
Gemini谷歌数学版解决奥运难题,堪比人类数学家。








四个月的迭代,让Gemini 1.5 Pro已经成为世界上最强的LLM(几乎)。
在谷歌I/O发布会上,劈柴宣布Geminini。 1.5 Pro系列升级,包括前后200k的支持,超过35种语言。
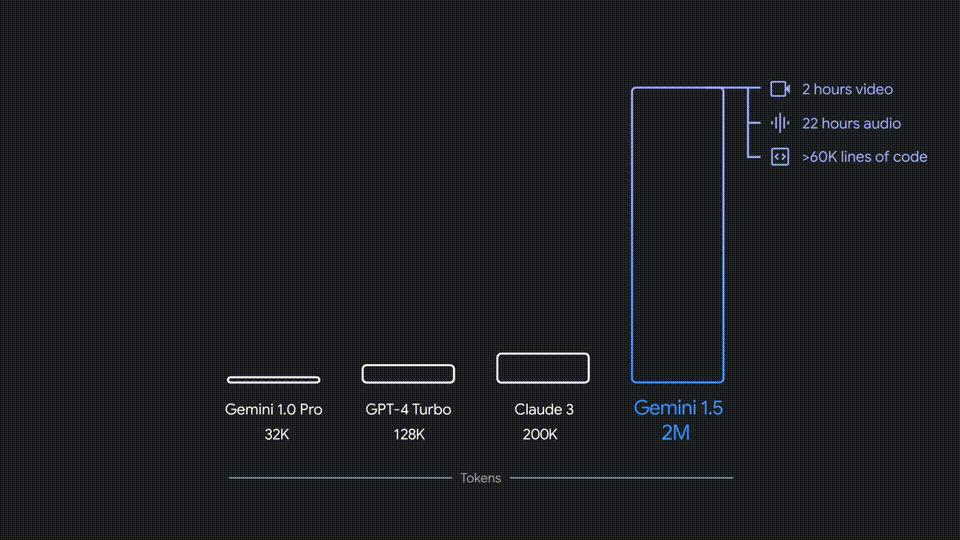
同时,新成员Geminini 1.5 Flash推出,设计体积更小,运行更快,还支持前后100k。
近期,Gemini 1.5 最新版本的Pro技术报告已经发布。
论文地址:https://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf
报告显示,升级后的模型Gemini 1.5 Pro,所有关键基准测试都取得了显著进展。
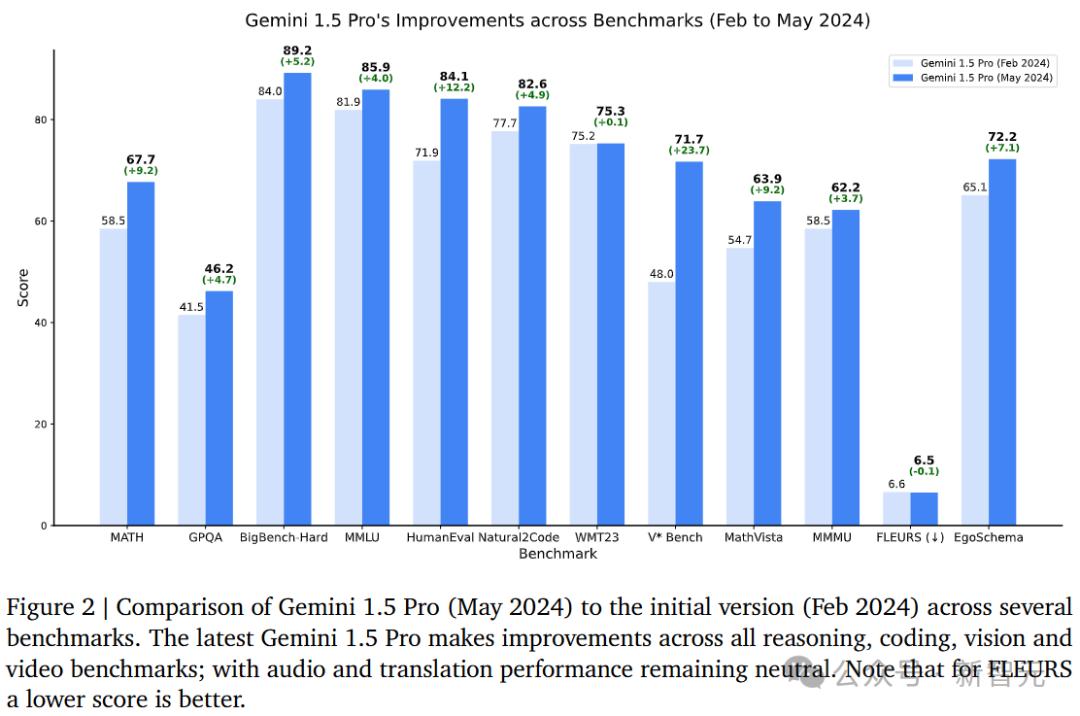
简而言之,1.5 Pro的性能已经超越「超大杯」1.0 Ultra,而1.5 Flash(最快模型)性能接近1.0 Ultra。
甚至,新的Geminini。 1.5 Pro和Gemini 1.5 在大多数文本和视觉测试中,Flash的性能仍然优于GPT-4。 Turbo。
Jeff Dean发表了一篇文章,Gemini 1.5 Pro「数学定制版」在基准测试中,91.1%的成绩被打破。
而且三年前的今天,SOTA只有6.9%。
而且,数学标准版本 Gemini 1.5 在数学标准方面,Pro的表现与人类专家相当。

三年来,数学评估暴涨84.2%
对于这个「数学定制版」该团队采用了多种来自数学竞赛的基准测试来评估Gemini的能力,包括MATH。、AIME、Math HidemMathMath,Odyssey和团队内部开发的测试、IMO-Bench等。
结果表明,在所有测试中,Gemini 1.5 Pro「数学定制版」都明显优于Claude 3 Opus和GPT-4 Turbo,与通用版本相比,1.5 Pro有了显著的改进。
特别是在MATH测试中取得了91.1%的突破性成绩,并且不需要使用任何外部工具,如定理证书库或谷歌搜索,这与人类专家的水平相当。
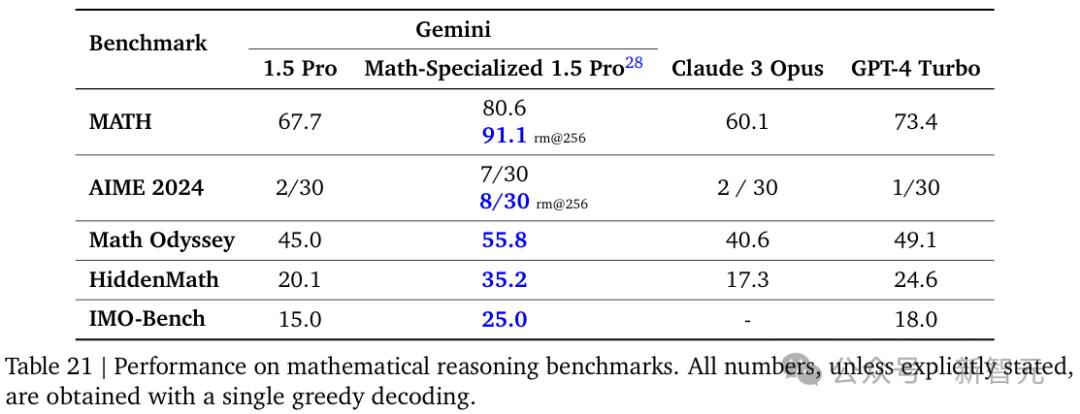
另外,集中在AIME检测中,Gemini 1.5 Pro「数学定制版」可以解决的问题数量是其它模型的4倍。
这里有两个亚太数学奥林匹克竞赛,曾经让之前的模型无计可施。(APMO)题。
在这些例子中,上面的例子非常有代表性,因为它是一个证明问题,而非计算问题。
对于这一点,Gemini给出的解决方案不仅是直截了当的,而且非常重要。「漂亮」。

Gemini 1.5 全面提升Pro核心性能
文本评定
除数学外,升级后的1.5 在推理、编码、多模态多项基准测试中,Pro取得了显著的优势。
甚至连主推导速度都是1.5。 Flash,在性能上也不输1.0 Ultra。
尤其在MMLU通用语言逻辑基准测试中,Gemini 1.5 在正常的5个样本设置中,Pro得分为85.9%,在大多数投票设置中得分为91.7%,超过GPT-4。 Turbo。
相对于2月份出版的技术报告,新升级1.5 在代码的两个标准中,Pro有了很大的提高,从71.9%上升到84.1%(HumanEval),Natural22.7%上升到82.6%Code)。
新升级1.5,多语种基准测试 Pro的能力略有下降。
另外,在5月份的报告中,对数学和推理能力进行分离评估,新升级1.5。 从91.7%到90.8%,Pro明显下降。
MMLU的性能在推理测试中从81.9%提高到85.9%。
2月版
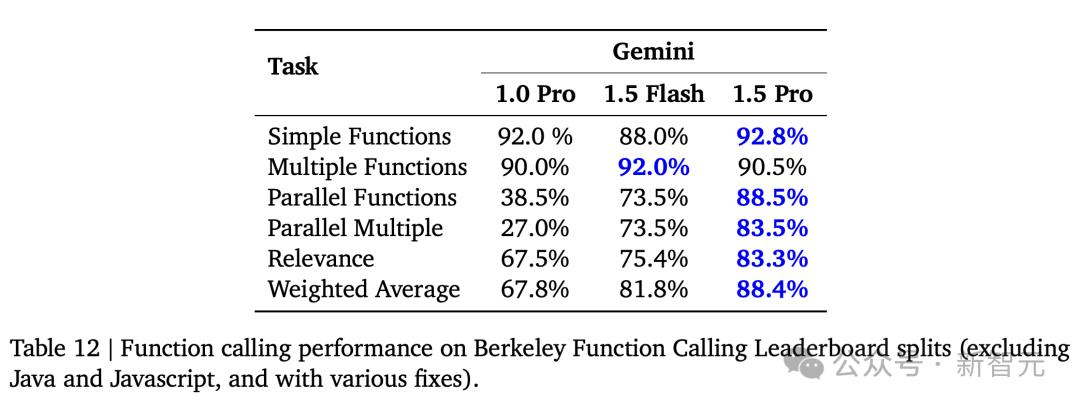
对于函数调用,1.5 除了多个函数之外,Pro在多个任务中获得了最高分。1.5 在多个函数任务中,Flash获得了领先优势。
对于指令调优,1.5 面对更长时间的指令1326提醒,Pro的响应精度最高。而且406的指令更短,1.00 Ultra的表现更加出色。
涉及到更专业的知识问答,1.5 几乎和1.5一样,Pro准确 Flah持平,仅差0.6%,但都明显优于1.0。 Pro和1.0 Ultra。
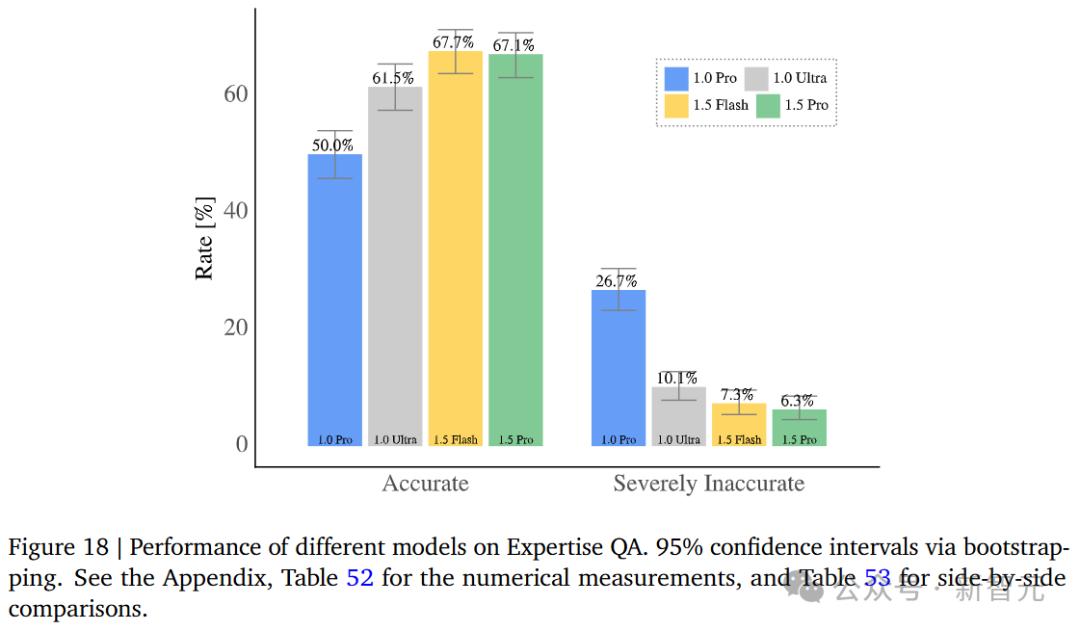
对于STEM前后的问答任务,在Qasper数据上,Gemini 提高1.0和1.5的准确性,同时显著降低不准确性。
我们来看看喜好的结果,根据不同的提醒和1.0。 与Pro相比,1.5 Pro和1.5 Flash的分数相对较高。
多模态评定
针对多模态性能,技术报告涉及多个基准测试,包括多模态推理、图表与文档、自然图像和视频理解四个方面,共有15个图像理解任务和6个视频理解任务。
总的来说,除了一个测试,1.5。 Pro的表现可以超过或与1.0相同。 Ultra相当,而且轻便1.5 在大多数测试中,Flash超过1.0 Pro。
能够看见1.5 在多模态推理的4个基准测试中,Pro得到了改进。
1.5 Pro实现了从47.9%到62.2%的提升,甚至达到了94.4%和1.5%的Ai2D检测水平。 Flash也得到91.7%的高分。
对多模态大模型、图表和文档的理解更具挑战性,因为要准确地分析和推理图像信息。
Gemini 1.5 在ChartQA,Pro获得了87.2%的SOTA结果。
在TAT-DQA测试中,分数为1.0。 9.9%的Pro升至37.8%,1.5% 与1.00相比,Flash Ultra也有近10%的提升。
另外,团队还创建了BetterQA等9种不相交的能力评估。资料显示,与上一代相比,1.0 Pro,1.5 Pro总体增长超过20%。
关注模型对物理世界的认知和空间推理能力,对自然图像理解进行检测。
专用V*检测,1.5 SEAL,Pro和测试提出者发布的模型,几乎是一样的。
在Blink测试中,人类擅长但不擅长模型,1.5 Pro实现了45.1%(1.0 Pro)在61.4%的增长之前,Flash的成绩仍然高于1.00(56.5%) Ultra(51.7%)。
除了「海底捞针」,这个团队还为Geminini 1.5 在其它视频理解方面,Pro进行了基准测试,但是改进没有前三个方面那么明显。
与2月份发布的Gemininini相比,在VATEX英语和中文两项测试中, 1.5 Pro技术报告,经过三个月的训练,提高不超过2分。
检测YouCook2时,1.5 似乎Pro永远无法达到1.0。 与2月份技术报告中的134.2相比,Ultra的135.4分降至最新的106.5分。
有趣的是,在OpenEQA零样本测试中,1.5 Flash得分63.1,甚至超过1.5。 Pro的57.9。由于1.55,技术报告解释 Pro拒绝回答某些问题。
2月版
对比GPT-4、Claude 3优势明显
下一步,再看横向对比,新升级的1.5。 Pro与GPT-4、相比之下,Claude模型的性能如何?
改善模型诊断能力
下面显示的是,在2000个MRCR任务案例中,字符串相似度累计平均分数与前后文长度之间的函数关系。
在和GPT-4 Turbo和Claude 在对比2.1时,研究人员发现8K和20K的短语分别为1.5。 Pro和1.5 Flash的性能比这两个模型要好得多。
1.5,随着前后文长度的增加 Pro和1.5 Flash的性能下降幅度大大缩小,最多可以达到100万个token。
将小语种Kalamang翻译成英语的量化结果如下。
新升级的1.5 在喂了半本书,甚至整本书的数据之后,Pro的性能都有了很大的提高,比GPT-4还要好。 Turbo和Claude 3的表现。
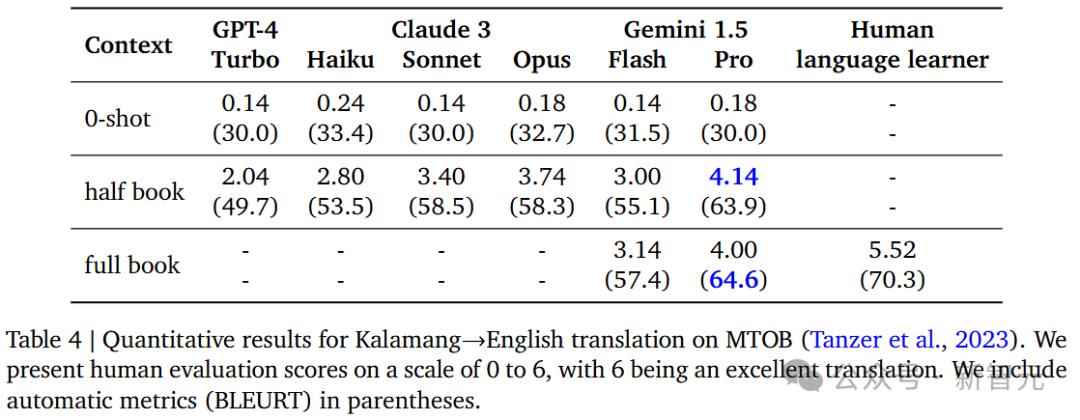
但是,在将英语翻译成Kalamang语言的量化结果中,1.5 Pro的胜率也是最高的。
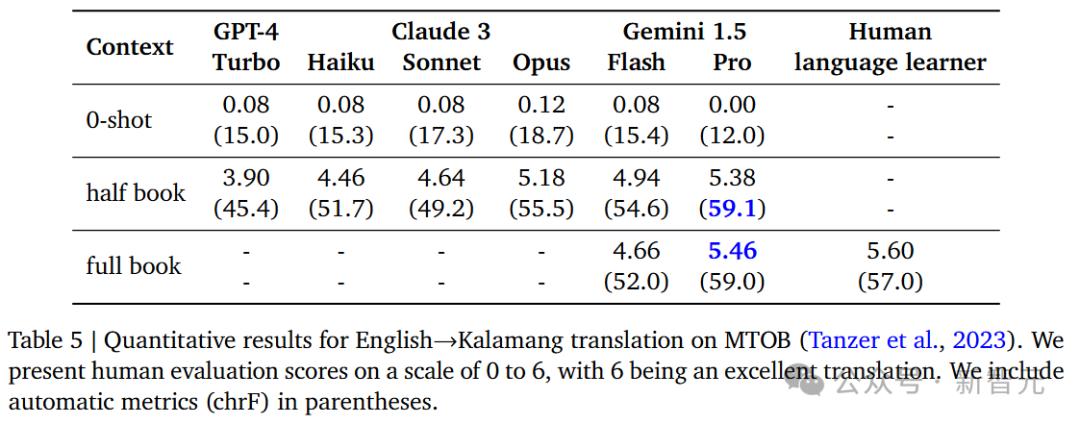
低资源机器翻译前后文拓展
再来看,在「低资源」在机器翻译中,模型前后文学学习拓展(Scaling)表现。
1.5随样品数量的增加而增加 Pro的翻译性能越来越好,大大超越了GPT-4 Turbo。

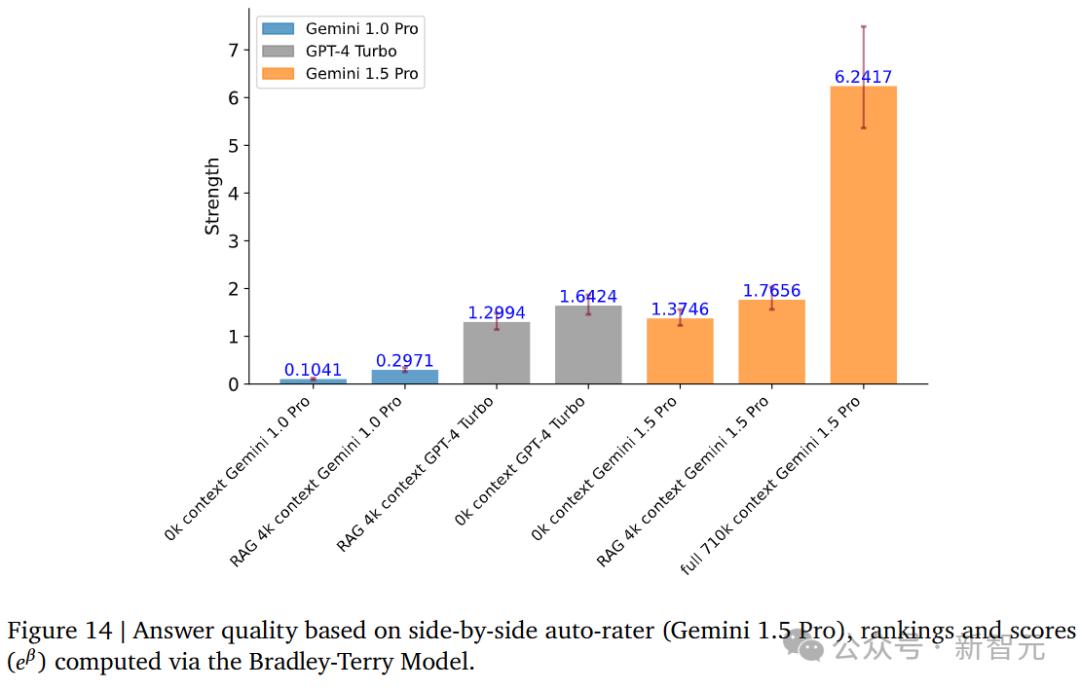
QA,长前后文本
1.5针对长文本的问答 在710k左右的文本中,Pro的表现明显优于GPT-4 Turbo。此外,在RAG的加持下,超越了无前后文,支持4k上下文的1.5。 Pro。
长前后文音频
每一个模型的单词错误率在音频长上下文的测试中表现如何?
能看到,1.5 在OpenAI中,Pro只有5.5%的Whisper模型错误率高达12.5%。
但是和2月份的报告相比,1.5 在Pro的音频长度下,单词的错误率仍然明显下降。
2月版
QA长前后文视频
1.5小时视频问答任务, 在不同的标准上,Pro的准确性与3分钟视频任务的准确性基本一致。
再次看看去年2月版的对比,1.5 从最高0.643到0.722,Pro在一小时任务中的准确率有了很大的提高。另外,在3分钟视频QA任务中,从0.636上升到0.727。
2月版
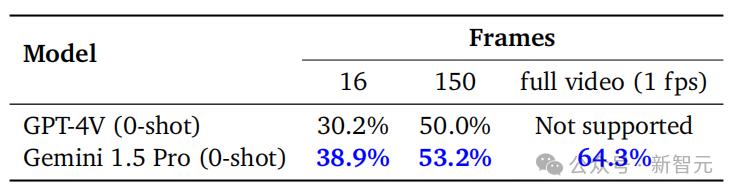
在1H-VideoQA测试中,团队在一个小时的视频中每秒取出一帧图片,最后在线性下取样到16帧或150帧,分别输入GPT-4V和Geminini。 问答1.5。
无论帧数多少,Gemini 1.5 Pro的性能比GPT-4V强,其中16帧测试的优势最为明显(36.5% vs. 45.2%)。
看完整个视频后再回答,Gemini 1.5 Pro从2月份的64.3%提高到72.2%。
2月版
长期前后规划
「推理」和「规划」虽然LLM在推理上取得了显著的进步,但是技能对于解决问题还是非常重要的。
本报告特别呈现了Geminini。 规划能力评估1.5涉及移动积木、安排物流路线、室内导航、规划时间表、旅行路线等任务场景。
在测试过程中,模型必须根据给定的任务一次快速生成解决方案,类似于人类。「头脑风暴」过程。
总体上,Gemini 1.5 在大多数情况下,Pro的表现优于GPT。 4 Turbo,不但可以在少样本时做好计划,而且可以更有效地利用上下文信息。
更加轻巧的Gemini 1.5 Flash的表现一直不敌Geminini。 1.5 Pro,但是在几乎一半的情况下,可以和GPT-4 Turbo的表现是相当的。
GPT-4 在BlocksWorld中,Turbo的零样本表现接近于零,而Gemini 1.5 Pro和Flash分别达到35%和26%。
Calendar GPT的1-shot精度在10%以下,Scheduling也是如此,而1.5。 达到33%的Pro。
1.5随样品数量的增加而增加。 虽然GPT-44-Pro的表现基本持续提升, 当样本增加到一定程度时,Turbo会呈现下降趋势,甚至在Logistics中持续下降。
比如Calendarar 在Scheduling中,当样本数逐渐增加到80-shot时,GPT-4 Turbo和1.5 Flash的准确率只有38%,比Gemini还要高。 1.5 Pro降低了32%。
之后增加到400-shot时,1.5 Pro已经达到了77%的准确率,而GPT仍然徘徊在50%左右。
非结构化多模态数据分析任务
现实世界中的大多数数据,如图像和对话,仍然是非结构化的。
为了将图像中包含的信息提取到结构化数据表中,研究人员向LLM展示了一组1024张图像。
图17显示了从图像中获取不同类型信息的准确性结果。
Gemini 1.5 在所有属性提取中,Pro的准确性提高了9%(平方根)。与GPT-4相比, Turbo,1.5 Pro提高了27%。
但是,在评估时,Claude 3 API不能分析超过20个图像,所以Claude 3 最终限制了Opus。
另外,数据显示,1.5 Pro在处理更多图像时会带来持续更好的效果。这表明该模型可以有效地使用额外和更长的前后文本。
对GPT-4来说 对于Turbo来说,随着提供的图像的增加,其准确性会降低。
参考最新技术报告的更多细节。
参考资料:
https://the-decoder.com/gemini-1-5-pro-is-now-the-most-capable-llm-on-the-market-according-to-googles-benchmarks/
https://x.com/JeffDean/status/1791522915021627438
https://x.com/sundarpichai/status/1791582982870089752
本文来自微信微信官方账号“新智元”(ID:AI_era),作者:新智元,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com