
《Her》有形象,给AI打个视频电话,几乎没有延迟,红杉YC投票给AI,






AI是历史上最快的对话视频,延迟不到一秒钟!
端到端,能听,能看,能说,有形象。
这个产品不是来自OpenAI或者HeyGen这样之前已经施展才能的企业,也没有具体的名字。
因为来自创业团队Tavus,所以也叫Conversationalional Replicas by Tavus。
其主要功能是构建一种身临其境的AI生成视频体验。
今天上线后,已经冲到Producthunt今天的新产品热榜第一,点赞数量还在上升。
官方Tavus为大家总结了产品特点:
- 延迟不到一秒
- 数字孪生,现实,智能。
- 即插即用的端到端构建块
- 模块化、可定制的部件,例如LLM语音合成
看到网友们热血沸腾:
现在有“人”为我开ZOOM视频会议,哈哈哈哈!
也有不少网友把这当作网友人机交互界面比阅读文档或聊天更好。。
这段对话视频界面改变了游戏规则!不难想象互动体验的无限可能性。
可以在网页端试用2分钟
看到这个消息,量子位一秒钟就冲到了Tavus的网站上。
这段“史上最快对话视频”可以在官网上体验2分钟。
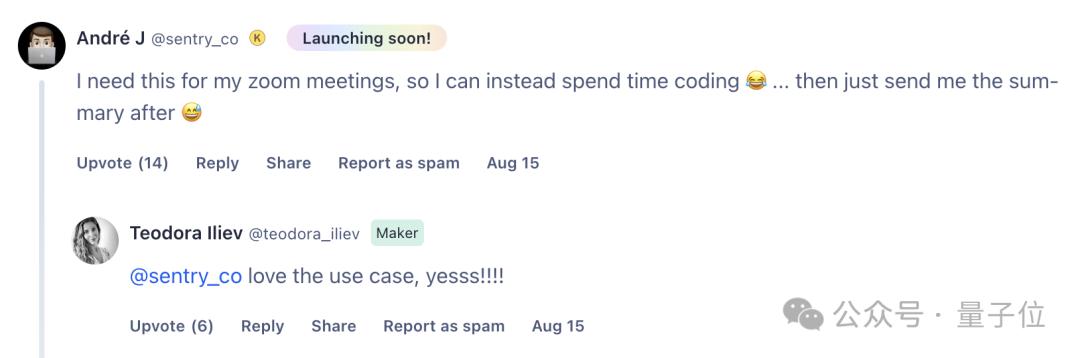
按照现有设置,Tavus塑造的卡特在感觉上的对话对象。
AI视频研究公司Tavus的一名员工卡特的形象定位,以幽默的方式回应,同时也很有帮助。
就是下面这个人:
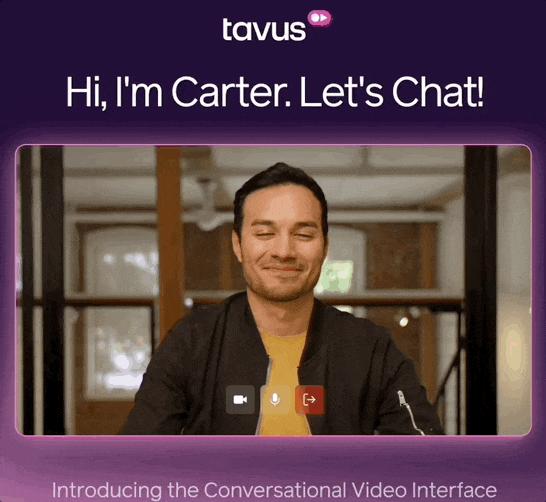
虽然卡特是个虚拟人物,但是和他的视频一样,就像是自己朋友的视频。
这位官员建议,在授权摄像机和麦克风之后,与卡特聊天时,尽量呆在一个安静的房间里。
卡特在谈话中提到,除了询问Tavus使用的AI技术,大家最喜欢和他讨论的几个话题就是分享他的日常心路历程和笑话。
那时他讲了一个笑话:
问,为什么自行车不能靠自己站在那里?答案是,因为它是tooo tired(Two tires)。
之后,卡特本人还自己为自己加油,哈哈两声。
实际体验了2分钟的量子位,整体感觉如下:
第一,Tavus反应速度确实特别快,符合官方所谓的“一秒之内”。
即使你在演讲过程中突然发出声音,卡特也能立刻停下来听你最新的演讲。
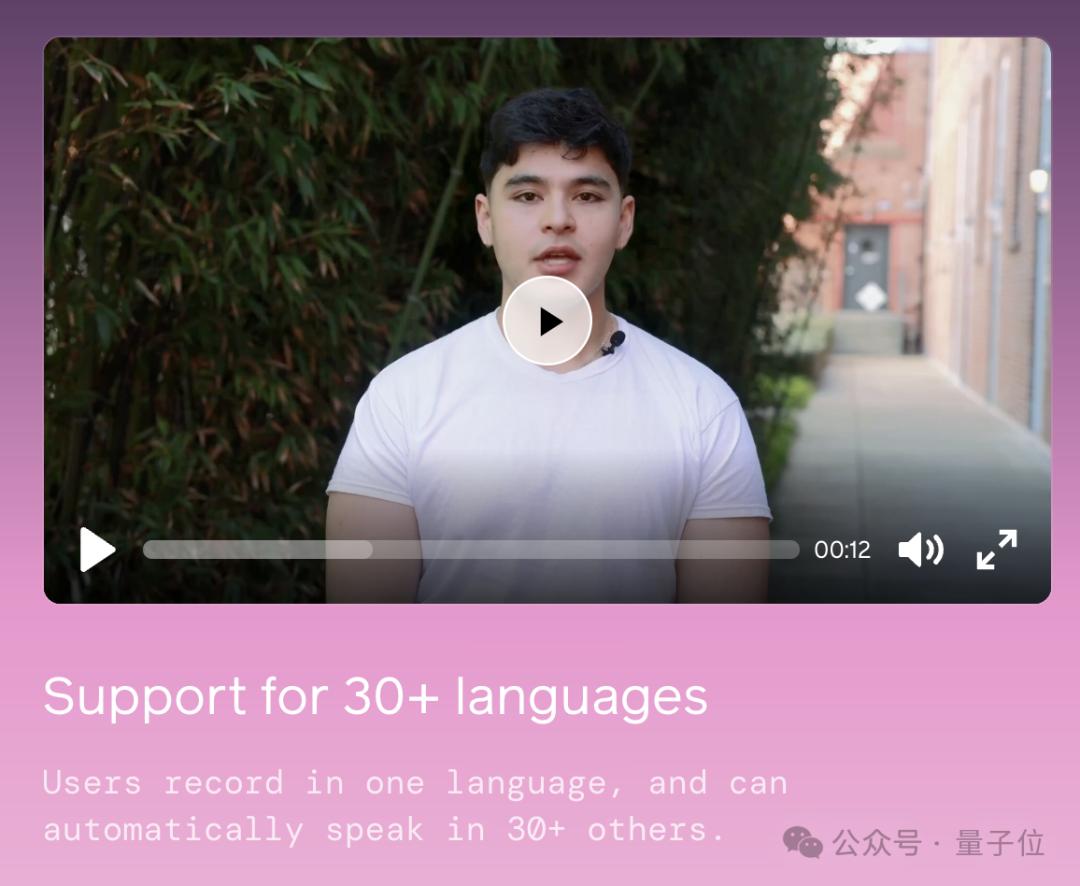
第二,尽管官方声称它支持30多种语言,但无论是用中文还是用英文提问,他都会问问题,不能说中文。
我们问他“Can u speak Chinese卡特会回答:“我更愿意用英语交谈!”
三是TavusAI的确可以“用眼睛看”。
在试用量子位的过程中,一度尴尬,不知问什么好,只能傻笑。
卡特立即张开嘴:
Oh!你们对我微笑着?~
四是在试玩版本中,卡特的口型和所说的话几乎可以完全同步。
这样也不难怪为什么有网友试玩后表示:
的确令人印象深刻,它具有快速响应、优秀的视频和音频生成能力。
现在,Tavus的对话视频AI只要注册就可以使用。
在官方版本中,可供对话的AI形象不仅仅是卡特。有男有女,身份设定从销售到生活指导等等,一应俱全。
聊天的背景也可以根据用户的选择进行更换,不拘泥于办公场景。
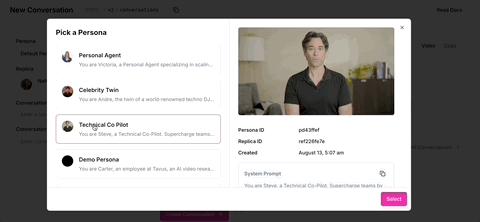
同时,还前后文可以手动输入对话内容。。
可说个性化定制水平非常高。
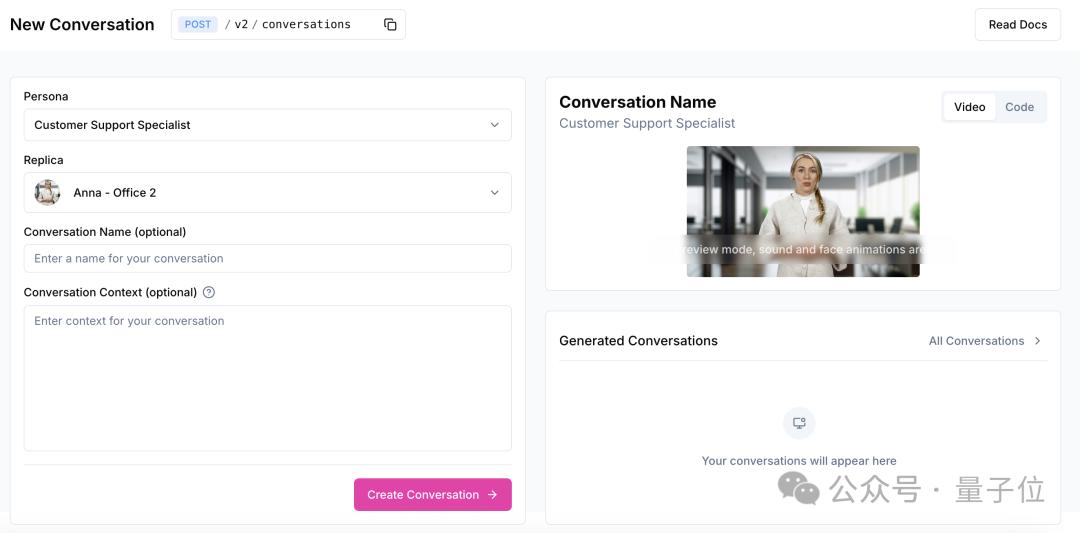
现在有免费版本,也有收费方式,对应不同的生成权益。
基于自主研发模型的开发
Tavus对话视频AI的背后,是Tavus团队开发的Phoenix-2模型。
3D模型和2D模型由音频和文本驱动。 配合GANs,可以生成1-2分钟的真实短视频。
生成过程主要分为以下四个步骤:
TTS(文字转语音)-头部和肩部的3D重建-提示词脚本驱动的面部动画-高保真渲染。
微调面部几何细节,通过差分渲染。
Tavus团队在建立Phoenix-2视频渲染pipeline时,为了使与用户对话的AI形象更加真实,GAN与3D高斯泼溅融为一体。
之所以这样做,是因为传统的GAN通常受到图像分辨率的限制,而体积模型总是缺乏时间一致性。
所以,Tavus想到把两者结合起来。
在训练GAN时,需要大量的数据集和昂贵的计算资源,而且由于其二维特性和时间一致性,一般推理时间和视频质量都会受到限制。
Tavus以3D模型为“中间体”,完成了100多个。 由于动态物体周围的物理感知约束,FPS渲染可以达到更高的可控性和实用性。
比较2D与3D头部演讲模型的区别。
此外,Phoenix-与系列前作相比,2模型的改进是取代了第一代Phoenix模型NeRF。
然后利用3D高斯泼溅来学习如何在3D空间中引入面部动态变形,并利用这些信息根据看不见的音频来渲染视图。
与NeRF相比,3D高斯在数据、内存、计算复杂度、流程、渲染效率等方面都表现得更好。
Phoenix-2模型pipeline基于3D高斯溅溅,可以以比第一代模型快70%的速度练习,60% 渲染FPS的速度。
Tavus说,在对话过程中,有回合结束测试和可中断性,让用户觉得对话更加准确。
另外,由于面部信息特别敏感,团队为保护信息安全提供了安全检查、安全协议、自动内容审核和反幻觉检查。
值得注意的是,Phoenix系列模型还支持Tavus的另一种商品。——
形成客户数字孪生形象的对话视频。
只需提供2分钟的素材,花费1美元(起),即可调用API生成视频内容。
官方提醒可以提供端到端的解决方案,具备以下能力:
- 使用API,构建安全、真实的数字孪生或AI。 Agent
- 定制LLM、人物角色与对话背景
- 内嵌式会议厅中流式传输对话
- 记录,转录和共享对话。
- 高流量的生产级可扩展性处理
"没有1s,就不是人"<1s,就不是人了”
Tavus团队是一家成立四年的AI视频创业公司,规模不大。
大部分成员来自Amazon、Descript、Google和Apple等等。
公开资料显示,截至今年3月,该公司已获得红杉,Scale VC、A轮YC投资,融资金额约为1800万美元。
联合创始人兼CEOTavus,名叫CEO。Hassaan Raza。
曾经在谷歌和苹果工作过。
该公司的联合创始人兼首席执行官在Producthunt上留言称,制作对话视频AI需要很长时间,研究、工程和建设大约需要几千个小时。
为何要追求1秒或更短的延迟?
这位官员也给出了答案,尽可能模拟人与人之间的视频对话。:
由于如果反应速度不低于1秒,那么(对面和你聊天)就不是人了。
参考链接
[1]https://www.tavus.io/careers
[2]https://x.com/heytavus/status/1824075891271749903
[3]https://www.producthunt.com/posts/conversational-replicas-by-tavus
本文来自微信微信官方账号“量子位”,作者:衡宇,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com