
对AI未来竞争形势的分析,连马斯克都拍手叫好?








上周末,社交媒体X上有一条关于“未来AI竞争趋势”的推文,引起了马斯克的兴趣,并获得了他的“手动好评”。此外,马斯克的xAI上周正式发布了Grok 3大模型。
这篇文章是美国著名的TMT投资者Gavin(科技、媒体和通信) 马斯克发表了一篇关于这一点的评论:“分析得很好”。所以,让我们来看看Gavin。 到底Baker表达了什么?
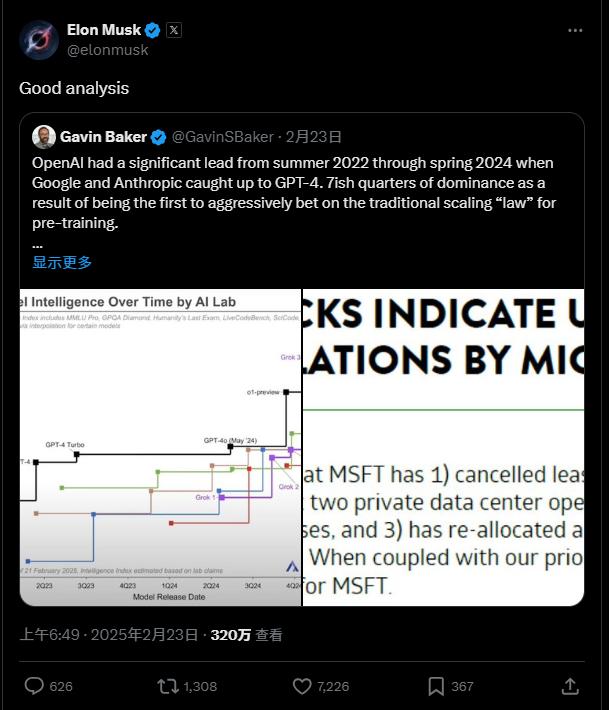
首先,Baker认为AI产业格局的变化正在加快,OpenAI在未来的领先优势将会减少。未来,数据将成为竞争的核心,无法获得独特而有意义的数据的前沿模型是历史上跌价最快的资产。从这个角度来看,谷歌、Meta等巨头可以通过垄断数据来构建“环城河”。
具体而言,Baker指出,OpenAI从2022年夏天到2024年春天一直处于领先地位,但是后来谷歌和Anthropic赶上了GPT-4。由于其先发优势和传统预训练“缩放定律”的积极下注(Scaling Law),OpenAI企业占据了7个季度以上的主导地位。
Scaling Law,又称尺度定律,被业界认为是大型预训练的第一原则。在机器学习领域,特别是对于大型语言模型,模型性能及其规模(如参数数量)、一种可预测的训练数据集大小和用于训练的计算资源之间的关系。
“Baker指出,”Scaling Law“优势窗口正在关闭。
他写道:“GoogleGemini、xAI的Grok-以及最新的Deepseek模型,已经达到了与GPT-4相似的技术水平。甚至OpenAI创始人奥尔特曼也指出,OpenAI未来的领先优势将会更加狭窄。在模型能力方面,OpenAI领先的独特阶段即将结束,微软CEO纳德拉表示。
Baker补充道:“在我看来,这就是为什么纳德拉选择不为OpenAI提供1600亿美元的预训练资金。
据媒体报道,微软内部记事本显示,计划投资160亿美元升级预训练基础设施的计划因预训练边际效益下降而停止,微软随后专注于为OpenAI提供推理率以获取利润。
纳德拉此前曾表示,数据中心可能建设过剩,租金优于自建,微软甚至可能使用开源模型来支持CoPilot。Baker认为,这表明仅仅依靠规模扩张建立堡垒的“预训练时代”已经走到了尽头。
数据“独一无二”
Baker认为,在这样的背景下,大型模型层出不穷,而模型架构却大不相同,“独特”的数据是决定性胜利的关键。他进一步指出,谷歌和Xai都有独特而有价值的信息来源,这将使他们与Deepseek、OpenAI与Anthropic的区别越来越大。
他说:“我多次重复EricVishria的话,前沿模型无法获得独特而有意义的数据,是历史上跌价最快的资产,而蒸馏只能放大这一点。”他写道。
大模型蒸馏(Large Model Distillation),简单来说,就是把一个复杂的大模型(教师模型)的知识转移到一个小模型(学生模型)。就像老师把自己渊博的知识传授给学生一样,让学生在资源有限的情况下,尽可能展现出与老师相似的能力。
Baker还指出,假如未来的前沿模型不能打开YouTube、X、TeslaVision、和Instagram和Facebook 等待独特而有价值的数据,则可能没有任何投资回报。独一无二的数据最终可能成为预训练数万亿或数千万亿参数模型差异化和ROI(投资回报)的唯一基础。
格局变化
根据Baker的总结,如果这是正确的,那么巨大的数据中心只需要2-3个,推理所需的计算率占95%。AI计算的其他部分将是一个较小的数据中心,这些信息中心已经优化了地理空间,以实现低延迟和/或成本效率推理。
他解释说,基于量化压缩技术(例如Deepseekek),成本效率推理=更便宜的电力(核能溢价更低) R1的1-bit LLM)支持低成本推理。
Baker总结说,不像以前的预训练和推理阶段,计算资源配置大致各占一半,现在就会变成预训练占一半。 推理阶段占5%,占95%。优秀的基础设施尤为重要。
最后,他还提到,如果OpenAI在五年后仍然是这个领域的领导者,那可能是因为先发优势和规模优势,以及产品知名度。
他写道:“时间会证明一切。
本文来自微信微信官方账号“创业板观察”,作者:黄君芝,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com