・麦金农以及 IBM 阿尔温德CEO・克里希纳。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com