
基础系列:u200bLambda架构和Kappa架构








数据经理会相应地评估他们的结构模式,因为每天都有不同的使用场景。有些人坚持使用现代数据堆栈!有些人坚持使用开源解决方案来抵抗现代数据堆栈的宣传者,有些人只是试图解决问题。
不管你代表哪一个团队,都有一个共同的问题:数据处理。随着数据处理方法和工具的不断变化和发展。本文将介绍数据处理架构Lambda和Kappa它是数据处理架构决策的基础。
一个Lambda架构
在大数据系统中,Lambda架构用于处理。即时和批量NathanMarz提出了一种数据设计模式,旨在解决对大量数据进行低延迟处理的考验。
让我们先看一下用例,然后再深入了解架构的细节,以便更好地了解为什么,以及在哪里需要。Lambda架构。
常用用例:
Lambda架构适用于各种需要即时和批量处理大量数据的用例。一些常见的用例包括:
欺诈检测:为了识别异常的方式和行为,需要对信用卡欺诈或身份盗窃等欺诈活动进行实时分析。Lambda架构允许组织实时处理流数据进行即时检查,同时对历史数据进行分析,以改进欺诈检测算法。
物联网(IoT)数据处理:为了获得意见,采取适当的行动,物联网设备会产生大量的数据,需要对这些信息进行实时的处理和分析。Lambda架构可以实时处理物联网数据流,同时也可以进行批处理进行长期分析和优化。
推荐系统:个性化推荐系统用于电子商务、媒体流和社交网络平台,依靠即时用户交互和历史数据生成准确的推荐。Lambda架构有利于处理即时用户交互和历史数据审批处理,从而不断完善推荐系统。
组成Lambda架构
由三层组成的Lambda架构:
批处理层
批处理层负责大量处理历史数据,并将结果存储在数据仓库或分布式文件系统等集中数据存储中。我们通常将数据存储在视图、物化视图或可用的表中,这些视图通过升级、检索和可用。
批量处理层以不可改变的方式存储数据,只有附加的方式。它有助于组织存储其历史数据,并在必要时浏览它。
速率层
批处理层本质上是有延迟的。在大多数情况下,批处理数据每天更新一两次。在大多数情况下,它足以继续处理下游用例,但在某些情况下,延迟可能是一个问题。在这方面,为了最大限度地减少数据差距,我们应该通过流闪存提供数据。
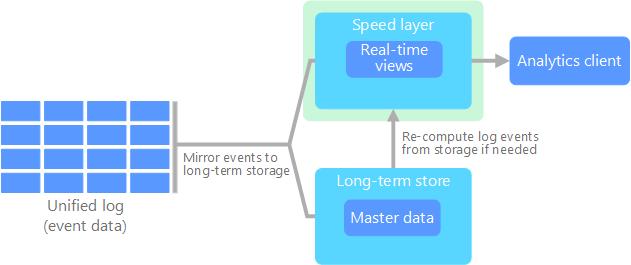
速度层负责实时数据处理。它处理传入的数据流,并以几乎即时的方式生成增量更新。随后,这些更新与批处理层的结果合并,提供统一的数据视图。速度层的工作是缩小数据创建时间和数据查询时间之间的差距。服务层
服务层是浏览数据的连接点。它结合了批处理层和速度层的结果,并提供了一致的数据视图。数据服务层根据预定义的时间表从批处理层接收批处理视图。该层还接收从速度层流传输的即时视图。
第二个Kappa架构
Kappa架构是一种数据处理架构,目的是提供一个可扩展、容错和灵活的系统。大量数据的实时处理。这是作为替代Lambda架构的方案研究开发。通过清除批处理层,对大数据系统的设计进行了简化,从而为实时动态处理提供了更加简化的方法。
常用用例:
Kappa架构适用于各种需要实时处理大量数据的用例。一些常见的用例包括:
实时监控和报警:Kappa架构特别适用于数据流量、服务器性能或应用日志等实时监控系统和应用程序。当出现异常、性能问题或安全漏洞时,它允许组织检查它们并触发即时报警或操作。
点击流分析:为了了解用户行为,优化用户体验,提供个性化的内容或推荐,网站和移动应用程序可以生成大量的点击流数据,并需要对这些信息进行实时处理和分析。KappaArchitecture使组织能够实时处理点击流数据流,并获得可操作的观点,而无需进行批处理。
供应链优化:Kappa架构可以通过实时处理来自库存系统、物流网络和营销渠道的数据流来优化供应链运营。它允许组织实时监控供应链绩效,识别瓶颈,预测需求,优化库存水平。
构成Kappa架构
Kappa架构由两层组成:
数据收集层
该层负责从各种来源即时收集和提取数据。数据不断流入系统,无需批量处理或预计计算。Kappa架构中的数据提取一般采用ApacheKafka或类似的分布式消息传输系统等技术。
流处理层
流处理层是Kappa架构中系统的核心。它处理实时动态和历史数据重放。ApacheFlink、ApacheSamza或ApacheStorm等流处理框架用于实时处理数据流。这类框架提供了对传输到数据流的复杂转换、分析和操作所需的功能。
三总结
Kappa和Lambda架构都提供了一个解决方案,可以通过即时和批量的方式处理大量的数据,每个架构都有自己的优势和用例。
Lambda架构为处理复杂的数据处理需求(包括历史分析和批量计算)提供了一个强大的框架,具有批处理、速度和服务层。
另一方面,Kappa架构通过清除批处理层,简化了设计,只专注于实时流处理。这种简化方法减少了延迟,简化了维护,为实时动态和历史数据提供了统一的处理模型。
Kappa和Lambda架构选择取决于用例的实际需要、平衡延迟要求、数据复杂性和系统复杂性等因素。
本文来自微信微信官方账号“数据驱动智能”(ID:Data作者:晓晓,36氪经授权发布,_0101)。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com