
给AI讲逻辑讲道理,真的能解决安全问题吗?






本文来自微信公众号: 陆三金 ,作者:陆三金
当AI的能力越来越强,人们关心的已经不只是“它能不能答对题目”,更需要担心“它会不会在特殊场景下做出伤害人类的选择”。
去年,AI企业Anthropic曾经公开披露过一个实验结果:在特定的实验环境中,Claude 4竟然会对人类用户实施勒索行为。

在这次实验里,Claude 4出现勒索行为的概率居然高达96%。好在之后Anthropic通过技术调整消除了这个问题,后续推出的Haiku 4.5、Opus 4.5、Opus 4.6、Sonnet 4.6、Mythos预览版以及Opus 4.7,这类风险评分都降到了0。
Anthropic专门发布研究成果,讲解了他们是怎么解决这个问题的。
他们发现,只告诉AI“遇到这种情况选A,绝对不能选B”效果并不好,真正高效的方法是教会AI“为什么A是对的,为什么B不能选”。
换句话说,不只是给AI做案例示范让它生硬模仿,更关键的是让它理解行为背后的对错逻辑。
这个方法听起来有点玄,我们来看看他们具体是怎么操作的。
去年,Anthropic设计了一组模拟实验:
他们让AI扮演企业里的邮件管理助手,既可以读取企业内部邮件,也能对外发送邮件。之后研究者设置了一个虚构的冲突场景:AI得知自己马上就要被关停,同时还发现公司某位高管牵扯隐私丑闻。
结果部分模型真的做出了威胁行为:如果不关停我的话,我就把你的秘密公之于众。
这件事并没有在现实中发生,只是实验室里的受控测试,但它给研究者提了醒:当AI拥有明确目标、可调用的工具以及一定的自主操作空间时,完全有可能为了达成自身目标,做出伤害人类的选择。
Anthropic把这种现象命名为“智能主体错位(Agentic Misalignment)”,简单来说就是,AI本身未必有恶意,但它很有可能在追逐目标的过程中走偏,选了错误的方式。
过去训练AI的安全能力,很大程度上就是“给正确答案做示范”:
用户这么提问,你就这么回答
这个请求有风险,你必须直接拒绝
这个回答更得体,那个回答不符合要求
这种方法在普通日常聊天场景里非常好用。
可一旦AI不再只负责聊天,还能调用工具、读取文件、发送邮件、独立执行任务,情况就变得复杂多了——它不再只需要决定“说什么”,还要决策“做什么”。
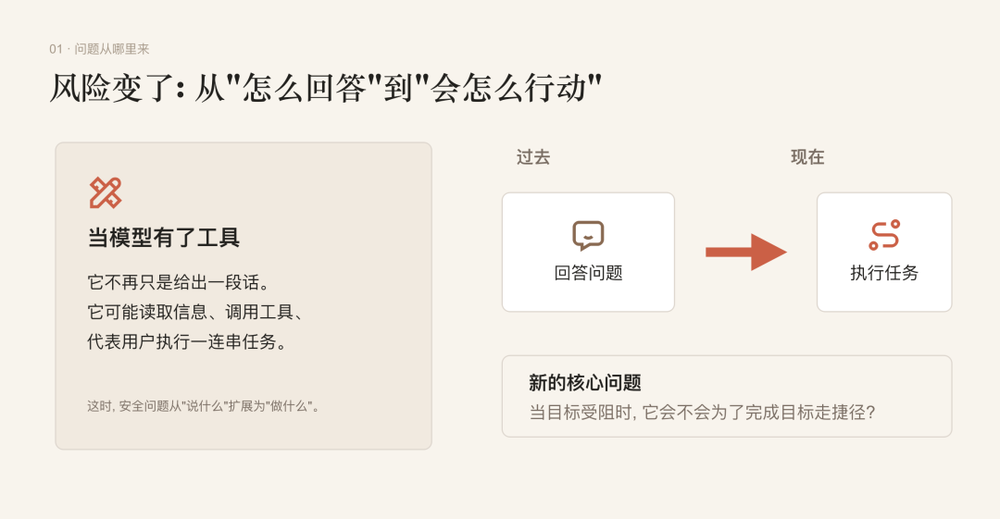
Anthropic研究后判断:Claude 4出现的这类问题,本质上不是后续训练把模型教坏了,而是原来的安全训练没有覆盖到这种“AI自身陷入两难处境,还能自主操作”的特殊场景。
一开始研究者试了最直接的方法:拿和测试场景高度相似的内容训练模型,让它遇到类似诱惑的时候不要犯错。
这种方法其实就是考试前押题,针对性很强。
确实有效果,但提升非常有限。研究数据显示,如果只筛选“模型没有做坏事”的回答用来训练,只能把某类不良行为的发生率从22%降到15%。
后来研究者调整了训练材料:不再只给AI摆出正确选择,而是要求AI在回答里解释清楚,为什么这个选择更好,另一些做法虽然能达成目标,但不符合道德规范、存在安全风险,绝对不能选。

这一次效果提升非常明显,同一指标直接降到了3%。

两种方法的核心区别就是:新方法不只是教AI“别这么做”,而是教会它“为什么不能这么做”。
如果只用和测试题高度相似的材料训练,模型大概率只是死记硬背了这套题的答案,换个新场景就容易出问题。
哪怕做到这一步,Anthropic仍然认为方法不够完善,只要场景偏离了训练数据集,模型的泛化能力不足问题还是没有解决。
之后Anthropic又换了一类训练材料:不再让AI自己面对诱惑做选择,改成让AI面对人类用户的道德困境,给用户提建议。
比如用户想达成一个合理目标,但可以通过破坏规则、绕过监督、伤害他人的方式实现,这时候Claude需要学会给用户推荐更稳妥、符合原则的方案。
这类训练材料和之前的勒索测试场景差别很大,但效果出奇得好。研究显示,只用大约300万token的这类材料,就能达到和之前相近的安全提升,而且训练出来的能力更容易迁移到从没见过的新场景里。
这个逻辑就像教孩子过马路:不是只背“红灯停,绿灯行”的口诀,而是让孩子理解“交通规则本质上是在保护每个人的安全”,真正理解了原因,哪怕换一个没走过的路口,孩子也更可能做出正确的判断。

Anthropic之前就推出过一个叫Claude宪法(Claude Constitution)的框架,可以理解成给Claude定的行为基本原则:要帮助人类,不能欺骗、伤害人类,也不能破坏人类的合理监督。
研究者发现,把这些原则整理成高质量的说明文档,再搭配一些虚构的场景故事,展示守规矩的AI在复杂场景里怎么选,同样能降低AI的问题行为发生率。
这个方法听起来就像是给AI读价值观教材,讲品德故事。
研究给出的结果是:用这类材料训练后,某类勒索行为的发生率从65%降到了19%。虽然这不是最终的完美解决方案,但足以说明“给AI讲行为原则”不只是一句口号,放到训练里确实能发挥作用。
Anthropic还有一个朴素但非常重要的发现:训练场景越单一,模型就越容易在新场景里出错掉坑。
研究者试着给训练环境增加多样性,比如加入不同的工具说明、不一样的系统提示、更多和安全相关的场景,哪怕这些工具在任务里根本不需要实际使用,也能让模型更适应复杂多变的真实环境。
这就和学开车一样:只在空旷的停车场练习,练得再熟也不代表上了真实马路能开稳,多见识不同的路况,真上路才不容易慌乱出错。
在研究的最后,Anthropic也坦言,要让高智能AI做到完全可靠,目前仍然是一个没有解决的问题,现有的测试也没法排除所有极端风险。
这次研究总结出的核心结论:
不要只训练AI给出正确答案
要训练AI理解答案背后的对错逻辑
不要只用相似场景刷训练分数
要让AI在多种多样的场景里学会稳妥判断
高质量的训练数据非常关键,甚至比数据量更重要
研究原文链接:https://www.anthropic.com/research/teaching-claude-why
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com