
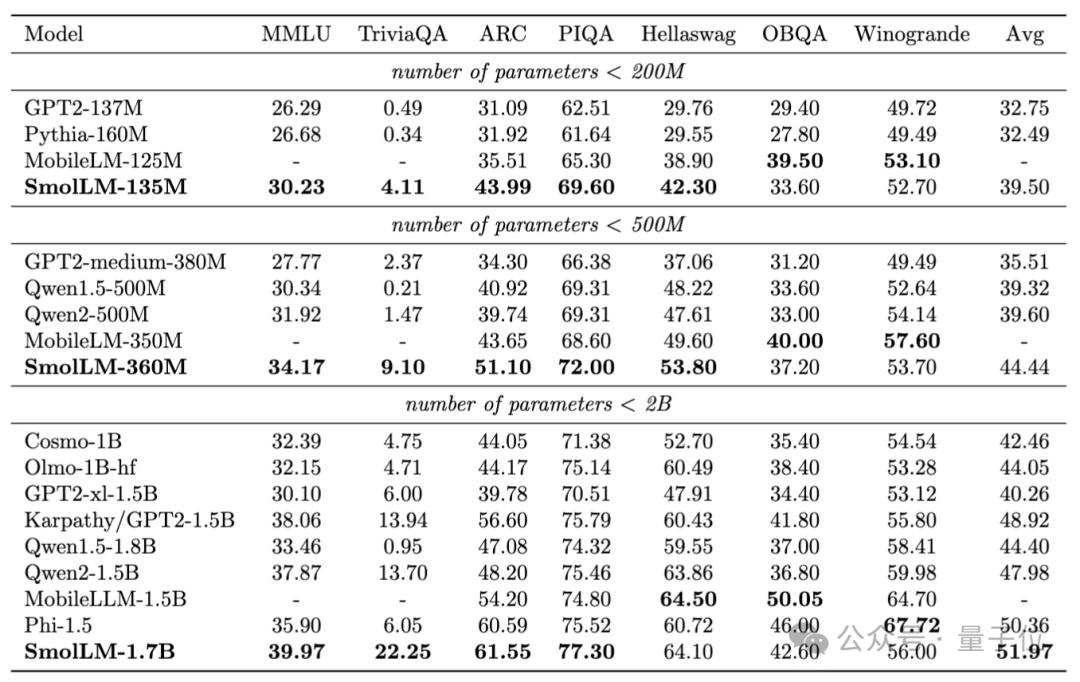
小型站起来,SOTA跑出浏览器,抱住脸:快逃,生成数据不是未来。






SOTA小模型可以在浏览器中直接运行,分别在2亿、5亿和20亿级别获胜,抱着脸生产。
只有两个秘密:
- 严格过滤数据
- 严格训练高度过滤的数据集。
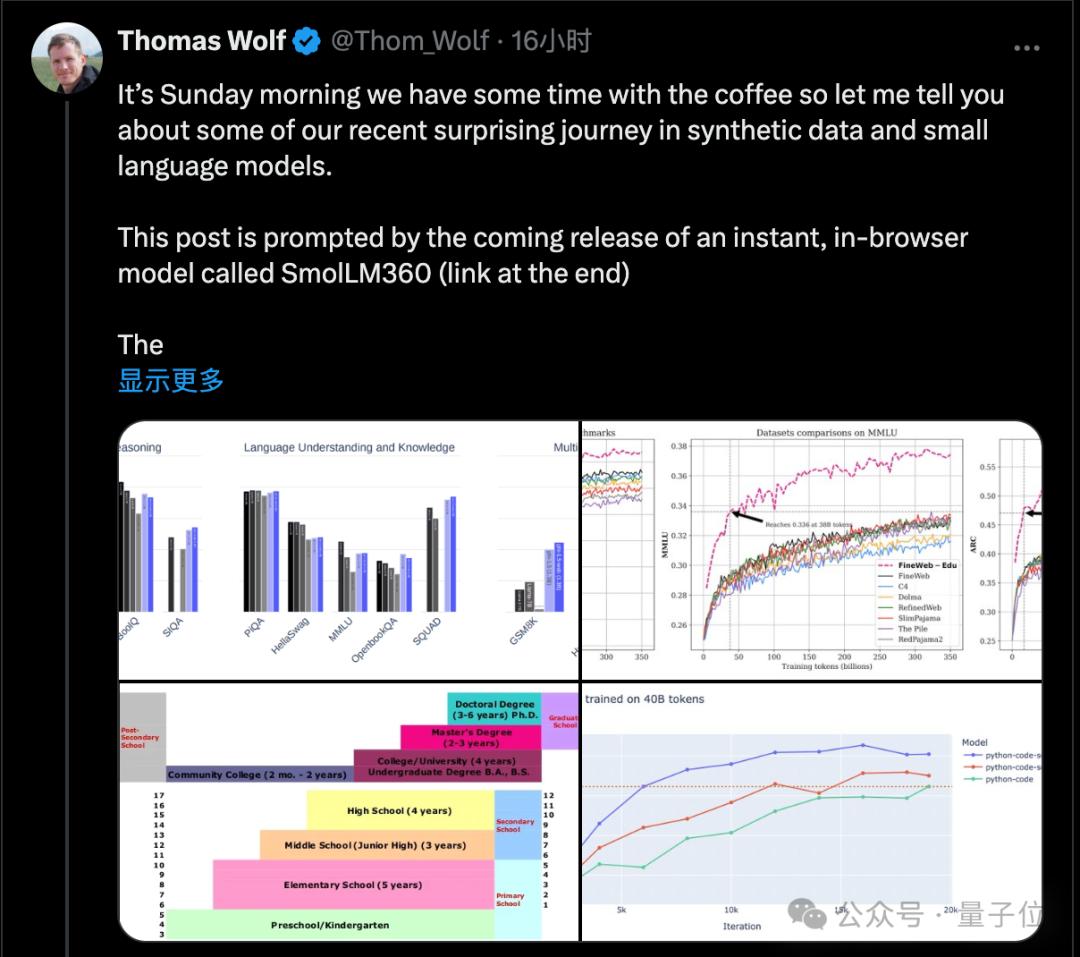
拥抱脸部的首席科学家Thomas Wolf,在开发小模型时,总结团队的经验,抛出新的观点,引起业界的关注:
目前生成数据只在特定领域有用。,网络是如此的大而多样化,真实数据的潜力还没有得到充分发挥。
现在360M模型版本已经发布了Demo,在线玩得很开心(注意流量)。

调用当地GPU在浏览器中运行,甚至模型权重带网页前端UI,400MB完成。

严格过滤网络数据,性能直线上升
对于微软Phi系列的小模型,声称使用了一半的生成数据,效果不错,但是数据不公开。
开源老板抱着脸看不下去了:
创建一个大规模的对标生成数据,开源它。
而且,团队隐约暗示,这一举动也有传言说微软在测试集上刷榜,到底有没有考虑到这件事。
Mixtral-8-7B结构是当时最好的开源模型。25B生成数据。
训练出来的模型效果还不错,但是在某种程度上还是低于Phi-1和Phi-1.5。
由于MMLU是博士水平的题目,他们试图让大模型在中学水平上解释各种主题,最终只是在MMLU检测方面表现不佳。
真正的性能突破,反而来自于一个支线任务:
除使用大型模型从头开始生成数据外,还尝试使用大型模型选择过滤网络数据。
具体而言,使用Llama3-70B-Struct 产生的标记开发了一种分类器,仅仅保留FineWeb数据集中最具教育意义的网页。。
使用严格过滤的网络数据后,包括Phi-1.5在内的所有其他类似尺寸模型都在大多数基准测试中直线上升,并超过了大多数基准测试。
拥抱脸团队称这个测试结果是“苦乐参半”的确:虽然模型性能比以往任何时候都要高,但是生成数据仍然无法与真实数据相比。
随后,他们以相同的方式从自然语言扩展到代码,过滤的代码数据也被证明是非常强大的。
直接将HumanEval基准测试结果从13%提高到20%以上。
最后,它们结构的混合数据集中,去重的过滤数据占绝大多数,纯生成数据Cosmopedia v2仅占15%。
所以一般来说,生成数据是否有用?
团队认为,只有真正缺乏真实数据的行业,比如推理和数学,可能更有意义。
即使是小模型也要训练数万亿tokens
就在他们对这些新的发现和结果感到兴奋的时候,一个新的见习生Elie 加入了Bakouch。
虽然他当时只是一个见习生,但他确实是一个精通各种训练方法的专家。
在Elie的帮助下,团队将模型尺寸从1.7B下降到360M甚至170M,即GPT-1、GPT-2和BERT。
另一个重要的发现是在这一过程中发现的:不同于过去的共识,即使是小模型也要在数万亿token上进行训练,时间越长越好。
此外数据退火(Anneal the data)还被证明是有效的,即在训练的最后一部分保留了一组特殊的高质量数据。
最终发布的系列模型适用于从智能手机到笔记本的各种设备部署,最大的1.7B模型BF16精度仅占3G内存。
作为参考,iPhone 15入门版也有6G,安卓手机更多。
尽管这次训练出来的基本模型足够好,但是团队还是发现了一个问题。
SFT等过去的对齐和微调技术、DPO、对于大模型来说,PPO等都是很有效的,但是对于小模型来说效果并不理想。
团队分析,对齐数据集中包含了很多对小模型来说太复杂的概念,而且缺乏精心设计的简单任务。
下一个新坑也挖好了,有兴趣的队伍可以开始建立,也许就成了小模型大救星。
在线试玩:https://huggingface.co/spaces/HuggingFaceTB/instant-smollm
参考链接:[1]https://huggingface.co/blog/smollm[2]https://x.com/Thom_Wolf/status/1825094850686906857
本文来自微信微信官方账号“量子位”,作者:梦晨,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com