
四人烧毁数百万GPU,创建翻版「Sora」





想要打造一个“”Sora"模型,至少需要多少人?
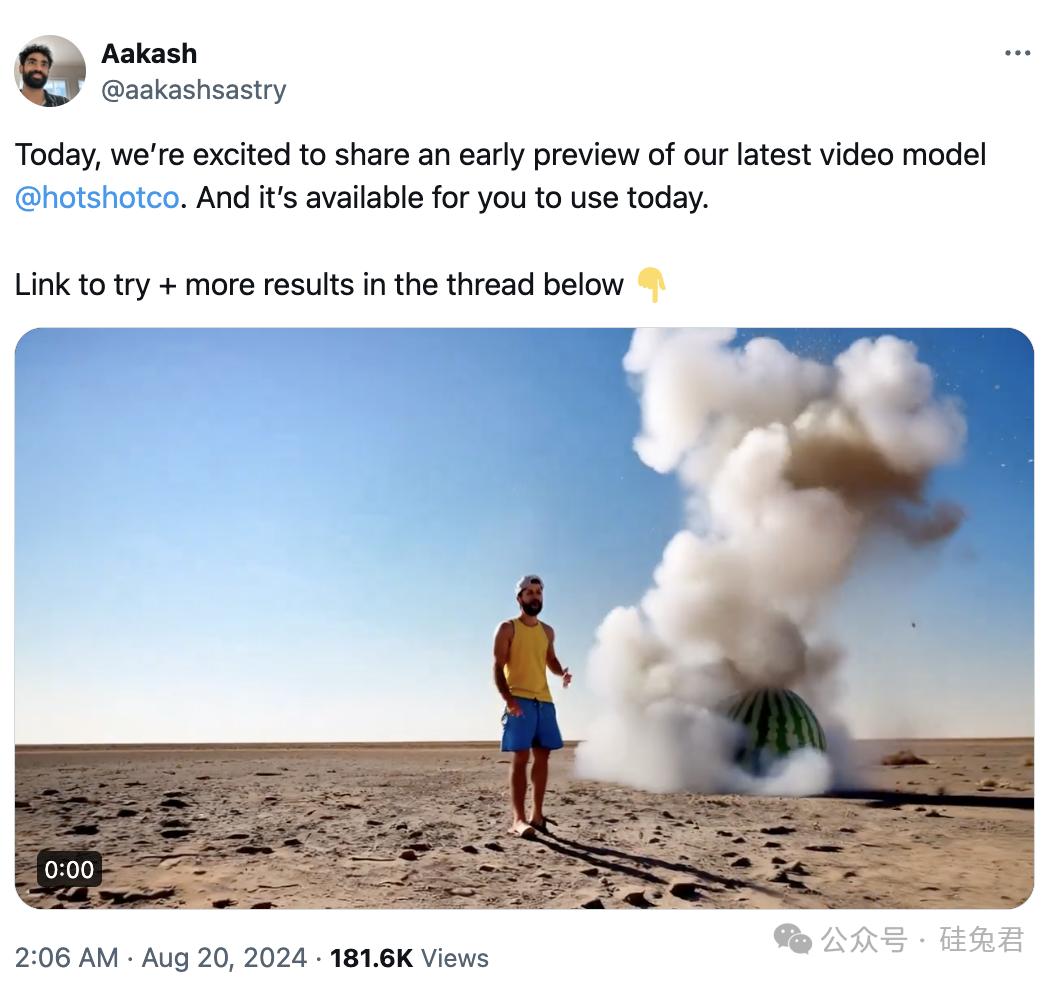
刚刚,美国AI企业Hotshot发布了其视频模型的初期预览版本。——Hotshot,整个OpenAI只用四个人就完成了。Sora"团队工作量。
5秒AI视频产生的Hotshot
Hotshot是一种Transformer扩散模式,在快速对齐、一致性和运动性方面表现良好,同时可以扩展到AI视频,生成时间更长,分辨率更高。根据Hotshot官方博客的说法,Hotshot最新版本的数据训练从端到端都需要时间。 4个月 ,一小时消耗 数百万 H100。
官网Hotshot
Hotshot给出了一些与其他同行比较的Hotshot文生视频的相关案例。
举例来说,这是一段“一名20岁的男子坐在棉花云端,在蓝天上看书”的视频。

或是,一只泰迪熊戴着太阳镜,在巨大的瀑布前,在丛林中弹奏电吉他,跳舞,摇头晃脑。
可以看出,在这些视频中,Hotshot表现出的效果相对超清晰,画面相对准确,视频长度保持在5秒左右,画面流畅。Hotshot创始人说:“我们看到70%的客户更喜欢Hotshot的结果,而不是其他文化视频模型。
现在,Hotshot的测试版已经在官方网站上提供了试用,而且生成视频没有任何水印。每个用户 每日有两次免费生成视频的机会 。
官网链接:https://hotshot.co/
训练GPU就像开火车一样,保持每一个环节都不能掉队。
在软件行业,训练模型就是火箭发射。
每一次提升程序都是对情感和理性的极大考验,尤其是金钱方面。
创始团队在他们的博客上分享了他们从0开始创建文化视频模型的经验和有趣的故事。例如,他们几乎烧毁了机房,硅兔君也看到了创业公司对AI的热情。
Hotshot成立于2023年,共有三位创始人,Aakash Sastry、John Mullan和Duncan Crawbuck,他们都有11年的消费级应用经验。他们还分享了他们的博客从0开始创建翻版”Sora“四个关键步骤 :资料工程,研究,训练,以及扩展过程和思考。
在原文的基础上,硅兔君编译了以下enjoy。~
01数据工程:设定2亿个目标,构建自己的视频和图像数据库
由于Hotshot需要扩展模型数据工程来训练更大的模型。在早期阶段,他们设置了模型。一个目标:扩展词库6亿一个视频编辑,这需要承担巨大的运营费用。
Hotshot通过联合使用图像和视频来训练模型,从而构建比视频更丰富的公开访问图像数据。他们设定了一个新的目标,将图像词库扩展到图像词库,因为他们没有自己的图像词库。10亿张图像。
虽然现在有许多公开的VLM可以用来添加字幕(LLaVa、CogVLM 等等。),但是因为是针对图像理解而不是视频训练的,所以更擅长空间理解(颜色、物体、人物等)。),但在时间理解(动作和事物随时间变化)方面并不令人满意。
针对这一情况,Hotshot创建了一个300K的视频样本数据集,其中包含集中的时间字幕,并以所需的风格手动添加字幕,并对公开可用的VLM进行微调,以便进行视频理解。几个星期后,Hotshot创建了一个用于注释数亿个视频样本的视频字幕生成器。
能够处理数十亿张图片和视频编辑的视频字幕生成程序并不容易。其中,最难的是他们需要在云端管理数千个GPU。“我们团队每月24小时盯着这些GPU工作。”Hotshot创始团队提到,“这就像你一夜之间需要数百或数千名基础员工。他们也有自己的想法,不懂事。”
02研究:自动编码器通过超参数训练自行研发
要想快速得到一个优秀的模型,只需要像Hotshot一样,在众多优秀的模型中,开源存储库选择一个,你就可以有一个好的开始。他说:“我在Meta的时候,也曾经这样建立了基于Transformer的Diffusion。 Hotshot创始人提到了Model模型。
几天后,Hotshot得到了DiT。(Diffusion Transformer)ImageNet训练模型的简单例子。为了有效地训练长序列视频,他们开始训练新的自动编码器来压缩时间和空间上的视频。

官网Hotshot呈现9种不同表达产生的视频。
Hotshot从来没有过重新开始训练自动编码器的经验,因此在这个过程中,模型训练的不稳定性带来了很大的困扰。在训练进行到一半的时候,Hotshot发现识别器已经启动,但是训练的实际效果并没有改变。最后,他们用不同的超出原来上限的参数数据重新开始训练,一天之后,生成器和识别器的损失开始逐渐减少。结果表明,Hotshot已经创建了一个新的自动编码器作为网络端输入。
03训练:确定合适的训练结构,可以提高20%的模型训练和推理速度
如果你想创建一个完美的素描视频,你需要首先确定训练结构,这将涉及一系列问题:例如,哪种类型的传播公式?网络的深度和总宽度是多少?
最后,Hotshot希望创建一个视频模型,可以产生随机的分辨率和最长的10秒。他们花了很多时间来评估几种不同的新结构,以提高模型练习和推理的速度约为20%。
扩散:H100训练几乎烧毁了机房,99%的时间都花在了基础设施和升级上。
随着计算规模的扩大,管理变得更加困难,IO变得极其瓶颈化,日志记录变得混乱,H100经常出现故障,尤其是在训练视频模型时。此外,随着计算规模的扩大,训练运行的成本变得更加昂贵,因此优化代码并尽可能快地运行是非常重要的。
Hotshot还发现,越是优化代码,提高GPU功率,GPU故障的风险就越大。"一个数据中心提供商告诉我们,机房几乎着火了,让我们少优化代码。"
但是机房起火并没有阻止Hotshot的热情。
在接下来的三个月里,Hotshot花了99%的时间在基础设施和推广上。Hotshot通过使用不同类型的数据/模型并行性来大规模提高数据, 为了尽可能快速高效地检索自定义核心,最大限度地降低其GPU成本,缓存数据。
作为一个创业团队,创始团队意识到训练模式是一种完全不同的冒险。内部,在软件行业,他们认为训练模型是火箭发射。"使用数千个GPU进行大规模训练就像玩具火箭直接去SpaceX一样。 发射Falcon。
它们还举了一个例子: 随着GPU数量的扩大,训练的启动时间将会增加。由于数千个程序流程正在从NFS驱动器中获取数据以尝试载入权重,用户必须在单个流程中开始使用分布式文件系统或平衡网络传输的权重。尤其是GPU经常出现故障,所以经常需要重新启动。而且,当数千个同步GPU中有一个过程挂起时,整个“GPU列车”就会停止工作。Hotshot编写了自己的监控软件,以跟踪原因,测试挂起的GPU,并确定原因。
另外,大规模的数据训练是对集群带宽的极大考验。
随着视频分辨率的不断增加,持续时间越来越长,在训练的同时解码高分辨率视频也越来越困难。最后,他们选择提前将自己的数据集计算嵌入到系统中,绕过解码视频和处理潜在视频和嵌入文本的过程,将下一个数据集的计算融化,从而缓解压力。
但是提前内置数据检索会占据很大的内存。针对这一情况,Hotshot改进了检索并将其压缩7倍,并将所有数据存储到bfloat16中嵌入。与此同时,Hotshot还使用Zstandard压缩数据块,并将其上传到S3,从而选择了尽可能靠近集群的物理存储区域。
"在机器学习训练中,提高数据比我们以前所做的任何其他事情都要花更多的钱." Hotshot创始团队调侃道。
0513个月连续发布三个AI视频模型,AI视频将抢滩数字媒体
Hotshot在过去13个月里建造了它。 3种 视频模型的不同。
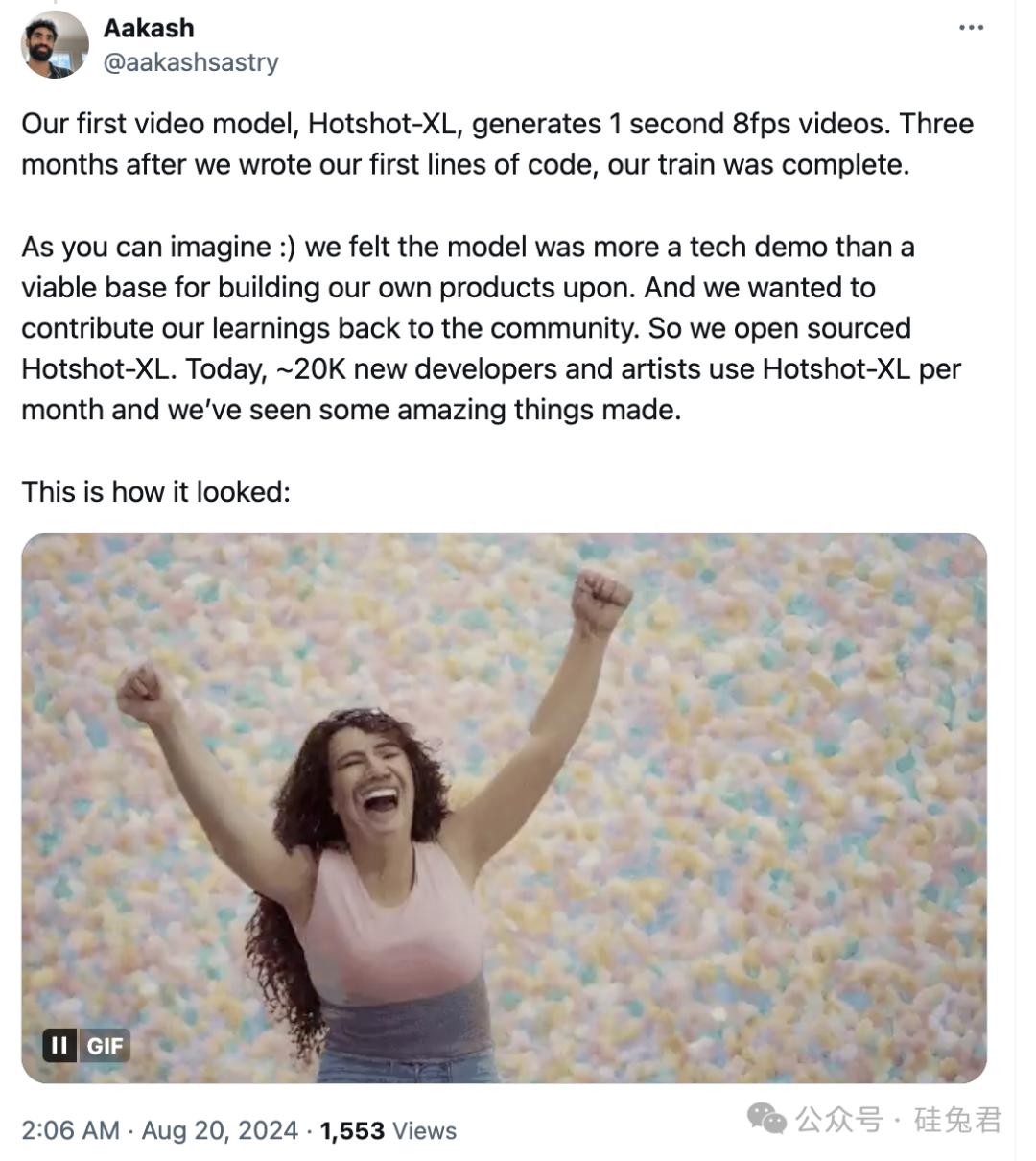
首个视频模型Hotshots-XL 可生成1秒8fps的视频,开发过程只需3个月。
但是Hotshot认为这个模型更像是一个技术演示,而不是作为建立商品的基础。与此同时,Hotshot希望能够将这个模型反馈给社区。因此,他们开源了Hotshot。-XL。现在,每个月大约有2万名新开发者和艺术家使用 Hotshot-XL。
Hotshotshot第二个视频模型 Act-One 可以生成3秒8fps的视频,训练需要5个月。
Hotshot在建立这个模型的过程中,可以将视频数据集扩展到2亿个带字幕的公开视频,并且第一次真正建立了大规模计算、分布式训练和高分辨率扩散模型。
Hotshotshot第三个视频模型 ,720P镜头可生成长达10秒。
Hotshot的创始人Sastry预测,未来12个月,AI生成内容可能会成为数字媒体的主流,尤其是在YouTube视频制作方面,创作者将能够完全控制从文本到视频甚至音频的生成过程。
2024年上半年,AI文生视频领域大跌眼镜。仅仅6个月,Runway就出现了。 Gen-3、PixVerse V2、Vidu、Dream 10多个AI文生视频模型,如Machine。今天,美国企业Luma Dream也发布了AI Machine 1.5,增强视频生成的真实感,提高运动跟踪效果。
Hotshot只有4人团队,能否在文生视频领域站稳脚跟?大家一起期待吧。
本文来自微信微信官方账号“硅兔君”(ID:gh作者:_1faae33d0655):Xuushan,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com