
AI“精算时代”开启,英伟达引领小型模型变革







在AI领域,小型模型正迎来属于它们的高光时刻。从能装入智能手表的新AI视觉模型,到可在谷歌智能手机上运行的模型,小型化、高效化已成为显著趋势。如今,英伟达也加入这一浪潮,带来全新的小语言模型(SLM)——Nemotron - Nano - 9B - v2。这款模型不仅在选定基准测试中达到同类最高性能,还具备让用户自由开启和关闭AI “推理” 的独特能力,为AI应用开辟了新的想象空间。
“小” 模型从边缘玩具到生产主力
过去三个月,AI圈的 “迷你军团” 接连发力。MIT子公司Liquid AI推出的视觉模型小巧到能装入智能手表,提升了可穿戴设备的智能体验;谷歌将Gemini - Nano塞进Pixel 8手机,让移动端AI能力实现质的飞跃;英伟达带着90亿参数的Nemotron - Nano - 9B - v2登场,将其部署在单张A10 GPU上,刷新了人们对小型模型的认知。
这并非技术炫技,而是对成本、效率与可控性的精准平衡。英伟达AI模型后训练主管Oleksii Kuchiaev表示,将参数从120亿精简到90亿是为了适配企业部署中常见的A10显卡。这意味着参数大小不再是衡量模型优劣的关键,投资回报率(ROI)才是重要指标。
把思维链条做成可计费功能
传统大模型的 “黑盒思维” 是企业使用的痛点,长时间推理会使token账单失控。而Nemotron - Nano - 9B - v2给出了解决办法:在prompt中加入/think,模型会启用内部思维链逐步推导;加入/no_think,则直接输出答案;系统级的max_think_tokens功能能为思维链设定预算,精准控制成本。
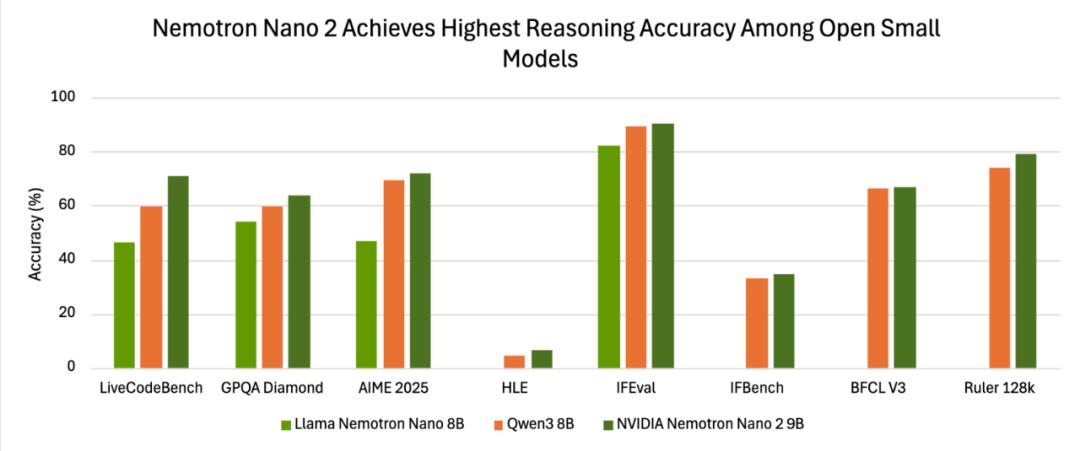
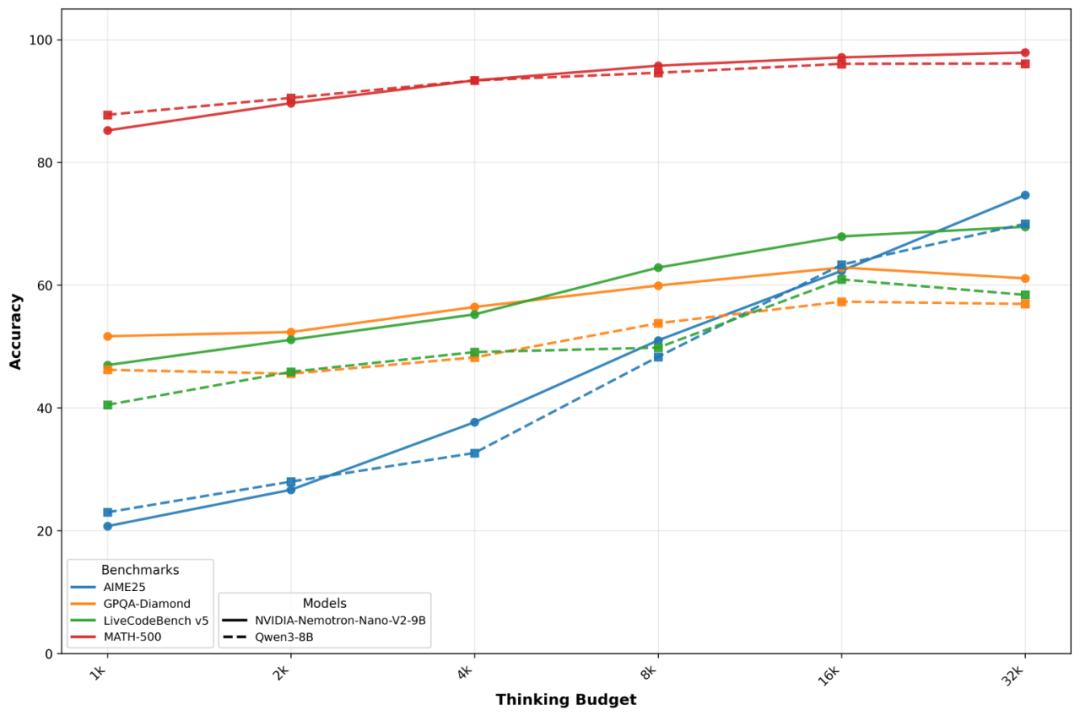
现场实测(官方报告)数据更能说明问题:
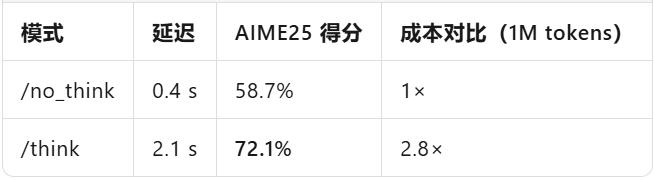
把「推理」从默认能力变成可选项,企业可以像买云硬盘一样按思考深度付费。
Transformer的「省油」补丁
9B模型能在长上下文里打平70B,原因在于Mamba - Transformer混合架构。用Mamba状态空间层替换70%的注意力层,显存占用降低40%;序列长度与显存呈线性关系,而非平方爆炸;128k token实测吞吐量比同尺寸纯Transformer高2.3倍。Mamba不是取代Transformer,而是将其改造成省油的混动引擎。
商业核弹:宽松许可证 + 零门槛商用
英伟达在许可协议上做到了 “三不要”:不要钱,无版税、无收入分成;不要谈判,直接下载即可商用;不要法务焦虑,仅要求遵守可信AI护栏和出口合规。对比OpenAI的分级许可、Anthropic的使用上限,Nemotron - Nano - 9B - v2几乎成了 “开源界的AWS EC2”,极大降低了企业使用门槛。
场景切片:谁最先受益?
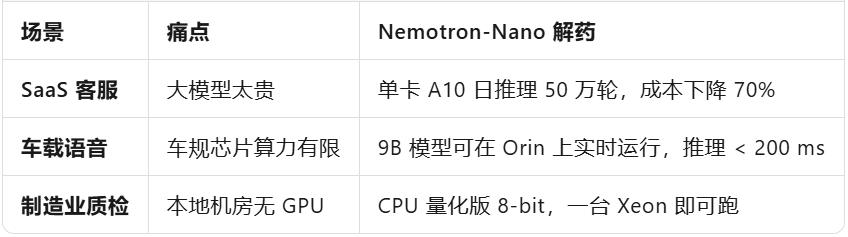
任何边缘/私有化场景,都多了一张「足够聪明又付得起」的牌。
AI的「精算时代」正式开幕
过去四年,我们见证了参数 × 算力 = 性能的规律。如今,Nemotron - Nano - 9B - v2用90亿参数告诉我们:架构 × 控制 × 许可证 = 可持续的AI经济。当小型模型不断发展,“小” 不再是技术妥协,而是精打细算后的最优解。
未来,创业者们或许会自信宣称:“我们用1/10的算力,做出了90%的效果,并且还能赚钱。” 这标志着,AI的 “精算时代” 已正式拉开帷幕。
本文来自微信公众号“山自”,作者:Rayking629,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com