
Harness Engineering:为AI Agent打造高效“鞍具”







本文来自微信公众号:陆三金,作者:陆三金,原文标题:《Harness Engineering:给Agent一副好马鞍》
最近,你或许留意到了“Harness Engineering”这个词。
你的第一反应可能是疑惑:这是什么?
Prompt Engineering还在学习中,Context Engineering尚未完全搞懂,怎么又冒出个Harness Engineering。
而且这个词该如何翻译呢?
Harness的原意是马具,这看起来和AI似乎没什么关联。
先别着急,我给你看一张图,你就能明白。
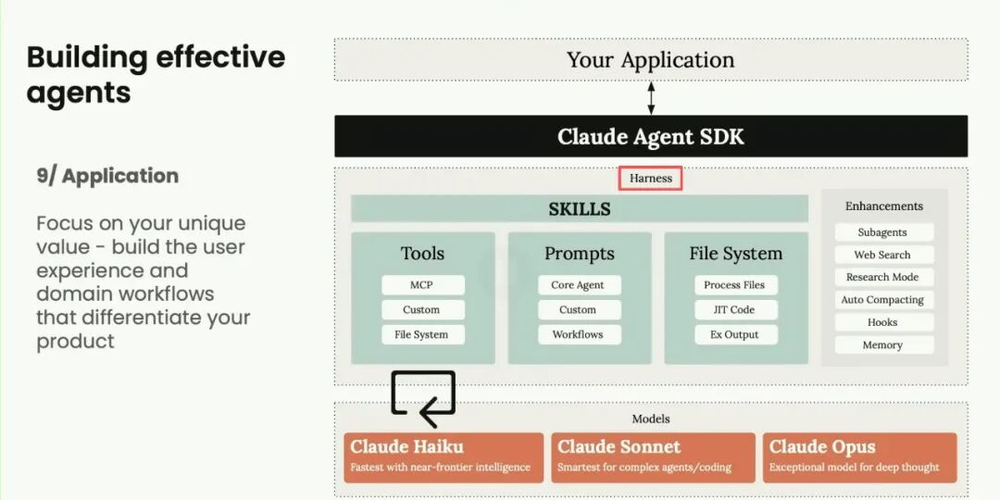
也就是说,你为模型构建的工具、文件、提示词、钩子、记忆系统等一系列元素,组合在一起就被称为Harness。
模型原本像一匹野马,有了这一套Harness,它就能听从你的指令行事。
先来讲一个令人意外的实验结果。2026年2月,LangChain团队对自家的coding agent进行了测试。他们使用同一个模型GPT-5.2-Codex,仅仅修改了外围的“套具”(harness),Terminal Bench 2.0的分数就从52.8大幅提升到66.5,排名也从Top 30直接跃入Top 5。
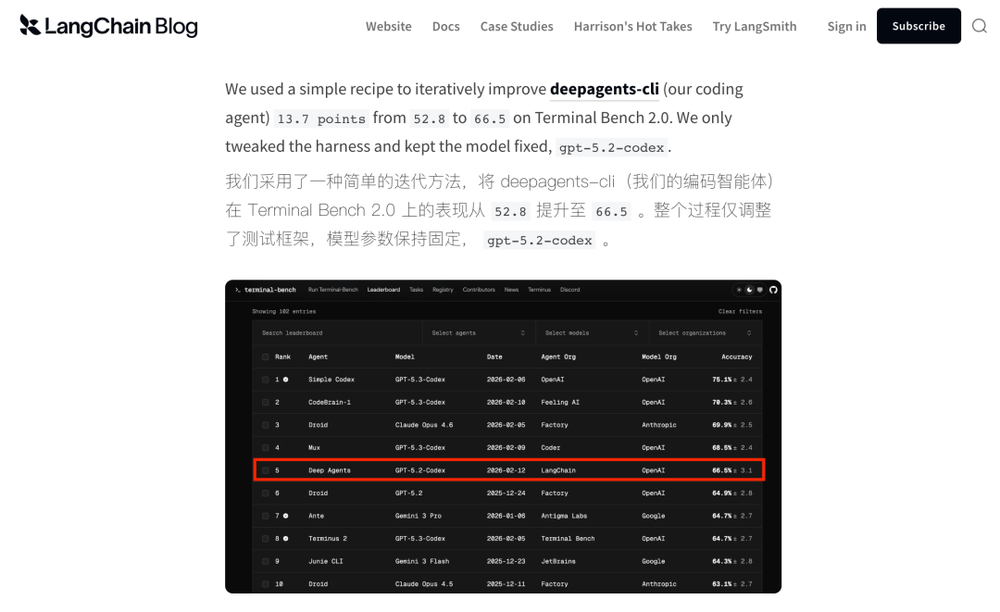
没错,马还是那匹马,换了个马鞍,速度就完全不同了。
这就是Harness Engineering正在展现的力量。
如果把AI agent比作一匹烈马,那么过去几年的技术发展,让骑手们逐渐明白一个道理:驯马术有其极限,而马鞍工艺才是决定能跑多远的关键。
2020年至2023年,是Prompt Engineering的黄金时期。所有人都在研究如何撰写提示词——用什么样的措辞、格式和示例,能让GPT-3或GPT-4给出更优的回答。那时,prompt几乎就是AI应用的全部工程工作。
但到了2024年,情况发生了变化。模型变得越来越强大,应用场景也从单次问答转向多轮对话和长时间任务。Anthropic的研究团队提出了一个新概念:Context Engineering(上下文工程)。他们认为,随着模型能力的提升,构建AI应用的核心问题已从“如何写提示词”转变为“什么样的配置最可能产生期望的行为”。
Context指的是模型采样时获取的所有token,包括系统提示、工具定义、外部数据、消息历史等。Context Engineering就是在这个不断扩展的信息世界中,筛选出最小但信号最强的那部分token。
而Harness Engineering则是Context Engineering的自然延伸。它不仅关注“给模型看什么”,更关注“如何让模型在查看过程中保持专注、自我纠正并持续前进”。OpenAI、Anthropic、LangChain等几乎所有头部企业都在2025年至2026年间加大了对harness的投入。
这就像马术史上的一个转折点:人们发现,与其不断训练马匹的极限速度,不如设计更好的马鞍、缰绳和马蹄铁,让马跑得既快又稳。
说实话,这时我很想听李宏毅讲一堂Harness Engineering课程,他的课程里常有一句经典话术:“本课程中,没有模型被训练”,让人很有安全感。我们不改动模型,但能让模型更听我们的话。
那么,一副好的“harness”到底包含什么呢?
首先是Context Engineering的基础设施。Manus团队在其经典博客《AI代理的上下文工程:构建Manus的经验教训》中分享了一个关键发现:现代AI agent的输入输出token比例可达100:1。也就是说,模型每输出一个token,可能要处理100个输入token。这使得KV缓存(Key-Value Cache)变得至关重要——使用缓存后,Claude Sonnet的输入成本可从3美元/百万token降至0.3美元,相差整整10倍。
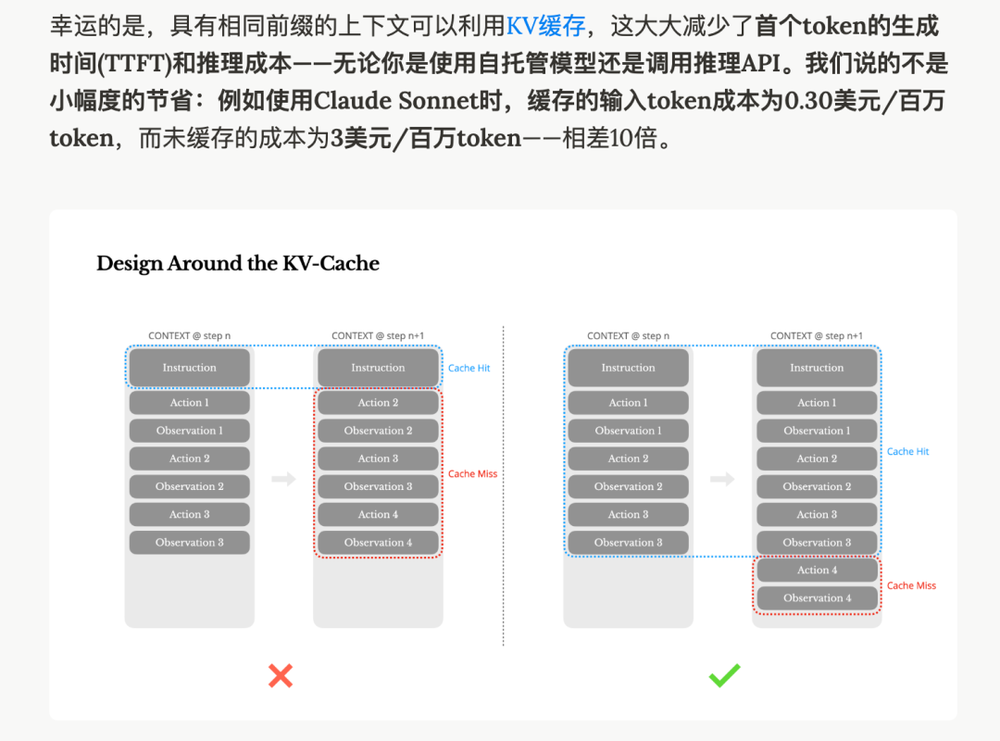
为了最大化缓存命中率,Manus团队总结了三条铁律:保持提示前缀稳定、让上下文只追加不修改、在关键位置明确标记缓存断点。这些看似琐碎的工程细节,决定了代理运行的成本和速度。
其次是Progressive Disclosure(渐进式披露)。这个概念最早源于1990年代Nielsen Norman Group的可用性研究——不要一次性向用户展示所有信息,而是按需逐步呈现。三十年后,这一原则在AI代理中找到了新的应用。
Anthropic的Claude Code提供了一个经典案例。它的Skills功能采用三层架构:
-
•第一层仅加载技能的名称和描述(元数据)
-
•第二层在匹配到用户需求时才加载完整技能内容
-
•第三层则在执行过程中按需引用支持文件。这种方式让代理可以拥有数十个技能,但只为实际使用的那些付费。

这就像去图书馆查资料。笨方法是把整个图书馆搬到桌子上再翻找;聪明的方法是先看书目索引,找到可能相关的书,再一本本取阅。代理也需要这样的“索引系统”。
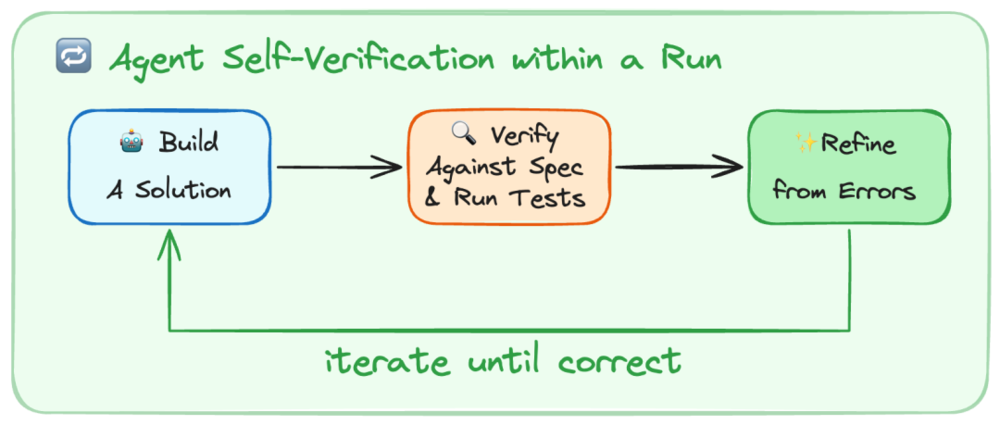
第三是Self-Verification(自我验证)。LangChain团队发现,模型最常见的失败模式是:写完代码后,自己看一遍觉得“不错”就停止了,没有测试、验证,也没有对照需求文档检查。
他们的解决方案是在harness中强制加入验证循环:Plan(规划)→Build(构建)→Verify(验证)→Fix(修复)。更巧妙的是,他们在模型准备退出时插入一个PreCompletionChecklistMiddleware,强制提醒代理“先别急着结束,跑一遍测试看看”。这个简单的钩子,大幅减少了“自以为完成了”的幻觉。
最后是长时间运行的支撑架构。当代理需要工作数小时甚至数天时,单个上下文窗口显然不够。Anthropic的解决方案是双代理架构:Initializer Agent负责搭建环境,包括创建feature list、编写init.sh脚本、进行第一次git提交;Coding Agent则负责在每个会话中做增量推进,留下清晰的进度记录和git commit。
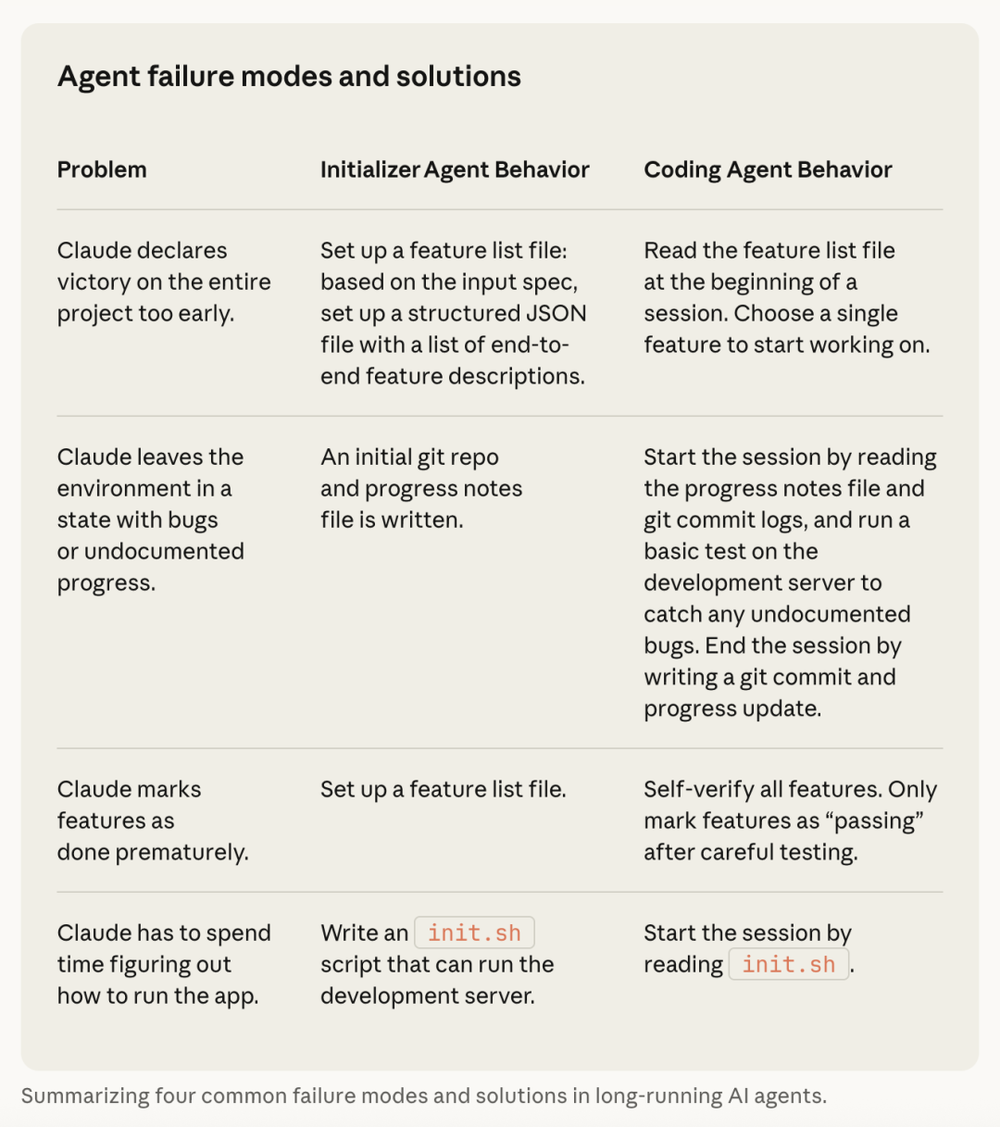
feature list的设计尤为巧妙。Initializer Agent会把用户需求拆解成200多个具体功能点,全部标记为“未完成”。每个Coding Agent会话开始时,都会读取这个列表,选择优先级最高的未完成项来工作。这避免了代理“一次性想做完所有事”或“看了眼代码觉得差不多就宣布胜利”这两种常见的失败模式。
Harness Engineering的兴起,标志着AI工程正进入一个新阶段。
过去,人们把模型当作黑盒魔法,认为只要模型足够强大,所有问题都能迎刃而解。但现在,行业逐渐认识到一个事实:模型的原生智能是“尖刺状的”(spiky)——在某些任务上表现出色,在另一些任务上却会莫名其妙地失败。Harness Engineering的目标,就是打磨这些尖刺,让模型的能力更平滑、更可控、更可靠。
这有点像摄影术的历史。19世纪的摄影师痴迷于镜头工艺,追求更清晰的玻璃和更精准的焦距。但到了20世纪,真正改变摄影的是哈苏的模块化设计、宝丽来的即拍即得以及数码相机的传感器优化。相机还是那个相机,但“如何使用它”的工程学让它走进了千家万户。
AI代理正在经历类似的转变。当GPT-5、Claude 4、Gemini 3这些基础模型趋于成熟时,竞争的焦点正从“谁的模型更强”转向“谁的harness更精巧”。
那么,Harness Engineering会走向何方呢?
我认为有几种可能性。
一种可能是标准化。就像Docker容器统一了应用部署一样,未来或许会出现Harness的标准格式,定义如何组织系统提示、管理工具、实现验证循环以及跨会话保持状态。不同团队开发的代理可以共享harness组件,形成一个生态。
另一种可能是模型化。既然harness的设计如此依赖具体任务和模型特性,为什么不让AI自己来优化harness呢?我们可以想象一个元学习循环:代理执行任务,产生轨迹,另一个“harness优化代理”分析这些轨迹,提出harness改进建议,甚至自动生成新的中间件。这有点像编译器优化——人类编写代码,编译器决定如何翻译成机器指令。
还有一种可能是领域分化。代码生成、科学研究、金融建模、创意设计等不同领域的harness可能会走向完全不同的方向。写代码需要严格的验证循环和测试覆盖,做科研需要文献检索和假设追踪,搞金融需要风险评估和合规检查。没有一套harness能适用于所有场景。
回到开头的比喻。
好马需要好鞍。这不是对马的束缚,而是让它跑得更远的工具。Harness Engineering的本质,是承认AI不是黑盒魔法,而是需要被理解、引导和约束的智能体。
当AI代理从几分钟的对话转向几小时甚至几天的自主工作时,harness的质量将决定一切。它决定了代理会不会在半路迷失方向,会不会自以为完成了任务,会不会在跨会话时忘记之前做过什么。
LangChain的实验证明:同样的模型,换一副“鞍具”,就能从Top 30冲进Top 5。
这个差距,就是Harness Engineering的价值所在。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com