
DeepSeek-R2将至?R1一周年:它如何重塑开源AI生态







DeepSeek-R1发布一周年之际,核心算法库惊现MODEL1,是迭代版本还是新一代R2?
2025年1月20日,DeepSeek-R1正式发布,这一里程碑事件让国产大模型首次跻身全球核心舞台,同时开启了大模型的开源新纪元。
就在R1发布一周年的关键节点,深夜的开发者社区突然沸腾——DeepSeek的一个存储库更新中,出现了全新的「model 1」模型引用。
尽管DeepSeek-R1已发布一年,但备受期待的R2尚未露面。而此次曝光的MODEL1,被业内猜测极有可能就是新一代的R2!
在DeepSeek开源项目FlashMLA库的代码片段中,明确引用了「MODEL1」,还同步出现了针对KV缓存的新优化,以及对576B步幅稀疏FP8解码的支持。
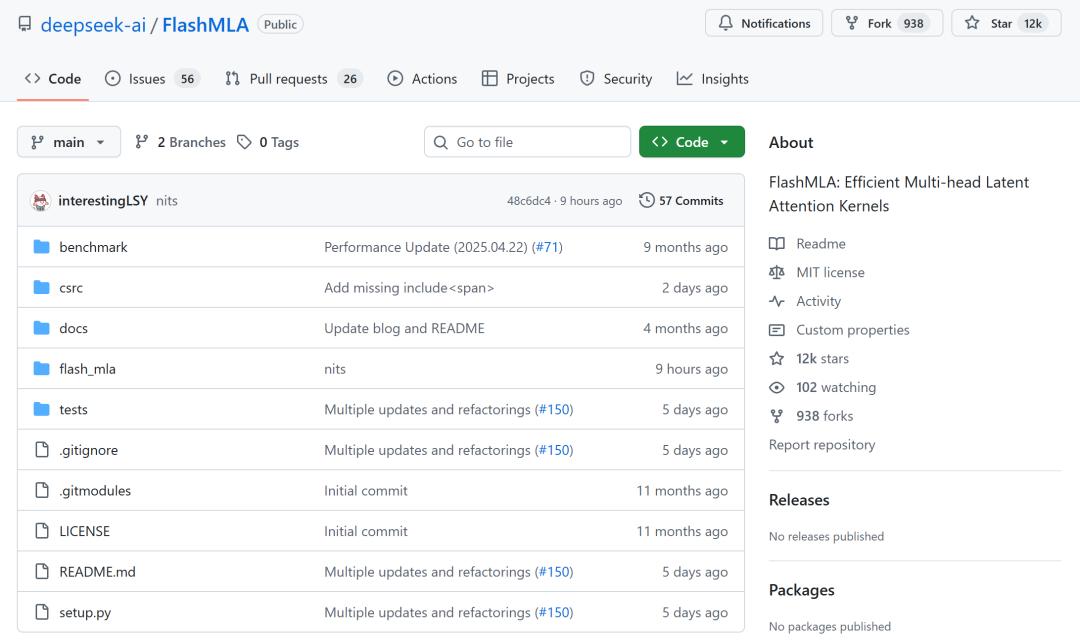
FlashMLA是DeepSeek自研的优化注意力内核库,曾为DeepSeek-V3和DeepSeek-V3.2-Exp模型提供技术支撑。

该项目中,「model 1」的提及次数约达28处,从代码细节来看,这无疑是新模型即将发布的明确信号。
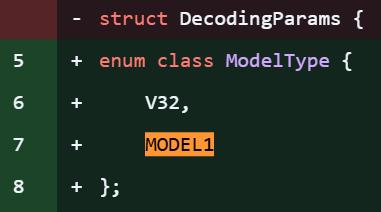
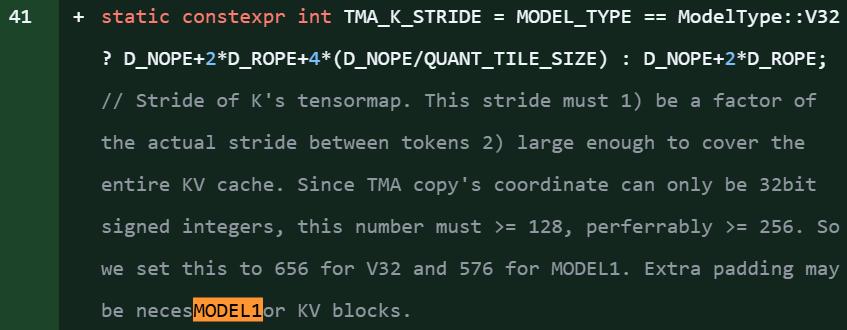






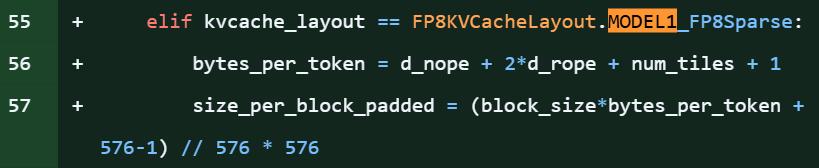


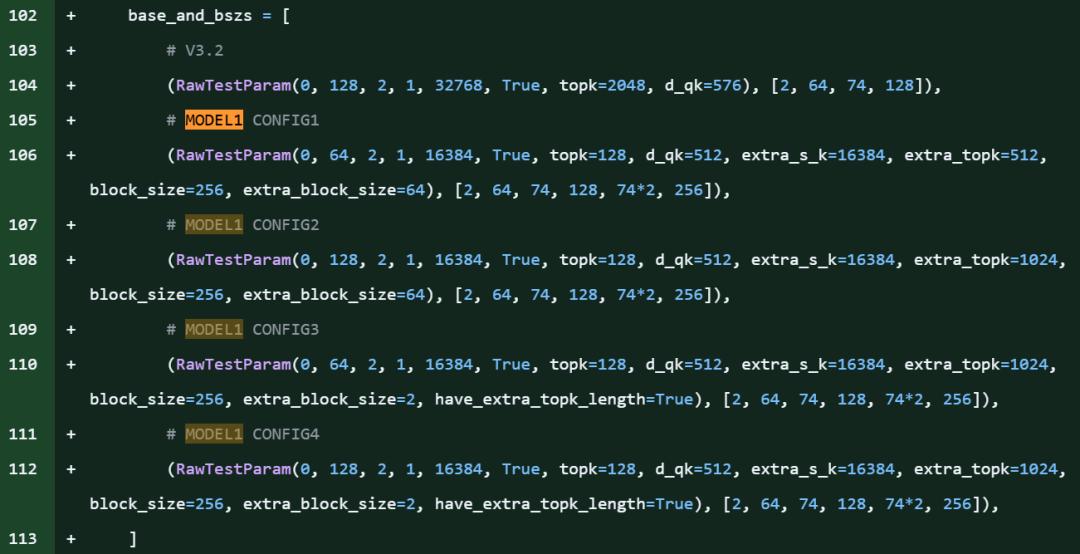
值得注意的是,此次爆料恰好赶上DeepSeek-R1发布一周年(2025年1月20日)。作为开源推理模型,R1曾与OpenAI o1实力相当,并登顶iOS App Store,彻底改变了开源AI社区的格局。即便MODEL1并非R2,其意义也不容小觑,毕竟FlashMLA是DeepSeek的核心注意力优化算法库。
FlashMLA是DeepSeek针对Hopper架构GPU(如H800)优化的MLA(Multi-head Latent Attention)解码内核。推理层代码中出现新模型ID,通常意味着代号为Model1的新模型将继续复用或改进现有的MLA架构,这表明DeepSeek团队正全力推进新模型的推理适配工作,FlashMLA作为核心推理优化工具的地位依然稳固。
此前,DeepSeek确实面临过一些挑战。本月15日,国外媒体报道称,DeepSeek在研发新一代旗舰模型时曾遭遇算力问题,但团队及时调整策略并取得进展,计划在「未来几周内」推出该新模型。
HuggingFace视角:DeepSeek如何改变开源AI
在DeepSeek R1发布一周年之际,HuggingFace发文剖析了DeepSeek对开源AI的变革性影响。
尽管R1并非当时性能最强的模型,但其真正价值在于降低了三大壁垒:
一是技术壁垒。通过公开推理路径和后训练方法,R1将原本封闭在API背后的高级推理能力,转化为可下载、可蒸馏、可微调的工程资源。众多团队无需从头训练大模型,就能获得强大的推理能力,推理开始成为可在不同系统中复用的模块,推动行业重新审视模型能力与计算成本的关系,这在算力受限的中国环境中尤为重要。
二是采用壁垒。R1以MIT许可证发布,简化了使用、修改和再分发流程。原本依赖闭源模型的企业开始直接将R1投入生产,蒸馏、二次训练和领域适应成为常规工程工作,而非特殊项目。随着分发限制的解除,模型迅速融入云平台和工具链,社区讨论焦点也从「哪个模型分数更高」转向「如何部署、降本及集成到实际系统」,R1逐渐从研究成果演变为可复用的工程基础。
三是心理壁垒。当问题从「我们能做这个吗?」转变为「我们如何做好这个?」时,许多企业的决策逻辑发生了改变。对中国AI社区而言,这是获得全球持续关注的难得机遇,对于长期被视为追随者的生态系统来说,意义重大。
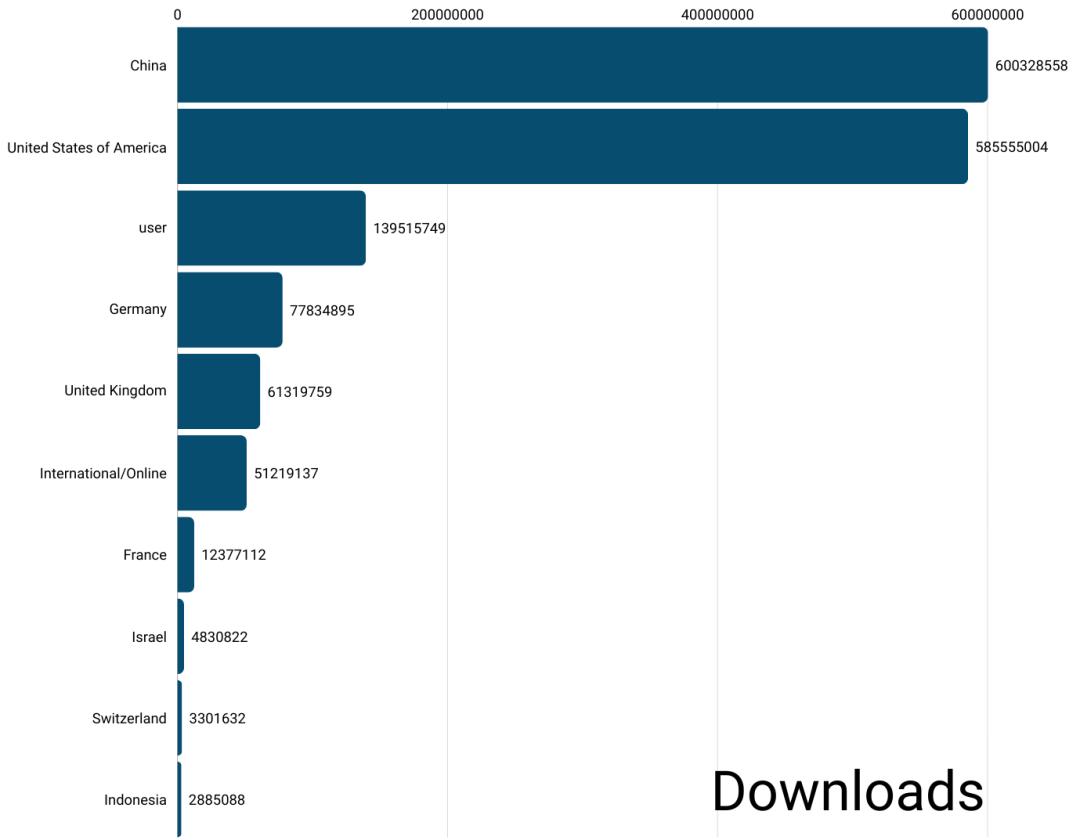
这三大壁垒的降低,让AI生态系统具备了自我复制的能力。
DeepSeek-R1一周年回顾
让我们回到原点,回顾DeepSeek-R1诞生的这一年。在R1出现之前,大模型的进化方向几乎只有参数规模扩大、数据量增加……但模型真的在「思考」吗?这个问题,正是DeepSeek-R1的起点。它并非追求更快的回答速度,而是刻意让模型「慢下来」——慢在推理链条的展开,慢在中间状态的显式表达。
从技术层面看,DeepSeek-R1的关键突破并非单一技巧,而是一整套系统性设计。

推理优先的训练目标:在传统SFT/RLHF体系中,最终答案的「正确性」是唯一目标,而R1引入了更细粒度的训练信号。
高密度推理数据而非高密度知识:R1的训练数据不追求百科全书式的覆盖,而是聚焦于数学与逻辑推导、可验证的复杂任务。对R1而言,过程比答案更重要,这也使其在数学、代码、复杂推理领域实现了「跨尺度跃迁」。
推理过程的「内化」而非复读模板:外界常误解R1只是「更会写CoT(思维链)」,但真正的变化在于,模型并非复读训练中的推理模板,而是在内部形成了稳定的推理状态转移结构,让推理从外挂能力转变为内生能力。
一年之后:R1带来了哪些改变?
首先,它重塑了对「对齐」的理解。R1之后,人们意识到对齐不仅是价值取向的对齐,更是认知过程的对齐。
其次,它拓展了开源模型的想象空间。R1证明,在推理维度上,开源模型并非追随者,而是可以成为范式定义者,极大激发了社区对「Reasoning LLM(推理大模型)」的探索热情。
第三,它改变了工程师与模型的协作方式。当模型开始「展示思路」,人类的角色就从单纯的提问者转变为合作者。
回到当下,R1的探索仍未结束。一周年并非终点,我们清楚地知道,推理能力仍有明显上限,长链路思考的成本依然高昂。但正如一年前选择研发R1时那样,真正重要的不是已解决的问题,而是方向是否正确。DeepSeek-R1的故事还在继续,这一年,只是序章。
参考资料:
https://huggingface.co/blog/huggingface/one-year-since-the-deepseek-moment%20
https://x.com/testingcatalog/status/2013588515271962678%20
https://x.com/nopainkiller/status/2013522059662614653
本文来自微信公众号“新智元”,作者:新智元,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com