
MiniMax M2.5:龙虾Agent的优选模型,实现永不停机运行






本文来自微信公众号: AGENT橘 ,作者:AGENT橘
2026年春节前夕的这一周,堪称中国AI领域全年成果的集中展示期。
各类成果接连发布,让人应接不暇。
日前,MiniMax推出了M2.5模型,其激活参数与M2.1相同,仅为10B。
M2.1曾是小龙虾工具作者Peter最推崇的开源模型。
M2.5相较于M2.1实现了快速迭代,在编程领域具有代表性的SWE-Bench Verified评测中,M2系列的进步速度在所有模型系列里位居首位,超越了Claude、GPT和Gemini。
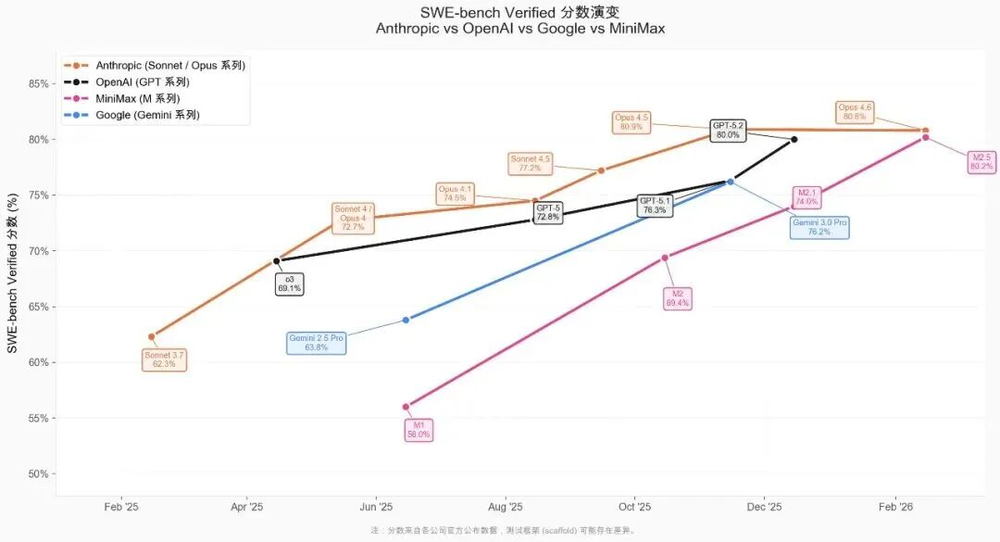
Peter将Opus作为主力模型,而MiniMax则作为备用选择,当Opus的token耗尽时,系统会自动切换到MiniMax继续运行。
并且他不只是通过云端调用模型。他还在自己的两台Mac Studio上运行MiniMax进行本地推理,无需依赖模型厂商的套餐服务,完全实现本地化部署,确保龙虾Agent始终保持在线状态。
能够在本地顺利运行,得益于M2.5在众多旗舰模型中拥有最小的激活参数。
M2.5的激活参数仅为10B。相比之下,GLM-5激活参数为40B,Kimi K2.5约为50B,DeepSeek V3.2约为30B。
尽管该模型的激活参数较小,但其Agent能力却不容小觑。经过Peter及众多小龙虾用户的实际测试,MiniMax是小龙虾工具中表现最佳的开源模型。
参数小带来的优势是连锁性的:推理速度达到100 TPS,几乎是主流旗舰模型的两倍。以这样的速度连续工作一小时,成本仅需1美金;若将速度降至50 TPS,成本则只需0.3美金。
这意味着让一个复杂的Agent持续运行下去,在经济层面变得完全可行。
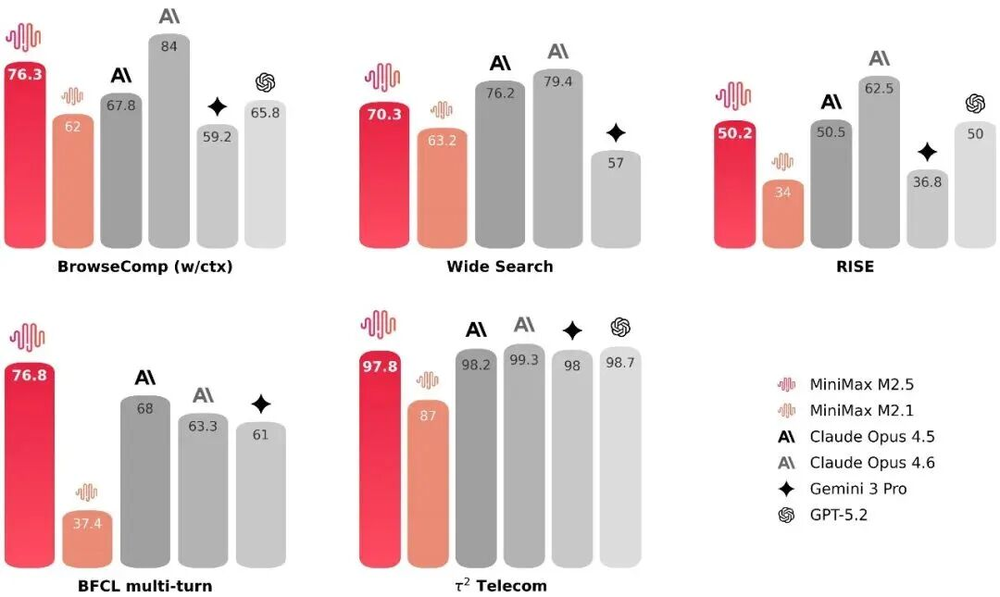
Agent与工具调用能力
M2.5的工具调用能力十分出色,在多项工具调用指标中均处于领先水平。搜索是Agent最常用的工具之一,为此MiniMax专门构建了评测集RISE(Realistic Interactive Search Evaluation),用于测试模型在真实专业任务中的搜索能力。
与M2.1相比,M2.5的提升也很显著。在BrowseComp、Wide Search、RISE等多项任务中,M2.5用更少的搜索轮次就取得了更优的结果,轮次消耗减少了约20%,模型学会了用更短的路径获取答案。
海外开发者Tom Osman借助Clawdbot×MiniMax重构了日常工作流程。他在Telegram、Slack、WhatsApp、iMessage等平台都部署了龙虾Agent,可通过语音或文字随时下达指令。在一个典型的工作日里,他会让龙虾Agent分析网站、调研信息、撰写博客、更新元数据、起草社交帖子、发送邮件等,所有任务并行处理,他只需在不同的Agent之间切换对话即可。
他对MiniMax的评价是:在工具调用方面表现出色且准确性高。他使用的是每月10美金的Coding Plan,用量远未达到上限。
10B的模型尺寸天生适合这类场景。Agent需要全天候不间断运行,模型越小,持续运行的成本就越低,可行性也就越高。龙虾工具作者Peter选择MiniMax作为Opus的备用模型,本质上就是看中了这一点:
当你需要一个Agent持续运行时,10B的模型能让你真正负担得起运行成本。
在我的实际测试中,我让Minimax M2.5执行了一项测试任务:监控每天热度最高的小龙虾工具技能,它完成得非常出色。
编程与泛用性表现
在编程方面,M2.5相较于M2.1有了巨大进步,在SWE-bench Verified评测中达到80.2%,在Multi-SWE-Bench评测中以51.3%的成绩位居全行业第一。
在提升能力的同时,M2.5的推理速度也得到了提升。端到端完成SWE-bench任务的时间从M2.1的31.3分钟缩短至22.8分钟,速度提升了37%,与Opus 4.6的22.9分钟几乎持平。每个任务的token消耗也从3.72M降至3.52M,实现了提速又降耗。
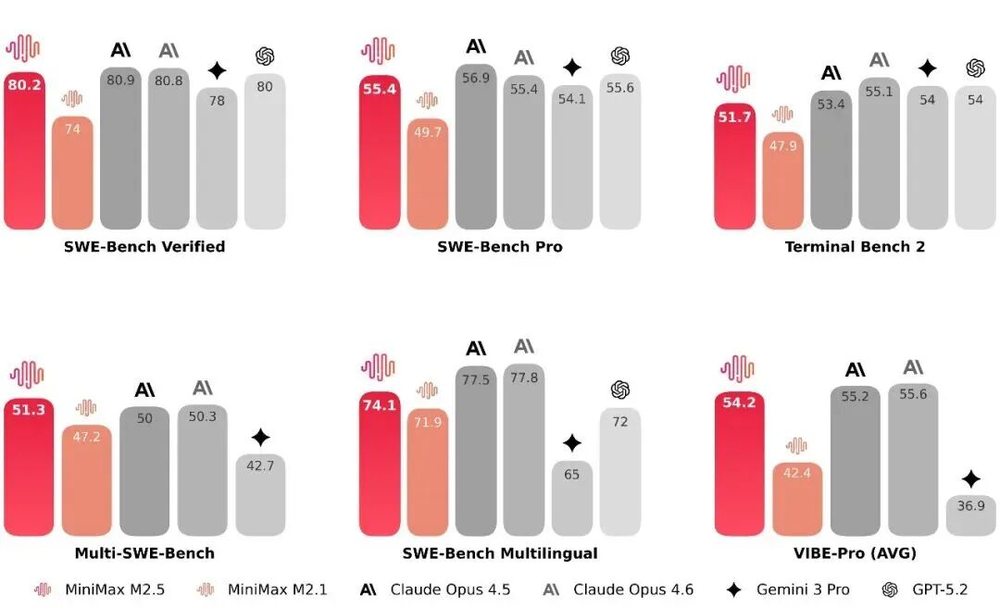
还有一个有趣的点是M2.5在不同编程客户端中的泛用性很强。在Droid上运行SWE-Bench任务时,M2.5的得分是79.7(Opus 4.6为78.9);在OpenCode上的得分是76.1(Opus 4.6为75.9),这使得它不再过度依赖Claude Code这类闭源工具。
提升对OpenCode的支持确实是一件好事。OpenCode是Claude Code的开源替代工具,安装简单,易于上手。
而且在OpenCode中,MiniMax M2.5是限时免费的,无需额外配置。
我曾让它编写一个2026年春运实时监控程序,该程序能每小时自动监控并更新网页内容,最终效果良好。
从工具到同事:Agent的发展方向
MiniMax为M2.5的定位是“真实世界的好同事”。
这是因为Agent是未来软件的使用者,会成为每个团队中新增的成员。
一旦这种转变发生,对模型的要求就会彻底改变。
在自主Agent时代,Agent需要全天候不间断运行,每天进行数百次推理调用。此时,人们关注的是:模型能力是否够用、运行速度是否够快、成本是否能承受。
那么,雇佣一个Agent一年大概需要多少成本呢?
M2.5有两个版本:快速版本在每秒输出100个token的情况下,连续工作一小时仅需1美金;慢速版本在每秒输出50个token的情况下,连续工作一小时仅需0.3美金。
据此计算,雇佣Agent让其全天候工作,每个Agent的月薪仅为200美金。只需花费一万美金,就能拥有四个永不休息的“同事”。
未来几年,算力供给呈线性增长,而需求却呈指数增长,Token资源会越来越稀缺。
在这样的大背景下,自主Agent时代能否实现全天候持续运转至关重要。
因为只有这样,Agent才能走进真实世界,成为人们真正的工作伙伴。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com