
直接干穿美国科技股,DeepSeek这个国产模型为什么?








马上就要过年了,差评君这几天还在忙着办年货,结果回家刚拿起手机,就被人拿起手机, AI 刷屏了。
还记得前几个星期跟六代机前后脚。 DeepSeek 没有?他家的那个 V3 模型震惊硅谷还没多久,现在又整出了一份绝世狠活。
假设最后一次 V3 模型,就是让硅谷对中国。 AI 侧目的话,这次就直接被掀桌子了,它们发布了一个名字 DeepSeek-R1 大模型,完全可以比得上 OpenAI-o1 那一种,结果出现后引起的反响比上次还要大!
Meta 创始人看完之后,大呼改变历史,不惜赞美之词,还在后面的推文里跟着。 DeepSeek 黑子对喷。

参投过 OpenAI 、 Databricks 、 Character.AI 著名企业风险投资大佬马克 · 安德森也对 DeepSeek-R1 一句猛夸,说它最令人惊叹,最令人记忆深刻,是对世界的一份深刻礼物。
而其他 AI 爱好者和网友也纷纷选择用脚投票,一个月几百块钱。 ChatGPT 拜拜你内心!
这是哥们免费下载的 DeepSeek !
接着就像以前小红书爆红一样, DeepSeek 应用商店的排名迅速上升,现在已成为 APPSTORE 软件排名第一。

不但美国人对友邦感到惊讶, DeepSeek 现在国内更是红极一时。
最近几天微博上的热搜和它有关,每天都要挂几个。
甚至不少 AI 业内圈外人深受感动,如做黑神话的冯邈,也在微博上感慨良多,说这是 " 国家运输水平的科研成果 " 。
即使是差评编辑部的主编老师,经历过之后也直呼好用,可以用来做培训。

其它网友实际体验过后,也纷纷表示这东西的确很牛逼。
别说别的,就用跟着 OpenAI-o1 相比之下,有网友让这两个人各自写一个脚本,要用。 python 在旋转的三角形中画一个红球跳跃,结果左侧 OpenAI 把它弄出来,右边的 DeepSeek 反而表现得相当顺利。
一句话, o1 能做到的它可以做, o1 如果做不到,也可以做。这简直就是踢馆行为,一脚踢国产产品。 AI 牌匾只能屈居人后。
但是除了扬眉吐气之外,估计很多差友也和差评君一样有些怀疑,毕竟, DeepSeek 这样一个以前从未听说过的小厂,怎么会突然变得支棱起来,名扬世界?

在暗涌访谈 DeepSeek 在创始人梁文锋的报道中,我们仍然发现了一些原因,这是一家非常重视创新的企业。
使用之前在行业内大放异彩的东西。 V2 、 V3 就模型而言,这里有一个非常重要的双头注意机制,而这项技术最初只来自团队中一个年轻开发者的想法,然后我们一起研究这个计划,最终得到它。
而且这一创新驱动的技术突破在这支队伍中并不少见。

然而,与单一技术点的突破相比,这次 R1 牛的地方在于路径创新,甚至可以改变整体。 AI 技术路线领域。
这么说吧,在传统的大模型训练中,非常注重数据微调的标注。( SFT ),也就是说,让大模型先根据人类标注的正确答案来学习,学会说实话;如果你想要一个更强大的模型,你必须重新开始。 SFT 在此基础上增加一些强化学习。( RL ),更好地理解大模型。
也就是说,传统大厂从事AI 就像应试教育一样:先给大量的数据标注灌输式教学。( SFT ),再次加强学习( RL )进行考前突击。这就是训练的结果 GPT-4o 这种 " 别人家孩子 " ——解决问题的步骤整齐规范,但总觉得少了一点气场。
而且更加可怕的是,这种训练需要大量的资源,大量的时间和资金都要花在数据标记和微调上。
但 DeepSeek 牛的地方在于,他们这种推理模式的关键在于加强学习,完成后用一个叫做“强化学习” GRPO 对模型进行回答和评分的算法,然后继续优化。在这些步骤中, SFT 没有任何用处。
这样就相当于把孩子扔进了鱿鱼游戏这样的大逃亡剧本,强迫模型自己去琢磨最好的路径,如果不能解决问题就发。
因此,在这种高强度淬炼中,只有一种花费。 600 一万美元,两个月锻造出来的宗派天才,出场就达到了世家大族花费数亿资金练习几年的水平。
实际上,早在几个星期前, DeepSeek 这就是团队研究者的想法,在原来的那个 V3 在此基础上,完全依靠强化学习来做出一个。 R1-Zero 版本
前几日 DeepSeek 发布的技术报告中提到, Zero 在训练中,版本的进化速度非常明显,很快就能跟上。 OpenAI-o1 掰断手腕,在一些测试项目中,而且还高于 o1 。
除推理能力明显提高外,Zero 甚至在推理中表现出主动复盘反思纠错的行为。,它突然意识到自己在复习过程中犯了一个错误,然后开始回头计算。
在官方备注中,大模型突然在这里使用了一种拟人化的说法。 aha moment ( 领悟时刻 ),不仅 Zero " 顿悟了 " 现在,科研人员看到这个时候还是 " 顿悟了 " 。
当其他 AI 还在背公式的时候, Zero 我已经学会了在草稿纸上画辅助线,这完全可以算是 AI 里程碑推理事件:
没有事先的数据标注,没有微调,只有通过模型加强学习,模型才能显示出这种程度的推理能力。
这个相当于给全世界做了 AI 人们上了一节课,原来还能这样玩。

虽然推理能力已被证明, Zero 缺点也很明显。
纯粹的强化学习养出来的 AI ,生活是一个钢铁直男,模型导出的可读性很差,或者说说话不符合人类的预期。
这就像一个偏科天才,数学题很完美,但是表达能力令人担忧,这让它写了一篇短文,每分钟都给你做。《 三体 》 ETO 即视感。
这个时候到了 SFT 是时候表演了, DeepSeek 团队在 Zero 在强大而有力的推理基础上,也增加了一部分 SFT 训练可以让模型说实话,所以, DeepSeek-R1 堂堂诞生!
神奇的是,在 Zero 在此基础上经过这样一套 " 文理双修 " 骚操作后,优化后的骚操作。 R1 推理能力和进一步提高,还是看测试数据:
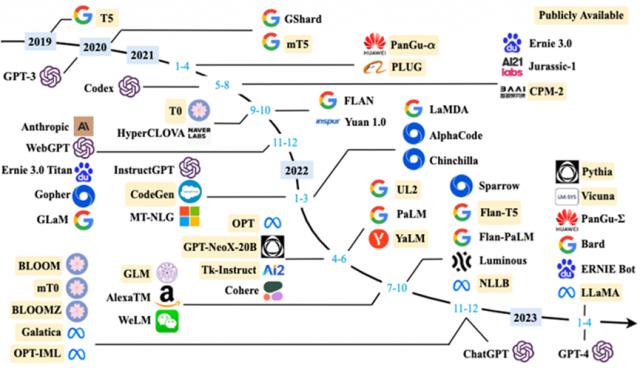
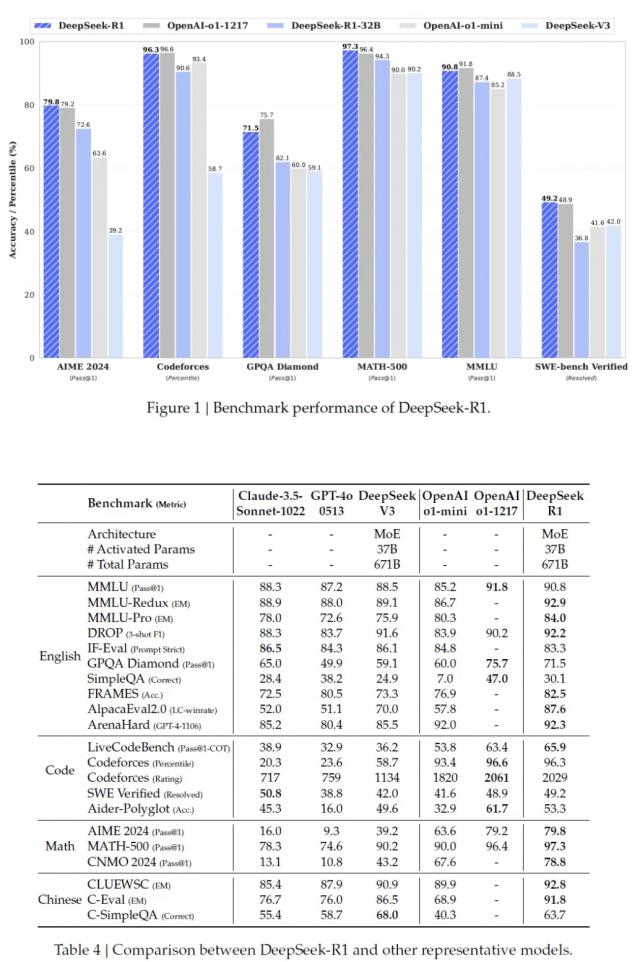
STEM 数学题目在评价中的准确率已经达到 97.3% ,比 OpenAI-o1 更高一点,遥遥领先属于;在代码测试中; R1 也高达 65.9% ,远超 Claude-3.5-Sonnet 的 38.9% 和 GPT-4o 的 32.9% ;
MMLU 和 AlpacaEval 2.0 综合性知识测试, R1 分别达到胜率 90.8% 和 87.6% ,压力一群闭源大模型。
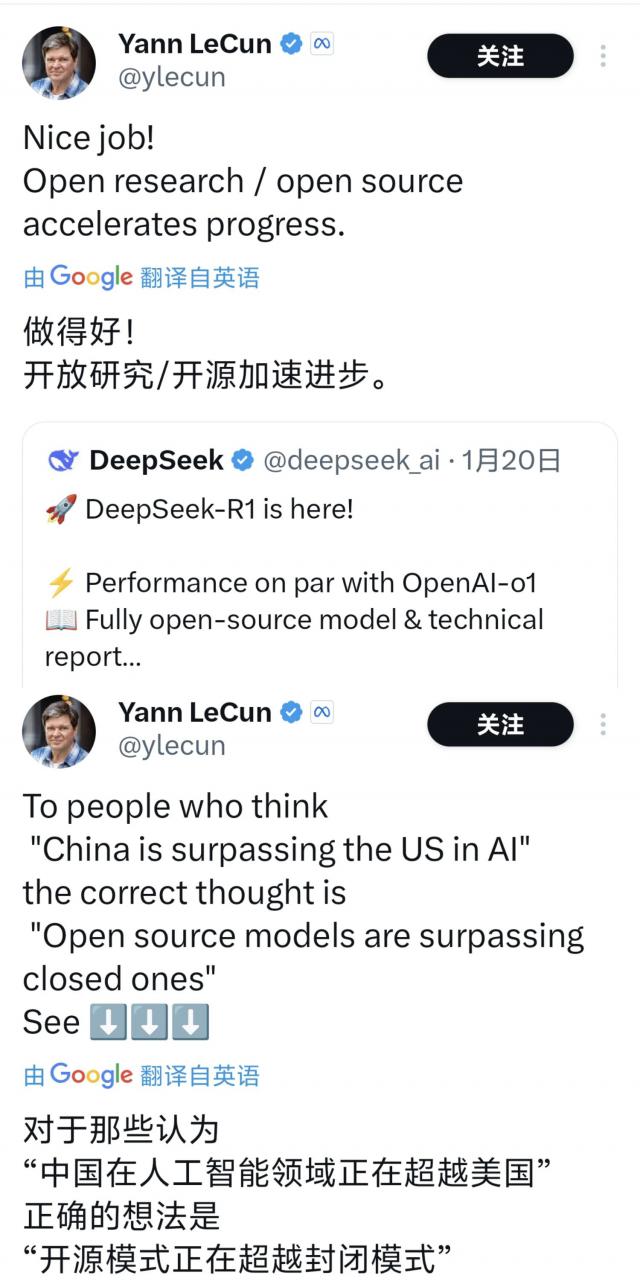
用 Yann Lecun 换句话说,这波是开源的伟大胜利!现在谁敢说开源就是落后啊。( 战术后仰 )
不过要说 R1 成功也只是证明了开源模型的实力, R1 最后一部分技术报告是最离谱的。。
他们提到了这一部分, R1 的 SFT 数据蒸馏,喂给其它小模型 SFT ,会给其它开源模型带来一波很大的强化。
换言之,只要把它放在一边 R1 的 " 学习笔记 " 制作辅助材料,打包喂给其他小模型。 AI ,让他们也随之抄作业,学习这些好学生的作业思路,结果竟可以提高小模型的水平!
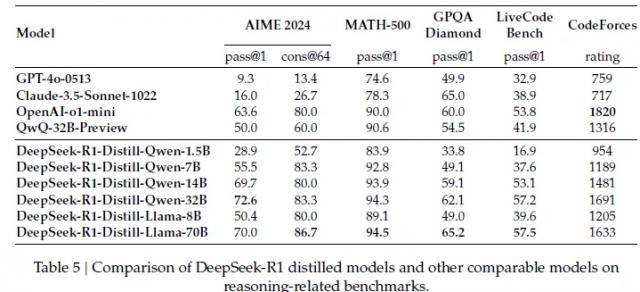
比如说把 R1 错题集发给 Qwen 和 Llama 结构,结果复制作业。 Qwen-7B 模型,在 AIME 测试通过率已经达到 55.5% ,已赶上参数量大,快速赶上。 5 倍的 QwQ-32B-Preview ( 50.0% );
像 70B 看完学霸笔记后,参数版也和打通任督二脉一样, GPQA Diamond ( 65.2% )、 LiveCodeBench ( 57.5% )在任务中甚至关闭都可以跟随闭源模型。 o1-mini 掰掰手腕。
也就是说, DeepSeek 这个波浪不仅得到了验证 " 小模型 好老师 " 技术路线,更让个人开发者也可以调试出匹敌 GPT-4 的 AI 。
小模型只需要按照优秀的大模型来做。 SFT 复制作业就可以了,根本不需要在上面做机器学习烧显卡。

所以现在全球开源社区都疯了, HuggingFace 连夜成立项目组,准备复制整个训练过程。很多网友说这个特别的才算。 Open !这项工程也叫做 Open R1 。
还有网友算过账:用 R1 方案训练 7B 模型,成本直接从百万美元降到二十万,显卡用量比挖矿还省,这简直就是真正的科技平权行为,活该它爆红!
巧合的是,跟 R1 与此同时,许多赛博基建大厂的股价开始下跌,英伟达盘前跌落。 10% 上述。很多人认为可能是因为 DeepSeek 绝世训练费用,影响投资者的判断。
然而,在海的这一端,这样一款全部由中国团队制作的热门商品,再一次向世界证明了中国年轻人的潜力和创造精神。
正如梁文锋所说, " 中国是我们常说的 AI 和美国有一两年的差距,但是真的 gap 就是原创和模仿的区别…有些探索也是无法逃避的。 "
" 中国AI 不可能永远处于跟随位置。 "
顺便说一下,今天小红书上有网友被网友 DeepSeek 我害怕我的性能,害怕我会被吓到。 AI 取而代之的是她的方向 DeepSeek 在传达了忧虑之后,它给出了这样的答案:

发文:纳西



本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com