
腾讯推出PDF识别神器:复杂文档分析精度超过98%
2024-06-23








快科技 6 月 21 每日新闻,腾讯云大模型知识引擎新鲜发布,它有一个新的能力——大模型知识引擎文档分析!
基于腾讯优图实验室开发的新一代多模态文档分析大模型,可以先对文档的所有内容位置和类型进行布局分析和定位,然后准确识别文本表格公式等内容,最后根据我们人类的阅读顺序导出连贯可读的内容。
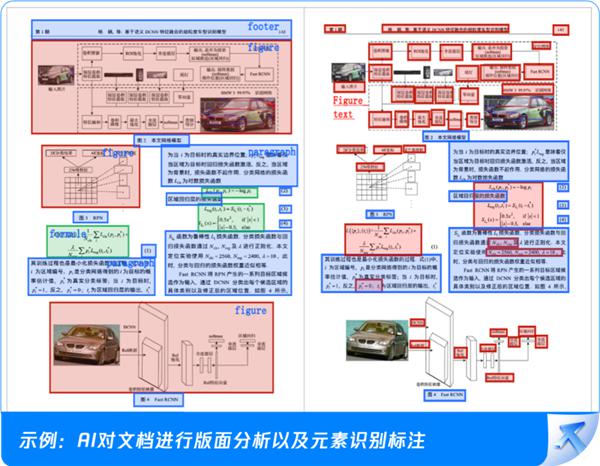
举例来说,面对带表 PDF 文件,尤其是没有框架的表格,可以通过结合团队关系特征和元素特征来预测表格的团队间隔。
算法可以对表格数据和结构进行推理和正确恢复,大大提高了识别的准确性。每次复制表格时,数据错位的人都有福了!
不只是中英文,它还支持 20 语言,以及繁体字、生僻字等多种字体。
更加令人惊讶的是,它还支持识别后的图片,PDF 文档转换为 Markdown 格式导出。
腾讯表示,目前对复杂文档进行大模型知识引擎文档分析的准确性可以达到 98% 以上。
现在,这个文档分析功能已经在多个产品上线了,大家也可以点击这个在线体验。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com