
开放模型与封闭模型的竞争格局:差距将如何演变





本文源自微信公众号“未尽研究”,作者为未尽研究团队,原标题为《开放模型缘何能与封闭模型拉开差距 | 笔记》
美国艾伦实验室研究员Nathan Lambert长期致力于开放权重模型的训练与跟踪工作。他去年发布的报告及榜单显示,中国的开放模型已全面超越美国,这一结论在中美两国均引发了强烈反响。
近期,Lambert针对开放模型与封闭模型的竞争态势提出了新观点,其中部分判断与我们去年底对今年开源模型的展望高度契合。
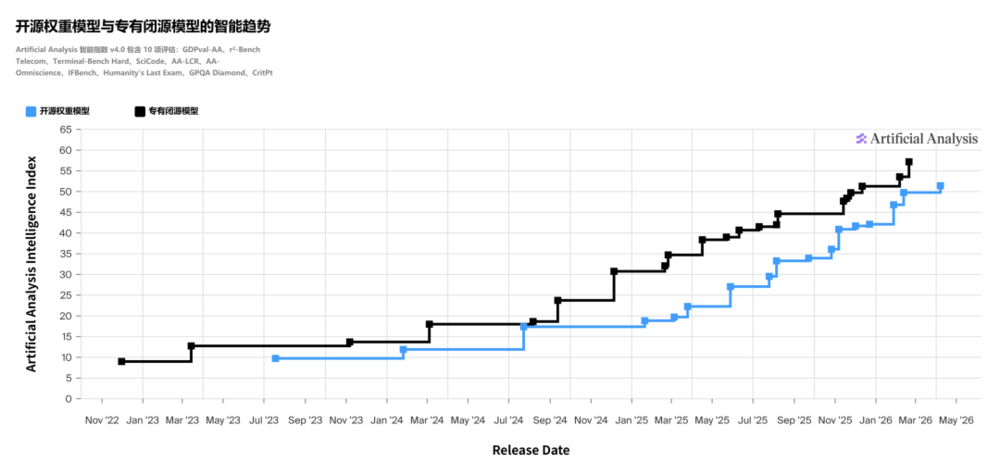
目前,中国开放模型整体保持领先地位,而美国的开放模型也在形成新的阵营,如Nemotron、Gemma等,有望收复部分失地。
2026年,关于AI的10个展望
2026/12/21 阅读全文>
此外,由于封闭模型在智能体性能和经济性方面持续优化,且开放模型缺乏商业支持,美国封闭模型预计将显著扩大领先优势。
以下是Nathan Lambert的文章内容:
当前阶段,我们正面临一个关键问题:开放模型能否跟上封闭实验室的发展步伐?表面上看,答案似乎是否定的。
这种观点的潜台词是,开放模型不可能在所有领域都与封闭模型并驾齐驱。它否定了一种流行预测——即开放模型会完全追平封闭模型,两者最终趋于同质化。然而,在实际观察中,我们很难判断能力上的长期稳定均衡何时会到来。
这是一个极为复杂的动态过程,核心关注点在于模型之间的能力差距。而这一差距又与多种不断变化的因素相互交织,包括开放模型的资金供给、开源模型的构建主体、蒸馏等快速跟进技术向新应用领域的迁移、可能阻碍开源AI生态的监管政策,以及开放模型的实际用户群体。
能力差距只是众多复杂因素中的一个信号,这些因素正将供给与需求推向不同的方向。在很多情况下,需求端(大量个人、组织和主权实体对开放模型的期待与需求)与供给端是相互分离的。供给完全由经济因素决定,而“哪些商业策略能支持开放模型的发布”这一问题至今仍未得到解决。
面对这种复杂性,我将核心观点提炼为一份清晰的清单。这些判断基于我今年春季围绕开源模型撰写或录制的10多篇内容。
1. 令人意外的是,即便考虑到训练和研究中的算力差异,顶级封闭模型在能力上并未对开源模型形成持续扩大的优势,尤其是在2025年下半年至今的这段时间。
2. 开源模型实验室在保持基准测试同步方面展现出强大的技术实力。这种情况将持续下去,反映出人才与算力的平衡状态。
3. 中国的开源权重实验室相比美国同类封闭实验室,更侧重于基准分数的提升。蒸馏技术帮助中国大语言模型公司实现了这一点,但它并非万能。蒸馏技术的动态变化(如监管政策)不会成为决定能力平衡的关键因素。对基准分数的高度关注,本质上是激励机制的结果——维持“正在追赶前沿”的叙事,对AI领域的融资和应用推广至关重要。
4. 目前,封闭模型往往比得分相近的开源模型更稳健、更具通用性。封闭模型具备一些难以量化的特质,这些特质未被当前或过往的基准测试充分捕捉。这将成为封闭模型主导某些市场的关键因素,尤其是在用户不断提出新需求的场景中,即模型作为直接助手为知识工作者提供支持。
5. 从基准测试来看,在市场结构收缩之前,开源与封闭模型的竞争很大程度上是一场关于经济续航能力和快速跟进的较量。我预计,中国的开源权重实验室可能最早在今年晚些时候面临融资困难,3到9个月后,这种困难将导致能力发展轨迹出现分化。
6. 在以强化学习为主导的训练时代,将模型部署到真实使用场景成为持续提升能力的关键因素。这些任务包括用户直接使用Claude Code或Codex等工具,通过智能体解决工作中的问题。这是封闭实验室首次在明确的技术领域有机会在能力上超越开放权重模型,并且可能直接利用基于用户反馈的在线强化学习技术。
7. 开放模型将越来越多地应用于重复性自动化任务,这将体现在整个生态系统中API市场份额的相对占比上,尤其是在重复性任务领域。其应用形式包括大量新的AI原生应用、企业后台自动化等。这方面的成功将推动对特定领域、高效率开放模型的更多投资。
这是一幅复杂的图景,其长期发展轨迹更多取决于经济因素而非技术能力。许多渠道倾向于传播更简单的叙事,例如“中国AI必然会追上我们”,因为这类故事更容易被接受。但现实是复杂的。只有真正的AI收入才能带来更多投资,而这最终又与模型持续快速改进的能力相关。到目前为止,经济现实尚未对开放模型的扩展造成普遍影响。
这种以经济为中心的视角,也关系到我对更广泛开源模型生态系统的看法。
8. 要求禁止某些类型开放模型的呼声仍会持续,但在实践中根本无法实施。训练强大的AI模型(接近但未达到前沿水平)的成本,与大规模部署相比其实相对较低。例如,如果美国禁止超过某一算力阈值的开放模型,其他主权实体最终仍会训练并公开发布这类模型,且这些模型会以监管较少的方式进入美国市场。
9. 开源模型影响的“二阶导数”已发生变化,美国将从2027年初开始,在开源模型的采用指标上缓慢收复失地。中国的发展速度放缓乃至趋势反转,需要较长时间。例如Google的Gemma 4取得了显著成功,还有Nvidia的Nemotron和Arcee AI等案例。
10. 随着越来越强大的封闭模型被构建、预览和发布,还会出现更多安全冲击事件,人们会认为最强AI模型的开放权重版本绝不能被允许存在,类似于对Claude Mythos的反应。这些事件可能推动针对开源模型的严格监管。
11. 与此同时,市场对开放模型的长期兴趣会增加,因为主权实体和现有权力结构逐渐意识到,即将到来的超级强大AI工具不能仅掌握在一家或少数几家公司手中。这些实体将把开放模型视为一种不同的治理范式。
12. 新的开放模型融资结构将会出现,因为许多利益相关方意识到,让获取智能的渠道依赖于单一盈利性公司是不可靠的。
13. 本地智能体、OpenClaw以及其他个人智能体,代表着一个迄今为止被严重忽视的开放模型应用市场。它就像暗物质一样普遍存在,对开放与封闭模型的力量对比具有巨大的潜在影响。
有一个词贯穿了这篇文章,我也有意反复使用它——复杂。
正是这种复杂的现实,促使我更深入地思考如何清晰描述开放模型的差距,以及为什么我会同时持有这样的判断:尽管已有明确证据支持近期开放权重模型的能力,但我仍预计美国的封闭实验室会显著扩大领先优势。
--
原文链接:
https://www.interconnects.ai/p/my-bets-on-open-models-mid-2026
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com