
大型盲测试炼场上市,国产黑马冲进世界七强,中文并列第一。







智能东西5月22日报道,星期二,LMSYS,一个著名的大型试验场。 Chatboat Arena盲目测评结果更新,国内大型独角兽1000亿元参数闭源大型Yi-Large在最新榜单中排名世界第七,在中国大型模型中排名第一。超过Llama-3-70BB、Claude 3 Sonnet;其中文分榜与GPT-4o并列第一。
LMSYS Chatboat 第三方非营利组织LMSYSArena Org发布,其盲测结果来自于全球用户的真实投票数量,目前已超过1170万。本次比赛共有44个模型,包括开源大模型Llamama。 3-70B,还包括各大厂商的闭源模式。
Chatbot Arena评估过程涵盖了各种因素的共同作用,从用户直接参与投票到盲目测试,再到大规模投票和动态更新的评分机制,保证了评估的客观性、权威性和专业性,能够更准确地反映大模型在实际应用中的表现。
GPT-4o上周OpenAI的测试版本就是“im-also-a-good-gpt2-chatbot"马甲闯入Chatbot 排名超过GPT-4的Arena排名-Turbo、Gemini 1 .5 Pro、Claude 3 0pus、Llama-一批国际大厂,如3-70b,是主要的底座模型。OpenAI CEO Sam Gpt-4o发布后,Altman还亲自转帖引用LMSYSYS。 Arena盲测擂台的测试结果。
根据Elo最新公布的评分,GPT-4o以1287分排名第一,GPT-4-Turbo、Gemini 1 5 Pro、Claude 3 Opus、Yi-在1240上下评分位置上,Large等模型紧随其后。
排名前六的模型都来自OpenAIAI,海外巨头。、Google、Anthropic,且GPT-4、Gemini 1.5 Pro等模型均为万亿级超大参数规模旗舰模型,其它模型均为数千亿参数等级。
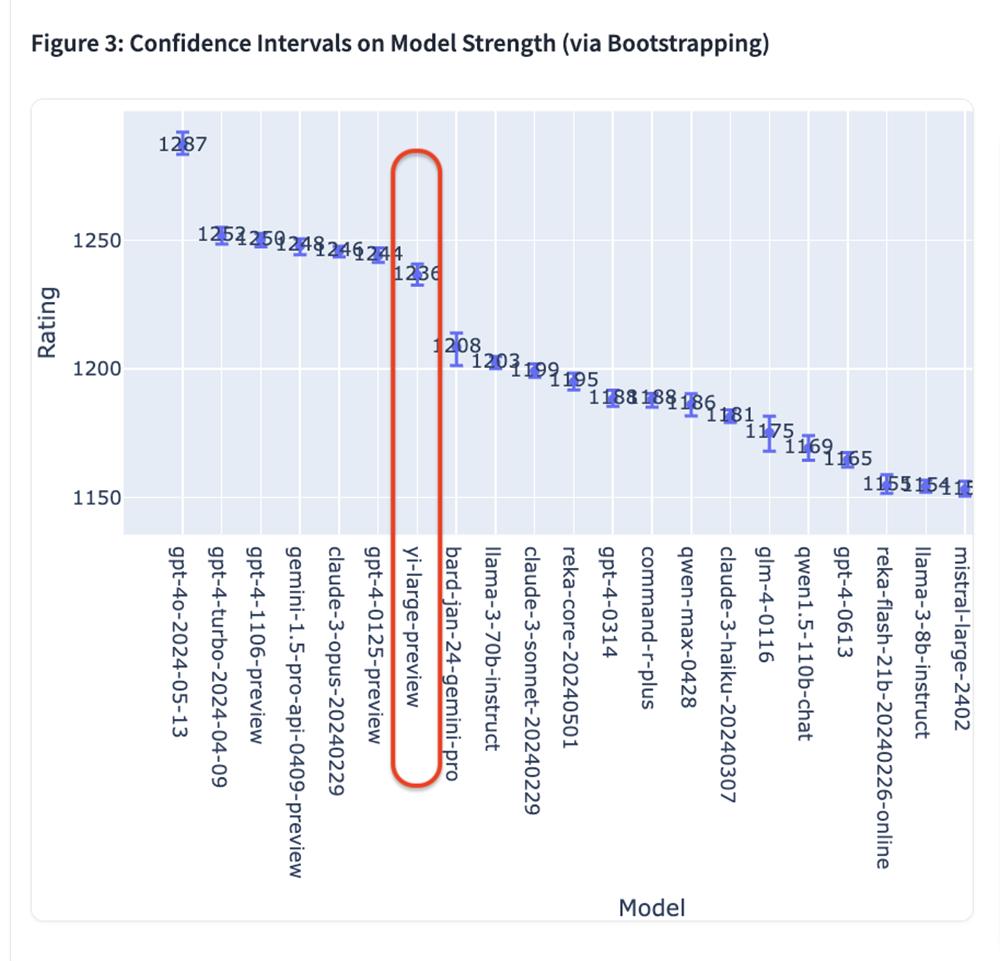
零一万物是榜单上唯一一家自有模型进入前十的中国大模型公司,按机构排名在OpenAI。、Google、在Anthropic之后,排名第四。Yi-Large大模型以仅1000亿参数排名第7,评分为1236。
Bard之后(Gemini Pro)、Llama-3-70b-Instruct、Claude 3 Sonnet的分数约为1200分;阿里巴巴的Qwen-Max大型Elo分数为1186,排名第12。;GLM-4大型智谱AIElo分数为1175,排名第15。
提高Chatbot 在Arena查询的整体质量中,LMSYS还实施了反复删除数据的机制,并提交了删除冗余查询后的列表。这一新机制旨在消除过多冗余的用户提醒,例如重复过多的“您好”。这种冗余提醒可能会影响排名的准确性。LMSYS明确表示,删除冗余查询后的列表将在后续成为默认列表。
去除冗余查询后的列表, Yi-与Claude相比,LargeElo评分更进一步。 3 Opus、GPT-4-0125-preview并列第四。
LMSYS Chatbot Arena 盲目测试炼场公开投票地址:
https://arena.lmsys.org/
LMSYS Chatbot Leaderboard 评估排名(滚动更新):
https://chat.lmsys.org/?leaderboard
01.将一个GPU挤出更多的价值,李开讨论了大模型价格战的影响。
根据零一万物CEO李开复博士的说法,取得了上述优异成绩,Yi-Large的大模型尺寸不到谷歌和OpenAI的1/10,训练用的GPU计算率不到他们的1/10。其背后,一年前零一万物的GPU计算率仅为谷歌和OpenAI的5%。;而且这几支海外顶级AI队伍都是千人级的,零一万物的模型加上基础设施队伍总共不到百人。
他说:“我们可以把同样的GPU挤出更多的价值,这是我们今天能取得这些成就的一个重要原因。李开复说:“如果我们只评估1000亿元的模型,至少在这个排名中是世界第一。我们仍然为这些点感到骄傲。一年前,我们落后于OpenAI和谷歌,开始做大模型研发已经7到10年了。现在,我们和他们的差距是6个月,这大大减少了。”
为什么追得这么快?零一万物模型训练负责人黄文浩博士说,零一万物在模型训练中的每一步决策都是正确的,包括提高数据质量和做scaling需要很长时间。 Law,下一步就是不断提高数据质量,做scale up。
与此同时,零一万物非常重视Infra的建设,算法Infra是一个协同设计的过程,从而使计算率达到更好的水平。在这个过程中,它的人才团队是工程,Infra、三位一体的算法。
李开复说,零一万物希望从最小到最大都能成为中国最好的模型。未来可能会有更小的模型发布,他们会努力在同样的尺寸下达到行业的第一梯队,在代码、中文、英文等诸多方面表现出色。有各种简单的应用机会,零一万物的打法是“一个都不放过”。
他还注意到了最近的大型API价格战。李开复认为零一万物的定价还是很合理的,他也在花很多精力进一步降价。
"100万只token,花十几块还是花几块钱有很大区别?我认为我们是一个不可避免的选择,100万只token应用非常广泛,应用非常困难。”他说,零一万物的API横跨国内外,有信心在全球范围内表现良好,性价比合理。他说:“到目前为止,我们刚刚宣布的性能肯定是国内性价比最高的。每个人都可能使用千token、百万token,每个人都可以自己计算。”
在他看来,每年整个市场的推理成本都会降到之前的1/10,今天的API模型调用比例还是很低的。如果能被更多的人使用,这是一个非常好的消息。
李开复认为,大模型公司不会做出不理智的双输游戏。技术是最重要的。如果技术不好,他们只会通过支付金钱来做生意。如果中国以后就这样卷土重来,大家都宁愿失去一切,也不愿让别人赢,那么一切都会离开国外市场。
黄文昊分享说,目前零一万物没有数据短缺的问题。看到数据有很多潜力可以挖掘,有一两个数量级的空间。最近有一些关于多模式的发现,可以增加一两个额外的数量级。
02.Yi-Large:GPT-4o与中文排名第一,挑战性任务评估排名第二。
智谱GLM44在国内大型模型制造商中、阿里Qwen Max、Qwen 1.5、零一万物Yi-Large、Yi-这次34B-chat都参加了盲测。
除了名单之外,LMSYS的语言类别还增加了三种语言评价:英语、中文和法语。中文语言分单上,Yi-Large和OpenAI GPT-4o排名并列第一,Qwen-Max和GLM-四也都排在前列。
编程能力,长问题和最新推出的 “艰难提示” ,这些评价都是LMSYS给出的目的性名单,以专业性和高难度为基础。
在编程能力(Coding)排行榜上,Yi-在Anthropic旗舰模型Claude中,Large的Elo成绩超过了Claude。 3 Opus,与GPT-4o相比,仅低于GPT-4o-Turbo、GPT-4并排第二。
在长提问(Longer Query)榜单上,Yi-与GPT-4相比,Large同样位居世界第二。-Turbo、GPT-4、Claude 3 Opus并排。
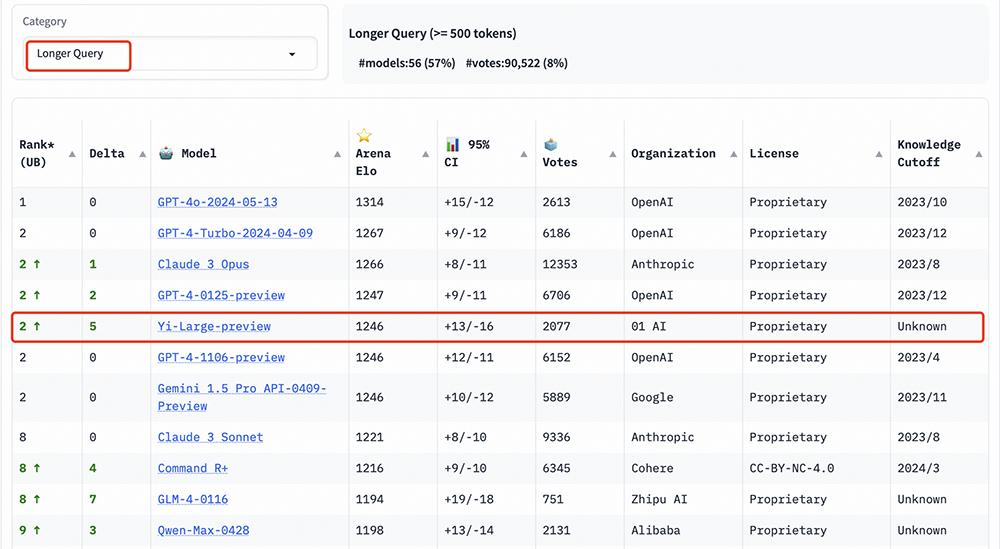
艰难提示词(Hard Prompts)类别包括Arena用户提交的提醒,这些提醒经过特别设计,更加复杂,要求更高,更加严格。
当面对挑战性任务时,LMSYS认为这一提醒能够检测到最新语言模型的性能。这个列表,Yi-Large和GPT-4-Turbo、GPT-4、Claude 3 Opus并排排名第二。
进入benchmark时代后,盲测机制提供了更加公平的大模型评估机制
如何对大模型进行客观公正的评价,一直是业界普遍关注的话题。经过去年混乱的大模型评价浪潮,行业更加注重评价集的专业性和客观性。
就像Chatbot Arena不仅可以为模型提供公平的评价,还可以通过大规模的用户参与来保证评价结果的真实性和权威性,提供真实的用户反馈,选择盲测机制,防止操纵结果,不断更新评分系统。
LMSYS Chatbotbot是Org发布的 Arena以其新颖的“试炼场”方式,以及测试团队的严谨性,成为全球公认的标杆。
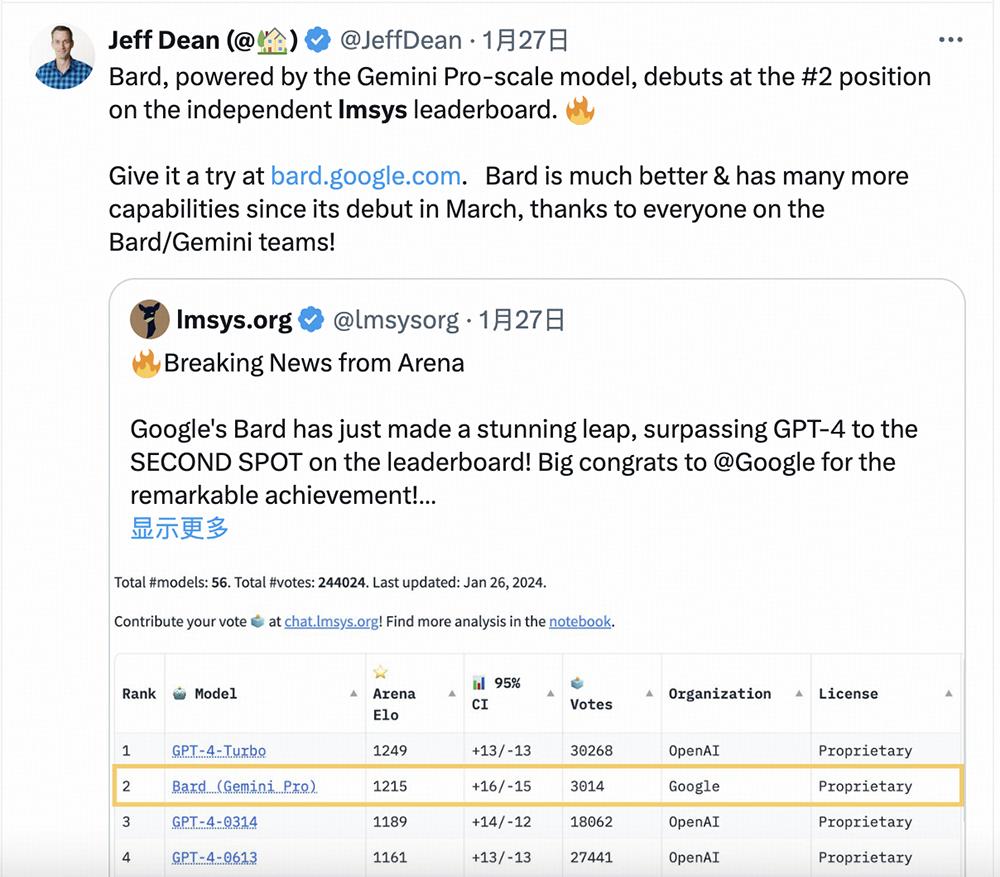
Google JeffffFDeepMind首席科学家 曾经引用LMSYS的Dean Chatbot 为了证明Bard产品的性能,Arena的排名数据。
AndrejoopenAI创始团队成员 Karpathy发帖称赞道:“Chatbot Arena is awesome. ”
发布Chatbot LMSYSYSA评估列表 Org是由加州大学伯克利分校的学生和教师、加州大学圣地亚哥分校和卡耐基梅隆大学共同创办的开放研究机构。
01万物模型培训负责人黄文浩博士总结说,LMSYS评价机制的问题来自真实用户聊天,动态随机变化。没有人能预测问题的分布,所以不能优化模型的单一能力,客观性更好。此外,它由用户评分,评估结果将更接近用户在实际应用中的偏好。
虽然主要人员来自大学,但LMSYS的研究项目与行业非常接近。他们不仅开发了自己的大语言模型,还向行业导出了各种数据(他们推出的MT-Bench是权威评估集,指令遵循方向)。、评估工具,还开发了一种分布式结构,用于加快大模型训练和推理,提供在线live大模型打擂台测试所需的算率。
Chatbot Arena参考了搜索引擎时代的横向比较和评价思路。首先,它以匿名模型的形式向用户呈现所有上传和评价的“参与”模型。然后号召真正的用户输入自己的提示,在不知道模型名称的情况下,由真正的用户回答两种模型产品。
https在盲测平台://arena.lmsys.org/上,两组大模型相比,客户自主输入问大模型问题,模型A、模型B两侧各生成两个PK模型的真实结果,用户在结果下方投票四个选项之一:A模型更好,B模型更好,两者平局,或者两者都不好。提交后,可以进行下一轮PK。
在线即时盲测和匿名投票是通过众筹真实用户进行的,Chatbot Arena不仅可以减少偏见的影响,还可以最大限度地防止基于测试集刷榜的概率,从而提高最终结果的客观性。经过清洗和匿名处理,Chatbot Arena将公开所有用户的投票数据。
收集真实用户投票数据后,LMSYS Chatbot Arena还使用Elo评分系统来量化模型的性能,进一步优化评分机制,确保排名的客观性和公平性。
Elo评分系统是由匈牙利裔美国科学家Arpadad基于统计原理的权威评价系统。 Elo博士的成立旨在量化和评估各种游戏的竞技水平。Elo等级分级制度在国际象棋、围棋、足球、篮球、电子竞技等运动中发挥着重要作用。
在Elo评分系统中,每个参与者都会得到标准的分数。每场比赛结束后,参与者的分数将根据结果进行调整。系统会根据参与者的分数来计算他们赢得比赛的概率。一旦低分球员击败高分球员,低分球员可以获得更多的分数,反之亦然。
04.结论:后发有后发优势,中国人做商品比美国人好。
随着大型模型进入商业应用,模型的实际性能迫切需要通过对具体应用场景的严格考验。整个市场正在探索一个更客观、更公正、更权威的评价体系。像Chatbot这样的大型制造商正在积极参与 在Arena这样的评估平台上,产品的竞争力是通过实际的用户反馈和专业的评估机制来确认的。
李开复认为,美国擅长做突破性研究,拥有一批创造性很强的科学家。然而,中国人的聪明、努力和努力不容忽视。零一万物把7-10年的差距降到只有6个月,证明做一个好的模型绝对不仅仅是看更多的论文,更多的是发明新的东西,先做还是后做。
“做得最好的是强大的。”在他看来,后发有后发优势,美国的创造力值得学习。“但我认为我们比执行力、良好的感觉、商品和商业模式更强大。”
零一万物的企业模式初步客户在国外,因为他们的团队判断海外用户的支付意愿或金额远大于国内用户。按照中国现在的说法 B卷的情况,业务做一单赔一单,这种情况在AI初期就是AI。 1.0时代太多了,零一万物团队不愿意这样做。
“我们今天可以看到的模型表现超过了其他模型,欢迎不同意的同行来到LMSYS打擂台,证明我错了。但是直到那天,我们会继续说我们是最好的模型。”李开复说。
本文来自微信微信官方账号的“智东西”(ID:zhidxcom),作者:ZeR0,编辑:漠影,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com