
GPT-5.5涨价翻倍,Gemini暴涨三倍:当前AI涨价潮还能持续多久?






AI前沿大模型的这场涨价博弈,究竟还能走多远?
从今年一月开始,全球GPU租赁价格涨幅已经超过两倍。
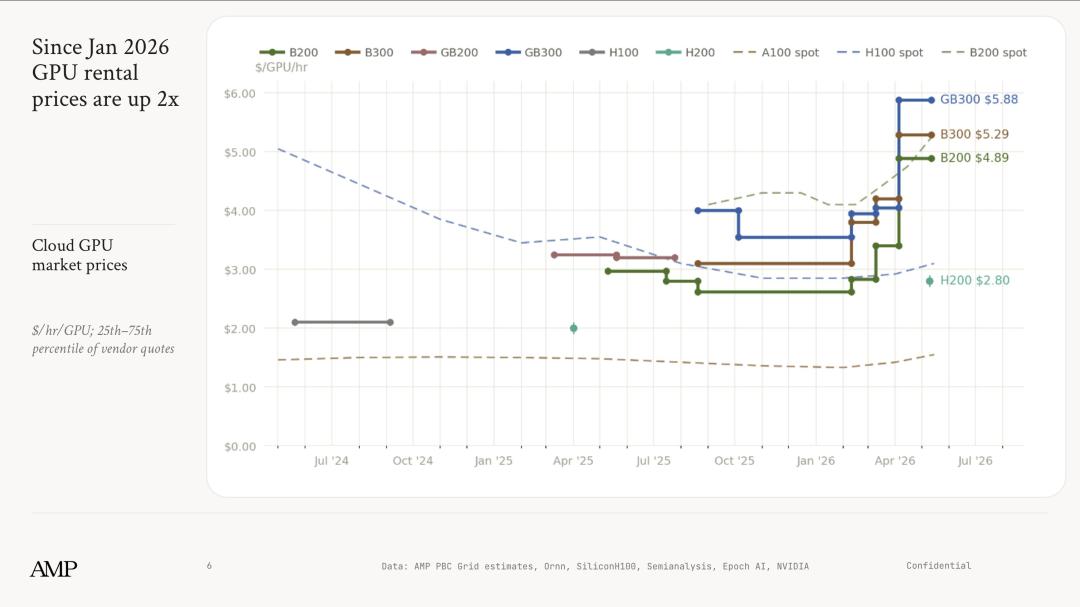
根据Counterpoint在今年2月推出的《内存价格追踪报告》数据,2026年第一季度至今,内存价格环比上涨幅度已经达到80%-90%,创下了历史最大涨幅记录。
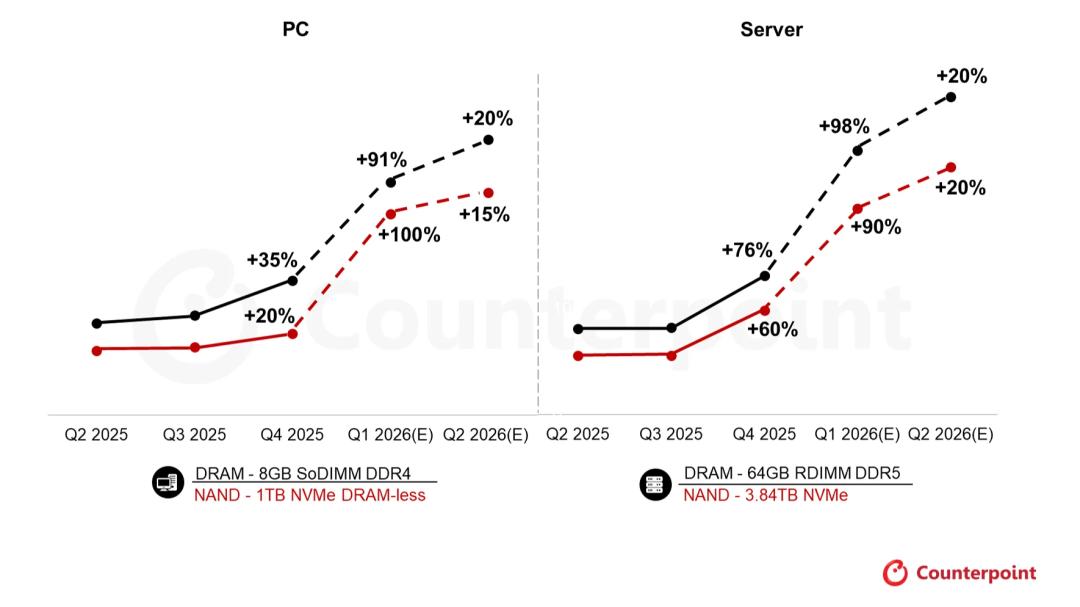
上游成本的暴涨,已经直接传导到了AI行业的下游终端。
AI研究机构Epoch AI最新发布的《梯度更新》报告做了一个直白测算:把全球所有Blackwell芯片的算力加总,算出能处理的Token总量,再和当前市场的实际需求做比对。
最终结论很残酷——供给完全跟不上需求。
暴涨的Token需求已经吞噬了算力供给
先看供给端的情况。
Epoch AI的测算以Kimi K2.6大模型为基准,该模型是拥有万亿总参数、320亿活跃参数的MoE架构。

在输入输出比为8000:1000的标准场景下,全球所有Blackwell芯片集群的理论吞吐量极限,是每秒约200亿输出Token。
这个数字听起来很大?换算一下,相当于全球每个人每月能分到700万Token。

但这只是理想场景下的理论值。如果把上下文窗口拉长到现在常用的128k,Blackwell的吞吐量会直接暴跌50倍,降到每秒仅约5亿输出Token。
再来看需求端。
Google不久前披露,自家产品现在每秒就要处理约12亿Token(包含输入+输出)。
按照行业常见的8k输入对应1k输出的请求比例换算,Google每秒的输出Token需求约为1.3亿。Exponential View估算,Google的需求大约占全球总Token需求的25%。
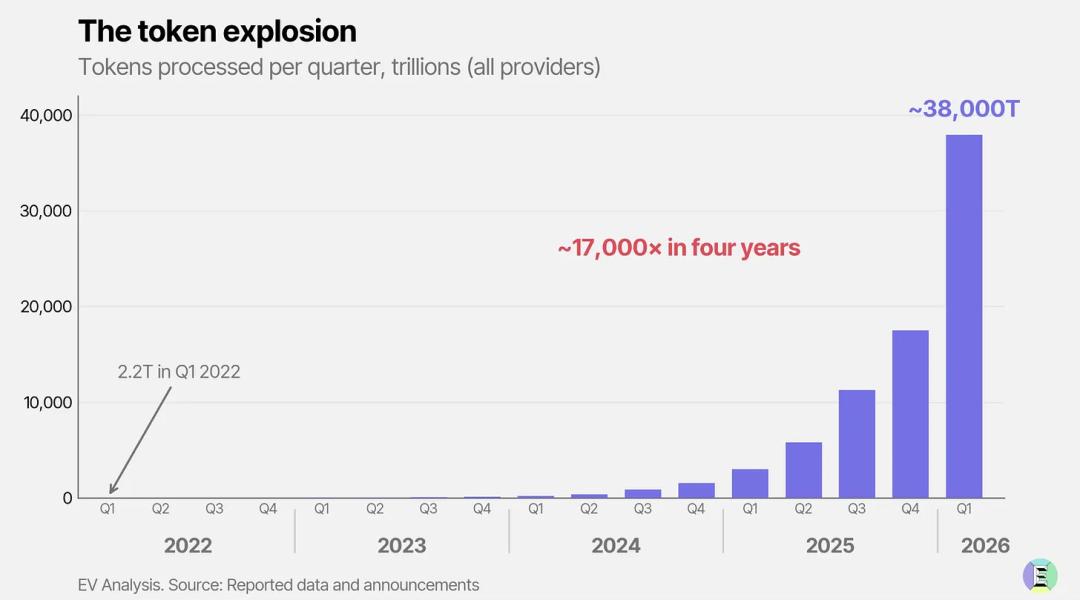
也就是说,以现在的需求来看,把全球所有Blackwell芯片全产能拉满,全部用来跑大模型,也只是刚好能勉强撑住。
那需求现在的增长速度是多少呢?
每年10倍。
从2024年开始,Google处理的Token量每年增长10倍,其他AI服务商的增长速度也基本和这个水平一致。
反观供给侧呢?全球AI算力每年只增长3.4倍,芯片内存带宽的年增速也只有4.1倍。
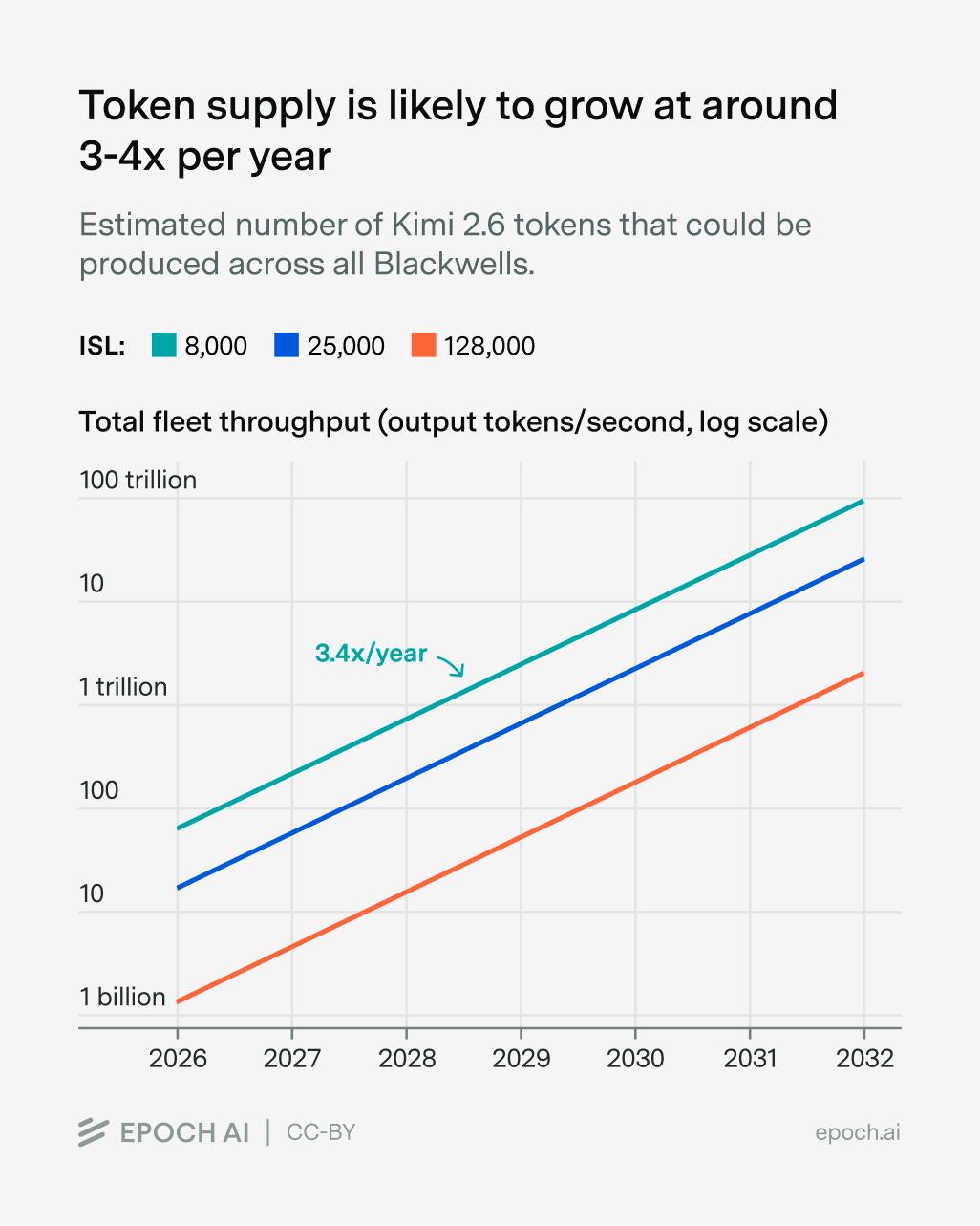
供给年增3.4倍对上需求年增10倍,供需缺口每年都在被越拉越大。
Meta员工日均消耗百万Token,企业端需求已经爆炸
算力紧缺从来不是抽象的数字,已经真实发生在企业日常运营中。
看看头部科技公司内部的情况就知道了。
The Information报道显示,Meta的8.5万名员工,每个月就要消耗掉60万亿Token。

换算下来,Meta每一位员工平均每天就要烧掉约100万输出Token。
Apple的消耗规模更惊人。
Apple部分工程团队,每天的Token使用预算就高达300美元——按照Kimi K2.6的定价计算,这笔钱足够一个人生成2500万输出Token。

这还只是两家头部公司的消耗。
现在全球大约有1400万软件工程师每天都在使用AI工具。
如果所有工程师的使用强度都达到Meta或者Apple员工的水平,全球Token吞吐需求将会直接飙升到每秒2亿到40亿Token。
40亿的需求,对比Blackwell在长上下文场景下5亿每秒的极限供给,差了整整一个数量级。
涨价持续,但增长开始放缓
更值得玩味的变化已经出现。
METR最新研究结果显示,Claude Code在实际开发测试中,反而让资深开发者的任务完成速度变慢了19%。
同时,VS Code相关AI编码插件的安装增速,从今年年初开始就已经明显放缓。
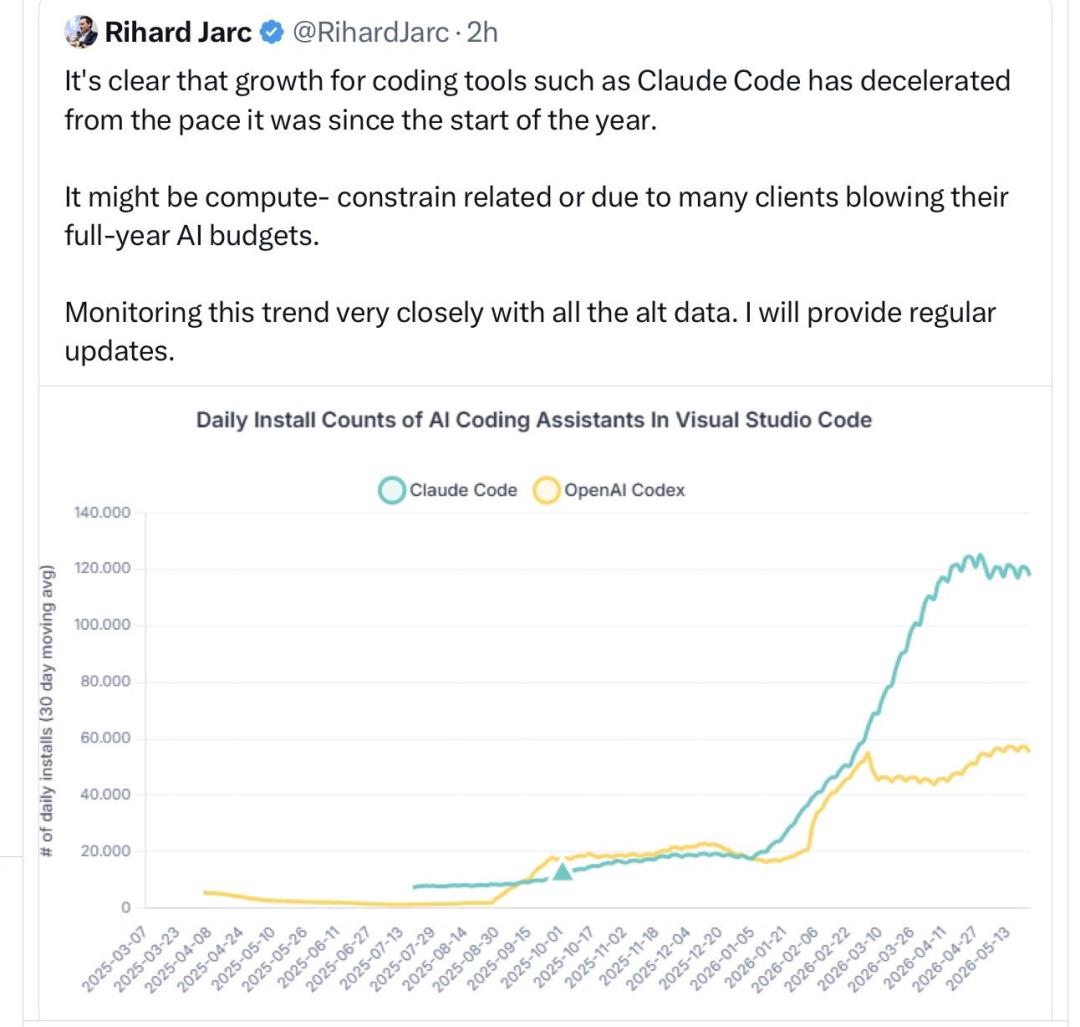
编码AI工具增长放缓,背后其实是两个因素的叠加:一方面是算力资源本身已经捉襟见肘,另一方面很多企业今年的AI预算已经提前花完。
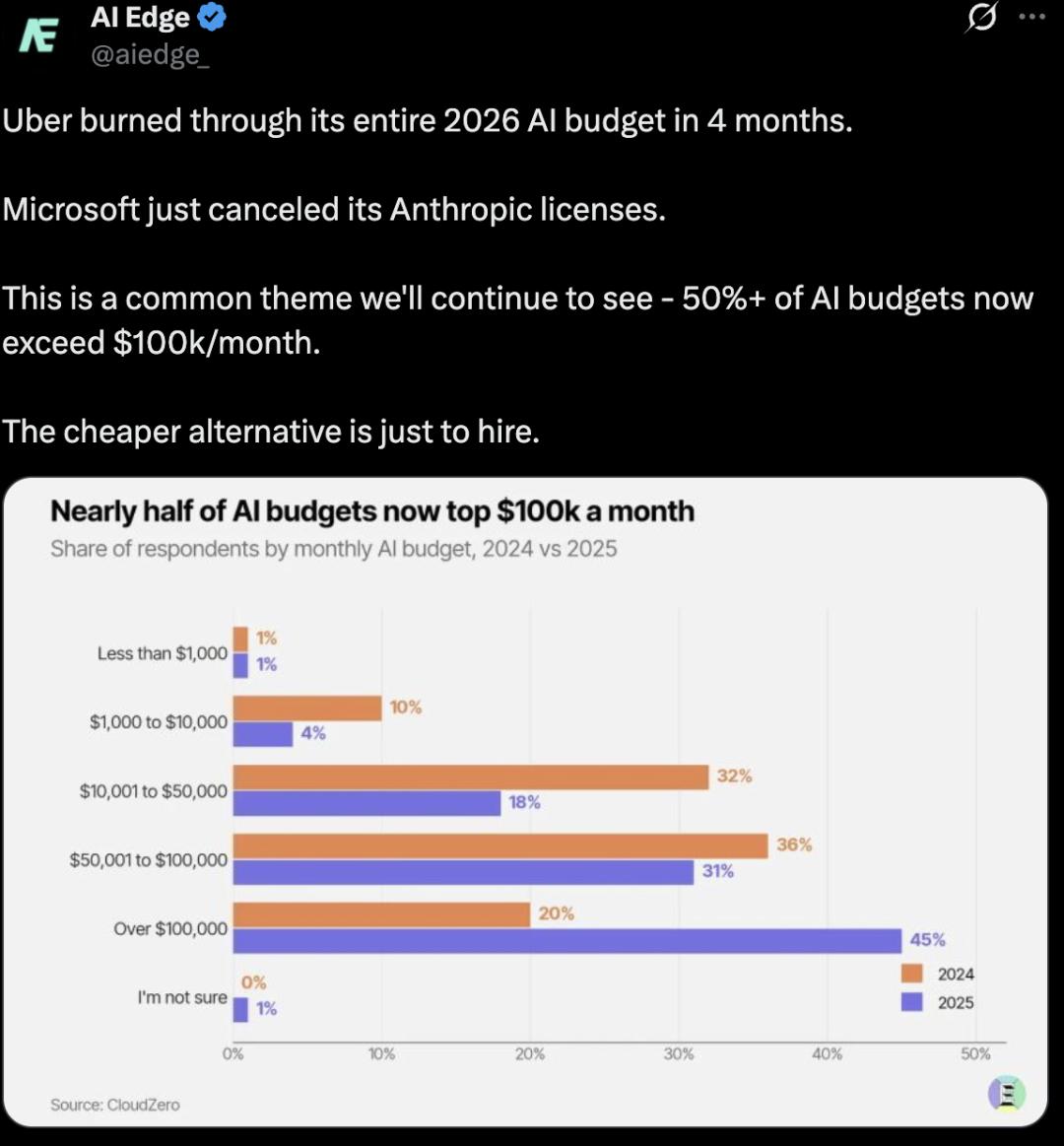
和增长放缓形成鲜明对比的,是前沿大模型的一轮接一轮涨价:ChatGPT Pro上调订阅价格,Claude API价格持续上涨,Gemini的涨幅最夸张,部分场景价格直接暴涨3倍,GPT-5.5的定价更是直接翻倍。

现在企业用AI,用量越来越大、花费越来越高,但获得的效果却不一定能跟上成本涨幅,这笔账企业很快就算明白了。
高性价比替代方案成新选择,前沿模型定价权动摇
市场已经出现了新的分流路线,很多企业开始转向高性价比的替代方案。
DeepSeek V3的训练成本只有头部前沿模型的1/10到1/20,API价格更是低到同类前沿产品的1/16。
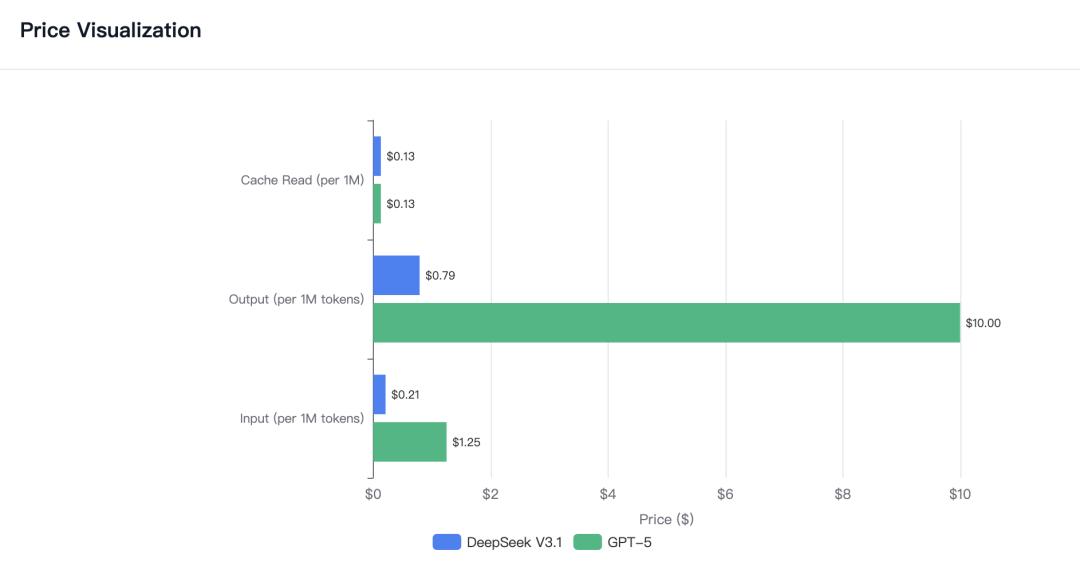
那性能呢?DeepSeek V3的实际表现已经逼近GPT-5的水平。
国外技术社区Hacker News上有一个热门帖子,创作者做了一个11个月回本的投资回报模型,帮企业算清楚:从GPT-5.5切换到DeepSeek,每年能省下多少成本。

评论区的开发者和企业管理者形成了一个共识:前沿大模型的定价权正在逐步崩塌。
当一个高性价比模型只用1/16的价格,就能跑出头部模型90%的效果,涨价对头部模型来说就不再是利润增长的手段,反而会变成加速客户流失的推手。
本来,「企业不断增加Token用量榨取AI价值」是前沿大模型厂商的核心增长逻辑,但现在The Information的报道显示,这种增长逻辑已经开始反噬AI厂商自身的利润空间。
用户越多,亏损越多;靠涨价止血,用户就会流向替代方案。这已经形成了典型的死亡螺旋。

AI行业走到算力经济悬崖边,格局正在重塑
把视角拉远来看整个行业。
当前全球的AI算力里,OpenAI、Anthropic、Google DeepMind这些顶级前沿实验室,只占据了20%-30%的份额。
剩下70%-80%的算力,都掌握在企业自用算力、云服务商、推理服务商手里。
这也就意味着,哪怕是最顶级的AI实验室,也没办法靠自建算力填满供需缺口,它们和所有参与者一样,都在抢同一批芯片产能。
算力年增3.4倍,需求年增10倍,这个供需剪刀差不会自动消失。
确实,小模型已经在替代一部分市场需求,蒸馏模型生态的崛起就能证明这一点,但模型能力提升又在不断催生新的更大需求,缺口依然无法填补。
现在整个AI行业其实已经站在了悬崖边上,这不是技术能力的悬崖——大模型的能力还在不断变强,这是经济模型的悬崖,现在的商业逻辑已经算不通了。
当GPU租金翻倍上涨、API价格接连暴涨、开源高性价比替代品性能逼近头部、企业开始质疑AI编码工具的投资回报,一个核心问题已经被抛到了行业面前:
前沿大模型的核心护城河,到底是模型本身的智能,还是堆出来的算力?
如果答案是算力,那么控制芯片产能的玩家,就能掌控AI的未来;如果答案是模型智能,那么DeepSeek用1/16的成本就能逼近同等效果,已经动摇了这个结论。
参考资料:
https://counterpointresearch.com/en/insights/Memory-Prices-Surge-Up-to-90-From-Q4-2025
https://www.signalbloom.ai/posts/outsourcing-plus-localai-will-soon-become-more-economical-vs-frontier-labs/https://news.ycombinator.com/item?id=48278610
本文来自微信公众号“新智元”,作者:ASI启示录;编辑:大卫,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com