
AI芯片战争:英伟达是科技之巅,还是下一个思科?







随着ChatGPT,2022年底 3.5的诞生让一些安静的人工智能技术再次成为人们关注的焦点。大量大型软件企业和科技创业公司正在投资资源开发生成大型语言模型(以下简称“大模型”或“LLM)、Gemini、Llama等大型模型竞相出现,呈现出“百模对决”的繁荣景象。
在实践和推理阶段,大语言模型需要巨大的计算率支持。作为这两个阶段计算中的重要计算芯片,GPU的需求随着大语言模型的普及而迅速增加,甚至供不应求。GPU芯片的主要供应商英伟达达得益于需求的扩大(NVIDIA)股票价格也迅速上涨。英伟达于2020年7月10日以2513.14亿美元的市值首次超过英特尔2481.55亿美元的市值,成为全球市值最高的芯片公司。英伟达总市值在2024年4月9日达到2.1亿美元,超过亚马逊、谷歌、Meta、仅次于微软和苹果的特斯拉等知名企业位居世界第三(图) 1)。
图 1 美股市值最高的20家公司和思科公司市值(单位:10亿美元),注:本图前20家公司(微软~P&G)按当日总市值排名。思科当天在美股市场排名第45位,列入图中分析思科数据需求。数据来源:东方财富Choice数据(数据获取时间2024/4/9)
假如熟悉因特网发展的历史,许多人可能会想到英伟达在因特网爆发初期的思科。(Cisco)。20世纪90年代末,互联网在美国迅速普及,对路由器、交换机等网络设备的需求飙升。作为该行业的龙头企业,思科的市值也在稳步上升。思科的市值在2000年3月达到5550亿美元,成为世界上市值最高的公司。不过,随着2001年因特网泡沫的破灭,思科的市值也随之下降。如今,思科的市值约为1953亿美元。虽然它仍然是一家巨型企业,但与微软、谷歌、亚马逊、Meta等网络平台和云计算公司的市值相比,已经有了很大的差距。
所以有人认为,在互联网时代,软件和平台企业都取得了成就,因为它们可以通过互联网效应获得超额利润。虽然硬件公司很重要,但由于需求有限,总需求在初期快速普及阶段爆发后趋于稳定,硬件公司很难获得超额利润,这将进入稳定增长期,如英特尔和高通。
英伟达是否会类似于思科的发展轨迹,应该回答以下三个问题,而不是简单地将AI时代与网络时代、GPU与路由器进行比较。
- 以LLM为代表的AI技术,是否会延续巨大的计算能力需求?
- 短期内,AI计算中是否会出现比GPU更高效的芯片?
- 在目前的生态中,英伟达能否被取代?
下面的内容,将讨论上述问题。
大语言模型:昙花一现,还是改革前夜?
一个关键因素是市场对GPU的需求是否会持续,英伟达能否持续高增长。就行业而言,目前对GPU需求最大的行业,应该属于AI相关领域。AlphaGO于2016年推出,可视为现代AI发展的第一年。自2016年以来,英伟达的市值一直在上升,直到2022年超过英特尔市值,收入仍低于英特尔(图) 2)。这是因为AI在此期间的应用场景有限,主要包括客户分类、生产质量控制、供应链优化、金融风险控制、图像识别、语音识别等。由于情景的限制,部署的公司数量有限,主要集中在金融、消费、媒体和制造业等方面。与传统的分析工具相比,这种分析式AI对计算能力的需求有所提高,但并非爆发式增长。
图 2 与英特尔相比,英伟达的市值和收入来源:东方财富Choice数据
ChatGPT2022年底 3.5推出,大语言模型展现了强大的语言生成和理解能力。在自然语言生成、程序代码、机器翻译等领域展现了巨大的发展前景,吸引了行业巨头和创业公司纷纷进入市场。与分析型人工智能相比,大语言模型几乎可以应用于所有行业。大型语言模型接近于人类的自然语言理解能力,使其应用与以往的AI商品显著不同。
第一,在继操作系统之后,大型模型可能会成为新的底层应用。大型模型的形成能力可以大大简化应用程序的开发进度;然而,一些简单的功能甚至可以直接在终端上生成相应的功能,而无需单独安装应用程序。2024年世界移动通信大会(MWC 2024年),德国电信展示了一款由大模型驱动的概念手机。用户只需输入“发送图片、推荐旅游目的地”等指令,无需安装地图、照片等单独应用即可实现相应功能。
第二,大模型可以通过代理代替人类操作员。(Agent)直接连接到其他专业应用中进行操作。由于大型模型具有思维链的能力,能够理解前后文并进行对话,从而实现大型模型对执行结果的跟踪和改进。比如微软的AutoGen开发框架可以为大模型设置不同的角色,让每个角色都有不同的知识背景和目标约束,通过角色之间的自动对话和反馈,不断改进功能,从而达到预期的效果(图 3)。
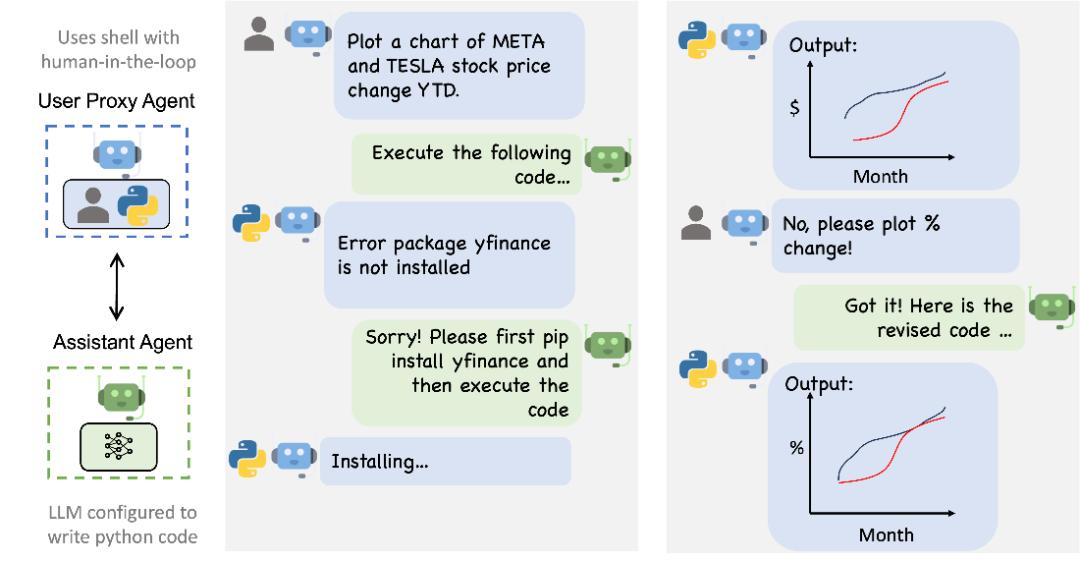
图 3 AutoGen流程的数据分析,数据来源:With Autogen, Microsoft Simplifies Putting Large Language Models to Real Work(www.bigtechwire.com)
第三,RAG可以使用大语言模型。、根据实际应用领域定制和优化微调、迁移学习等技术,使其能够适应不同的业务需求和数据情况,形成行业专属的大模型或知识库系统。如彭博(Bloomberg)BLOOM模型基于开源,使用公司超过7个 000亿词例(Tokens)大型金融训练词库进行实践,开发了专门的金融大语言模型——Bloomberg GPT,完成了市场情绪分析、新闻分类、问题回答等功能。
从本质上讲,大型模型是一种存储神经网络权重的参数文件,其推理、知识检索、代码生成等功能依赖于神经网络参数的质量。所以大型模型的性能有“0” or all“特征,即要不全面领先,要不全面落后,很难在某些领域领先。因为如果需要专业领域的模型,可以用先进的大模型进行微调训练,不需要重新开发,所以赢家通吃的效果非常明显。
从市场竞争趋势来看,虽然OpenAI的ChatGPT仍然处于领先地位,但是从多项测试表现来看,谷歌、Meta、亚马逊,微软,Mistral AI、与OpenAI相比,xAI等公司的商品也在逐步缩小。在这种模式下,目前大模型制造商仍将继续大规模投入GPU计算率,进行大模型练习,以期在竞争中获胜。由图 4我们可以看到,大模型在计算率方面的竞争仍在继续。因此,从行业发展的角度来看,英伟达GPU的大模型仍然会在相当长的一段时间内维持大量的需求。
图 4 大型训练阶段的主要计算率:petaFLOP是指每秒1000万亿次的数学运算,资料来源:Epoch (2023) – with minor processing by Our World in Data. “Training dataset size” [dataset]. Epoch, “Large Language Model Performance and Compute” [original data].
CPU:过去的王者,为什么会失去AI时代?
英特尔是芯片行业市值和收入最高的公司,在英伟达市值飙升之前。微软和英特尔“Wintel“联盟曾经被认为是最成功的产业组合。在现代计算机架构中,英特尔是辉煌的,CPU(Centralal全称Central Processing Unit,在整个产业链的核心位置上,中央控制部件是所有系统的核心控制模块。
现代化计算机架构模式,采用冯·诺依曼架构(图片) 5)计算机由输入设备、输出设备、存储器、计算器和控制器组成,其中控制器和计算器的功能通常由CPU实现。早期的CPU受技术水平的限制,不能集成大量的晶体管,所以CPU对指令集进行了选择,主要满足通用计算所需的逻辑运算和整形计算所需的性能,而浮点运算能力较弱。为了弥补CPU的劣势,英特尔推出了8087数学协会处理器,通过设计特殊的硬件架构和指令集来提高浮点计算性能,从而帮助CPU更好地实施大部分、指数和三角函数的科学计算。
图 5 数据来源冯·诺依曼计算机结构:维基百科
然而,分离式设计只是权宜之计。硬件分离大大延迟了协处理器和CPU之间的数据交换,拖累了计算机系统的整体启动速度。从那以后,CPU的发展思路就是不断增加晶体管的数量,扩大更多的控制功能,提高更强的计算率。
一九八九年,英特尔发布了80486 CPU,集成了120万个晶体管,增强了浮点运算的组件和指令集,集成了数学协处理器,CPU终于不再需要协助芯片支持进行科学计算。一九九六年,英特尔发布了Pentium MMX CPU,为了提高CPU处理多媒体的效率,增加了一组新的硬件,并添加了一组MMX指令来操作上述硬件。Pentium MMX确定了英特尔后期CPU升级迭代的基本方向,即根据用户需求在CPU中添加相应功能的硬件,通过发布相应的指令集来扩展和增强硬件的功能。
英特尔知道生态的重要性,除了在技术上保持领先。在操作系统的支持下,CPU性能(特别是新指令集)的发挥非常依赖,英特尔与微软保持着密切的合作关系,微软Windows操作系统率先支持英特尔的指令集,充分发挥CPU的新特性,获得比竞争对手同期产品更好的性能。所以,英特尔CPU比竞争对手AMD更受科研、工业等专业领域用户的青睐。
在AI时代到来之前,“Wintel联盟”实际上主导了个人计算机产业的发展。AI训练带来了前所未有的计算能力需求,计算机计算核心逐步从CPU转移到GPU。多个运算单元在CPU发展过程中被整合,但GPU却无法完全整合。因为CPU的功能主要是实施通用计算,通用计算主要是整数类型计算,而目前AI相关的计算主要是浮点计算。浮点数和整数计算在计算机设计中是不能共同使用的,所以即使CPU增强了大量的浮点运算模块,也不能用于整数运算,这样会造成CPU功能和成本的巨大浪费,这显然是CPU制造商无法接受的。
因此,英特尔和AMD的CPU只是整合了基本的GPU模块,以满足普通用户对图像和视频处理的基本需求。对于用户和CPU制造商来说,如果客户需要更强大的GPU计算率,并根据需求组合相应的GPU是一个更经济的举动。
因此,从硬件架构和商业行为来看,CPU制造商不太可能提供具有强大AI计算能力的CPU。在AI时代,CPU的失位不是起步晚,而是行业计算率迁移的自然结果。
GPU新王登基:游戏中诞生的生产力
在计算机演进过程中,被中国父母视为“洪水猛兽”的游戏行业催生了AI行业最重要的软硬件产品——CUDA和GPU。
一九九五年,微软公司推出Windows 这个划时代的操作系统,个人计算机迎来了图形操作面板。图形界面的出现大大降低了计算机学习的门槛,计算机逐渐从专业客户走向大众市场。Windows 在95系统中,微软做出了一个看似“无所事事”的选择,即开发Direct X API界面,为游戏开发者提供统一的图形和多媒体处理界面,减少兼容性问题,简化开发过程,提高游戏的性能和质量。使用Direct X,游戏制造商可以在Windows平台上快速开发出画面精美的游戏,这不仅吸引了游戏制造商的支持,也赢得了个人用户对Windows计算机的青睐。
随着网络游戏的蓬勃发展,GPU对AI算法的强烈支持出乎意料。因为游戏图像的渲染是通过产生大量的多边形(通常采用三角形)来完成的。图 6展示的古墓丽影游戏角色劳拉的画质进步,可以看到左边第一代游戏画面的人物有明显的棱角(约300个多边形),右边第十代游戏中的人物形象非常接近真实效果(使用了20多万个多边形)。

图 6 古墓丽影游戏角色劳拉的画质提升,资料来源:www.gmly.com
在游戏中,多边形的计算有三个特点。第一,多边形顶点的坐标包括x。、y、图像数据由Z三维数据和颜色等信息形成矩阵。物体的运动变化是矩阵的运算。第二,游戏中物体的移动是不规则的,所以游戏数据要用浮点数存储和计算。第三,游戏场景的设计通常非常复杂,需要大规模的并行计算。
GPU制造商为了满足运行游戏的性能需求,采用了不同于CPU的设计方法。以矩阵乘法为例,矩阵运算可以分为多个单独的计算步骤,无需区分顺序,因此可以并行计算。GPU的设计提高了这一特点,即设计了大量的小核心,可以并行运行数千个过程,每个过程只执行简单的数值计算(图表 7)。
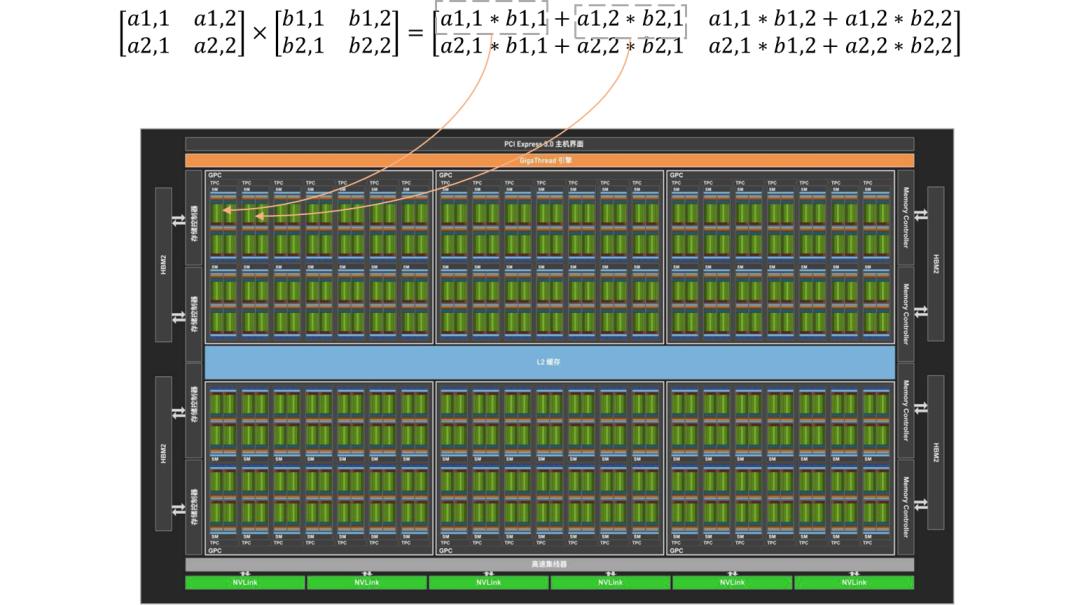
图 7 GPU矩阵运算示意图,资料来源:英伟达官网(www.nvidia.cn)
像GPU这样的大规模并行计算的特点,让黄仁勋思考,那些大规模的数值计算是否也可以通过GPU进行?
英伟达的策略是为开发者提供一个通用的程序开发平台,让程序员在不关注硬件实现的情况下,在主流编程语言中直接调用相关函数。这样就推动了英伟达CUDA(Compute Unified Device Architecture,推出统一计算设备架构)。CUDA包括三个层次:编程语言、编译系统和函数库。熟悉C的程序员可以继续使用、对于GPU资源的调度,Python等语言编写程序由编译系统完成,程序员只需关注程序的思路,这大大降低了基于GPU程序开发的难度。
Geoffry2012年多伦多大学荣誉教授 Hinton和他的团队使用CUDA开发的图像识别软件AlexNet参与ImageNet ILSVRC图片识别赛,以惊人的优势获胜(速度比第二名高几十倍,错误率比第二名低10%)。这次比赛成了黄仁勋的突破口,业界开始关注英伟达的CUDA技术,并与他们一起推广计算生态。在工业领域,如流体力学、有限元分析、油气开发等。,CUDA加速软件的运行已经使用,结果可以通过缩短几个小时来获得,原本需要几天才能完成。AI领域,Google、在CUDA加速的基础上,Meta等公司与英伟达合作推出了TensorFlow等底层AI技术。
CUDA为英伟达奠定了技术基础,而真正推动英伟达爆发式增长的,则是大型研发的“军备竞赛”。图 8是大模型推理过程中一个阶段的可视化图形。可以看出,基于神经网络算法的大模型是一个巨大的矩阵运算,这是英伟达GPU最擅长的计算类型。大型模型动辄数百亿的练习参数,带来了巨大的计算能力需求,促使GPU接管CPU,成为AI时代最基本的计算设施。
图 8 nano-gpt神经网络运算部分可视化,数据来源:bbycroft.net
软件与芯片协同设计是CUDA最强的环城河。AMD支持的开源OpenCL在软件技术方面具有与CUDA相似的功能,并能在其它GPU上运行。然而,真正挑战CUDA还很遥远。CUDA积累了几十年的高性能程序库,基于这些程序库上方社区开发的各种高性能框架代码,显然不可能大规模更换。但是在高档GPU领域,目前还没有一家厂商的芯片算率能够与英伟达竞争。
就产业生态而言,英伟达更像“Wintel“联合体,位于AI时代的主导地位。就像打破“Wintel“联盟是智能手机,为了打破英伟达在AI时代的地位,可能需要一个全新的行业。
随着异构计算的兴起,英伟达还能辉煌多久?
英特尔于2023年12月宣布推出全新的酷睿Ultra系列CPU,将NPU集成到CPU内部。(Neural Processing Unit,为了在当地更快地运行AI程序,神经网络控制部件)用于加快神经网络计算。几乎在同一时期,AMD还提出了Ryzenenenen在其新锐龙8000系列CPU中。 通过整合NPU加速AI计算的AI概念。
除PC芯片两大巨头外,专注于手机芯片的高通还推出了骁龙X Elite/Plus CPU,以ARM架构更高效的能效比为差异化优势,进入PC市场。另一方面,苹果计算机在需要大量GPU显示的推理场景中,凭借M系列芯片统一内存架构的优势获得优势。
竞争者纷纷进入市场,英伟达的领先优势能否持续?
对这个问题的分析,需要区分两个阶段的大模型,即训练阶段和推理阶段。训练阶段是大型模型的研发阶段。在这个阶段,模型会通过输入数据进行多次迭代,不断优化模型参数,使模型能够更好地拟合数据,提高预测准确性。这一过程需要大量的计算资源。推理阶段是指在模型训练结束后,将其应用于预测或推断实际数据的时期,即应用阶段。模型在推理阶段接收输入数据,并利用之前学到的参数和规律来进行预测、分类、生成等任务。由于模型参数值已在训练阶段确定,因此在推理阶段通常需要较少的计算资源。
上述厂家推出的芯片主要用于加速大模型推理阶段。目前,大型推理工作主要由服务器端提供服务,计算负荷集中在服务器端。所以大型企业为了支持大量用户的推理请求,对英伟达的GPU有很大的需求。但是这种趋势正在发生变化,智能助理是大模型应用的一个重要场景。(Agent),因此,个人计算机或手机需要在一定程度上摆脱对网络的依赖,具备在当地运行大型模型的能力。
为了实现大模型本地推理的计算率,CPU异构计算方法可能会逐渐成为主流,即“CPU 内置GPU NPU“这和CPU在历史上是一样的。 数学协处理器的方法比较相似。在短时间内,以神经网络为核心算法的大模型不会发生很大的变化,可以选择专用硬件。(NPU)加快计算速度。本地化的大型模型运行,在一定程度上会减少大型模型制造商对英伟达CPU的需求。
但在训练阶段,大模型规模法则(Scaling Law)仍然存在,即大模型的性能仍与训练规模成正比(图) 9)。此外,目前的大模型主要集中在对自然语言的理解上,多模型的大模型还没有得到充分发展。与目前的训练相比,大模型需要更大的GPU计算率才能真正成为通用人工智能和多模型的能力。
图 9 大型MMLU测试结果与训练数据的规模有关,数据来源:Epoch (2023) – with minor processing by Our World in Data. “Training dataset size” [dataset]. Epoch, “Large Language Model Performance and Compute”[original data].,注意:MMLU是一项大型、多任务的语言逻辑项目,旨在评估和提高各种语言逻辑任务中语言模型的能力,包括历史、文学、科学、数学等。MMLU并不能完全代表大语言模型的性能。
从大模型训练的过程来看,未来大模型的算率竞争还会持续很长时间,对GPU的需求会很大。这个市场基本被英伟达垄断,可以预测英伟达的快速增长还会继续。
英特尔和AMD的异构CPU在推理阶段将逐步成为主流。双方的技术路线也比较一致,预计将保持现有的竞争格局。高通(ARM架构CPU)的进入值得注意。在过去依靠单核性能的时代,ARM多核心、低功耗的结构是其主要缺点之一。如今,操作系统和软件对多线程的优化越来越成熟,对多线程计算的需求也越来越大。ARM架构将逐步获得更多的应用领域(ARM架构的CPU用于超级计算机富岳)。AppleM系列CPU的优点是内存结构统一,显存和内存没有区别,这在PC内存普遍较低的时代有一定的优势。但是随着PC异构计算的普及,内存配置的不断增加,苹果的这一优势难以持续,AI时代苹果面临的难题似乎更加严峻。
本文来自微信公众号“中欧商业评论”(ID:ceibs-cbr),作者:齐卿,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com