
英伟达新GPU再次被王炸,也要靠蹭DeepSeek卖卡







黄仁勋穿着皮衣,GTC 2025年意气风发。
尽管最近英伟达的股票跌得很厉害,甚至达到了10年来的最低点,但是这并不影响老黄,对最新的GPU充满信心。
到2月初,DeepSeek的发布在AI领域掀起了一股巨浪。目前,一个中国团队的产品只使用了少量的低端GPU(主要是A100)来蒸馏高端GPU(以H100为代表)。
高档GPU并非刚需,谁还成吨地购买你老黄的Hopper?、Blackwell 核弹?在过去,AI行业被视为金科玉律。Scaling Law"(规模法则),“模型参数、数据、训练费用越多越好”观念也受到了严重的冲击。
近几年谷歌,Meta、微软等互联网厂商为了保持规模,成吨采购H100芯片,只是为了以计算率分胜负,决定生死。现在,没有必要使用如此可怕的规模,大模型可以与之相媲美。 OpenAI o1的性能。
有一段时间,声称DeepSeek可以让英伟达走到尽头,尤其是海外社交媒体平台,酒精发展最快,传播最激烈。X网友甚至直言“英伟达的一切都会开始分裂”。在此期间,英伟达的股票每天下跌13%。、17%已经成为常态。
然而,还有一种声音说,从长远来看,DeepSeek的成功反而有利于英伟达。
DeepSeek揭示了一个可以通过“蒸馏目前的超大模型”来训练性能优异的大模型,但它只是不需要使用H100芯片等性能怪物,而不是完全不依赖计算卡。A100计算卡也是英伟达家的产品。
随着玩家门槛的降低,自然会有越来越多的玩家进入市场。从行业总量来看,对计算能力的需求还是会增加。英伟达也是世界上最大的卡贩子,总是卖出更多的计算卡。
除此之外,为了蒸馏目前的超大型模型,还需要一个性能优异的超大型模型。毕竟还是需要H100这样的计算卡集群来训练超大型模型,这似乎是一个“先有鸡还是有蛋”的问题。
只能说两种声音都有道理,但大家最想知道的还是老黄个人的声音。
这次GTC 2025年,我们终于等到老黄亲自回应。
或者GPU霸主
按照惯例,我们先来回顾一下这次“科技盛会”,光是门票就开了一万美元。
简而言之,英伟达主要发布。四个芯片架构、两台AI计算机、一个AI训练底层软件并且展示了具身机器人的相关进展,其它内容就不赘述了。
·将于2025年下半年发布的4个AI芯片架构Blackwell Ultra、公布于2026年下半年。Vera Rubin、2027年下半年公布Vera Rubin Ultra,和2028年的Feynman。
基于Blackwelllll的全新超级芯片产品 GB300Ultra架构 NVL72芯片是GB200的接班人,前代最强芯片,推理是GB200。 NVL72的1.5倍,增幅不算太大,甚至GB300在会上的直接对比目标还是2年前的H100。

根据行业的反应,大多数人对GB300并不太买账,它并没有上一代GB200那种“问世”的惊喜感,要说最大的升级点,也许是HBMe内存升级到了288GB,也就是说,苹果今年发布的新机是2TB版的iPhone。 16 Pro Max"这是味道。
亮点是英伟达未来的芯片架构规划,下一代非常芯片Rubin 与GB300相比,NVL144 NVL72 强度为3.3倍;下一代Rubin Ultra GB300是NVL576性能。 NVL72的14倍,从画饼给出的性能来看,未来英伟达仍将掌握GPU算率王座的可能性很大。

·两台全新的AI计算机,分别配备了GB10 Grace 非常芯片的BlackwellDGX Spark,每一秒都可以提供高达 1000 万亿次 AI 配备GB300计算; Grace Blackwell UltraDGX Station,能提供高达20000秒的每秒能提供。 万亿次 AI 计算。当前DGX Spark已开始预购,价格为3000美元。
·开源软件NVIDIA Dyamo,英伟达表示,NVIDIAIAI工厂(数据中心)的操作系统可以简单理解为AI工厂(数据中心)。 Dynamo用于Blackwell中的推理,可以使DeepSeek-R1的吞吐量增加30倍。
·机器人的技术储备包括机器人通用基础模型Isaac GR00T N1、一个配置了GR00T。 N1模型机器人:Blue,还有Google Mind、最新的迪士尼合作成果。

从发布的产品来看,英伟达仍然是GPU领域的霸主,甚至领先地位已经开始扩大到AI。他们不仅每年更新产品的技术路线图,而且在未来三年内,产品可以被称为“非常大的蛋糕”,与AI相关的软件建设也在快速推进。NVIDIA Dyamo很可能是未来数据中心的必需品。
英伟达似乎也有解决DeepSeek冲击问题的办法。
进入“token时代”
最后,黄仁勋对DeepSeek诞生以来对企业的影响做出了积极的回应。
首先,他把DeepSeek全身吹了一遍,说DeepSeek R1模型是“卓越创新”和“国际开源推理模式”,并且他平静地说,不明白为什么每个人都把DeepSeek当作英伟达的末日。
关于Scaling,由DeepSeek引起的。 关于Law碰墙的讨论,老黄在会上给出了自己的理解。
第一,他在会议上对Scaling Law进行了迭代更新:
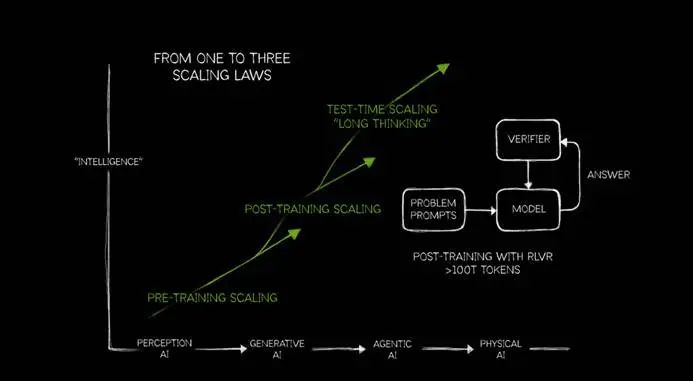
现在他把Scaling 细化为LawPRE-TRAINING SCALING、POST-TRAINING SCALING、TEST-TIME SCALING三部分。老黄的意思是,随着AI进入各个阶段,对Scaling的需求也在不断增加。
在此,老黄认为AI的发展分为四个阶段:感知人工智能(Perception AI)、生成人工智能(Generative AI)、代表人工智能(Agentic AI)以及未来物理 AI(Physical AI)。而且现在我们正在这里代表人工智能阶段。
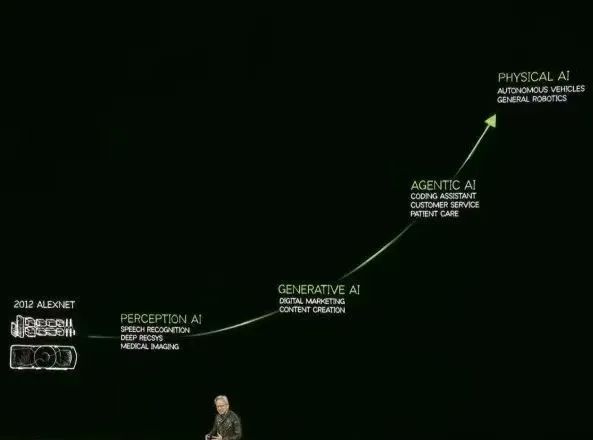
目前由于推理模型、AI代理的爆发,实际上更需要Scaling,更需要算率。
这背后的关键是token。
以推理模型为例。当推理模型时,token的消耗量飙升。如果我们使用老黄,我们不仅需要提高token的吞吐量十倍,还需要过去十倍的算率来提高token的输出率。最后,所需的计算率是以前的100倍。
从技术上讲,这不是没有道理的。与ChatGPT等传统生成模型相比,我们观察到它没有列出推理步骤。输入问题 → 提供答案,没有中间商差价,答案呈现的是最终消耗的token数量。
而且有思维链的推理模型,比如大家都知道的DeepSeek R1,会有一系列的推理过程,有时推理过程的字数可能比答案还多。
R1模型之所以能实现推理,是因为它会把输出token带回上级重新思考和推理,就像描述大师老黄所说的“每一个token都会消极悲观”,持续的怀疑-论证,构成了推理的过程。但是这样也会消耗更多的计算能力和token,推理模型比传统生成模型消耗更多的token不是两倍,而是20倍。
所以我们在使用推理模型的时候,要在前台呈现一系列的探索和推理过程,不仅仅是因为用户可以从大模型推理过程中介入调整答案,更是因为它不是免费的,不是免费的,而是在消耗真金白银,花钱的区域一定要让你看到。
而且市场上的推理模式越来越多,越来越多的传统模式也开始加入推理过程,比如谷歌的Gemini,最后token的消费会呈指数级增长。
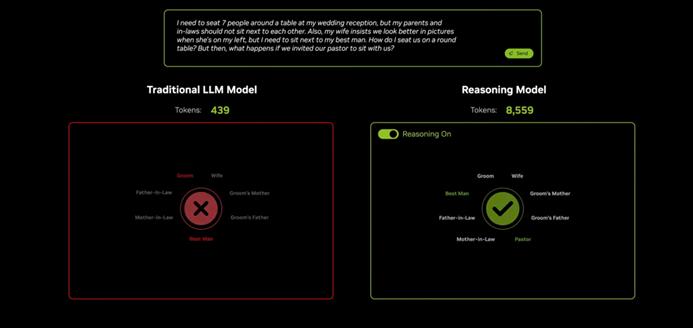
那就是老黄坚信Scaling。 Law没有失败的信心。会上,老黄使用了Llamama传统模型。 3.3 Seek70B和Deep R1 对比671B,统一回答一个复杂的问题。最终,前者消耗了400多个token,但是结果无法使用,而后者的结果是完美的,但是完全消耗了8559个token。
或许从蒸馏大模型的思路中节省的算率,又会消耗到推理的过程中,说不定这就是AI算率中的能量守恒。
DeepSeek让英伟达GPU卖得更好。
除黄仁勋的热情论证外,一个事实是,英伟达的GPU在这个高token消耗时代确实卖得更多。
彭博社报道,OpenAI 预计在「星际之门」在第一个计划中,建立一个能容纳40万英伟达的计划。 AI 芯片数据中心综合体。如果全部装满,这将是全球最大的AI算率集群之一。

还有马斯克,他对算率赞不绝口,旗下的马斯克 xAI 已经和戴尔达成了 50 用于在孟菲斯建造超级计算机的亿美元协议 AI 服务器;Meta还宣布计划拥有相当于 600,000 块英伟达 H100 芯片算率。
国内也有阿里、小米、腾讯等企业,主要目的是部署大量计算能力。毫无疑问,这背后的显卡供应商主要来自英伟达。推理模式铺开后,大企业对计算卡、计算能力的热情丝毫没有减弱,至少大企业仍然相信未来是计算能力的时代。
个人当地部署领域,DeepSeek R1并没有真正减轻个人用户的计算负担。
2月中旬,DeepSeek在全网掀起了一阵本地部署。 R1蒸馏模型的热潮,但是从个人经验来看,希望获得更好的模型性能,对于计算机配置,即计算能力的要求一点也不低。
以RTX 4080 例如,16GB显卡拥有9728个CUDA核心,16GB 显存带宽为736XGDDR6X GB/s,已被认为是显卡中的高档。
但是DeepSeek使用它在当地部署14B。 在R1蒸馏模型中,大多数推理速度只有20-30。 tokens/s,通常要等10分钟以上才能分析深层问题。
若进一步使用它来安排32B蒸馏模型,推理速度将进一步降至5-15 tokens/s,需要等30分钟以上才能得到同样的答案。
这种效率显然是不够的。若要提高推理速度,有两种方法:
选择较小的参数蒸馏模型部署,但是推理的准确性,答案的稳定性会明显下降;
选择配置较高的硬件,例如RTX 使用5090部署32B蒸馏模型的5080/5090,推理速度也可达50-60。 tokens/s,效率明显提高,但又让老黄卖卡计划通过。
或许大部分人的计算条件,本地部署的大模型还不如直接打开腾讯元宝。
所以,从DeepSeek R1引申出的“蒸馏模型节约训练计算率”已被“推理模型消耗计算率”抵消,它给了英伟达一个全新的机会,可以说,DeepSeek的出现为英伟达关上了一扇门,又打开了一扇窗。
最后,我们不得不承认,从长远来看,计算能力的需求将会增加,这仍然有利于英伟达。尽管今年的Blackwellll。 Ultra挤牙膏,但是未来几年的芯片结构会大大提高。当各大厂商的计算率紧张时,老黄的核弹还是有机会大显身手的。
卖token焦虑?
纵观GTC 只要涉及到AI,2025、GPU、在计算能力的部分,老黄离不开token,甚至有好事的媒体专门统计了他在会上提到的“token“次数,还怪幽默。
新Scaling 在Law时代,token似乎成了英伟达的救命稻草。虽然从逻辑上看老黄的观点是有道理的,但重复一个逻辑是如此频繁,就像我们在文章中连续写100遍一样。token”,有些人会觉得,英伟达有点声嘶力竭。
自农历新年以来,英伟达的市值已经下降了近30%。这次发布会的黄仁勋不会像技术大师那样,也不会像“世界上最聪明的科学家”、CEO是世界上最好的公司,而且像一个啰嗦的金牌销售,通过卖token焦虑的方式,让大家坚信英伟达仍然掌握着未来。。
但投资者的信心并不来自于推销和布道,而是来自于商品。事实是,今年下半年出版的GB300真的没有太多亮点,画的蛋糕也很远。反映在股价上,英伟达的股价在发布会结束后仍下跌了3.4%。
事实上,价值3000美元的DGXX更让我哭笑不得。 Spark,按照官方网站披露的信息,该产品的128GB内存,带宽仅为273GB/s。

尽管老黄将其定义为“可用于本地部署”的AI计算机,但是这个性能真的不能恭维。别说满血版671B的DeepSeek R1,跑大多数32B模型也只能实现2-5。 tokens/s输出效率。使用它来运行传统模型应该还不错,但是推理模型估计很难。
或许它的存在价值停留在“让每个人都能买到更强的DGXX Station”上而已。只是如果你一直在卖token焦虑,最好能拿出更多能够解决token焦虑的产品。
英伟达现在缺少的不是技术和产品。在GPU领域骑行,第二名看不到尾灯;真正缺少的是对消费者的真诚。
本文来自微信微信官方账号“蓝字计划”,作者:Hayward,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com