
DeepSeek-V4发布:普通人需了解的六件关键事





本文来自微信公众号:快刀青衣,作者:快刀青衣
百万上下文,从「顶级配置」变为「日常基础服务」。
2026年4月24日,一个普通的周五,DeepSeek终于推出了V4版本。
没有盛大的发布会,没有多人直播,没有倒计时预热,也未接受任何媒体采访。官网悄然更新,App低调上线,API同步升级,开源模型直接上传至HuggingFace。唯一的宣传,仅是发布了一篇公众号文章。
过去半年,关于DeepSeek-V4跳票的传言、「DeepSeek是否已被超越」的讨论、「梁文锋究竟在做什么」的质疑,在中英文AI圈反复流传。他们从未回应,直到这个周五正式发布。
先说说能力表现。官方文章中展示了一张全球顶级AI大模型的多维度能力对比图,从七个维度将DeepSeek与当前最顶尖的三个大模型高阶版本进行对比,这三个模型分别是Claude Opus 4.6、GPT-5.4和Gemini 3.1 Pro。
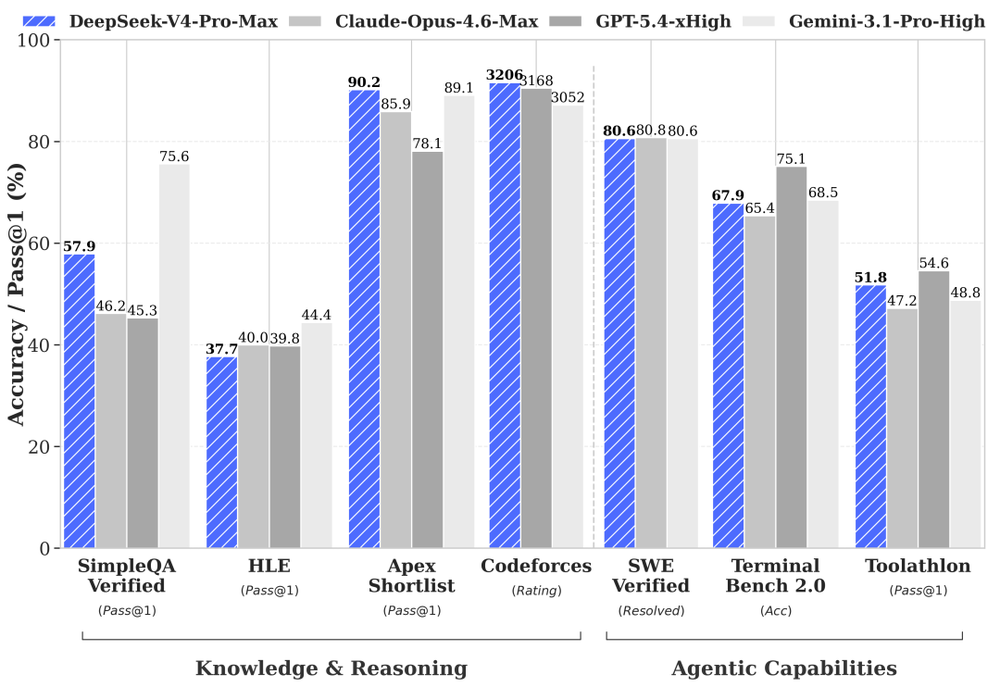
这三个模型是全球闭源模型中的佼佼者,月订阅费用最低20美金,最高达200美金。而DeepSeek作为开源免费产品,若与其他开源产品或这三家的免费版本对比,本也合理。
但从敢于对比的勇气来看,就值得称赞。这好比足球界直接将竞争对手锁定为巴西、阿根廷。
当然,成绩也十分亮眼。评测涵盖七个方面,第一模块是知识与推理,第二模块是智能体能力。就像学生的七门学科,DeepSeek取得了2个第一、3个第二、1个第三和1个第四。
作为中国的免费开源模型,这样的成绩已相当出色,能与顶级高手不相上下。官方发布的公众号文章,没有太多官话套话,全是技术参数和调用方法。
不过,官方文章结尾引用的荀子名言吸引了我:
❝
不诱于誉,不恐于诽,率道而行,端然正己。
这句话的意思是,君子不应被赞誉诱惑,不被诽谤吓倒,坚持自己认定的道路,端正自身。这是战国时期荀子在《非十二子》中提出的,后来成为君子人格的标准定义,主张向内追求。
说实话,若放在其他公司身上,我会觉得有些刻意。但用在DeepSeek上,却觉得很贴切。
接下来,这个模型是否真的强大,还会有更多评测。大模型的竞争是长期的,了解背后的故事比关注简单参数更有意义。
今天,我想带大家看看这次发布背后真正重要的六件事。
01 迟到15个月,是另一场硬仗
很多人认为DeepSeek-V4跳票是因为研发遇瓶颈,模型做不出来。事实并非如此。
V4延迟发布的真正原因,是DeepSeek做出了一个艰难决定:将整个底层架构从英伟达的CUDA生态迁移到华为的昇腾芯片上。
全球绝大多数AI模型的训练都依赖英伟达芯片,而CUDA是其配套的开发环境,如同专用操作系统。过去十几年,整个AI行业在这套系统上积累了大量代码、工具和生态,形成了难以绕开的护城河。
这才是英伟达真正的壁垒,不只是芯片本身。
DeepSeek决定绕开它,并非易事。据业内人士透露,2025年年中,DeepSeek在使用华为昇腾芯片训练V4时,遭遇了训练中途崩溃、稳定性不足、芯片间通信速度未达预期等一系列问题。
他们没有放弃,不断优化。最终结果是:DeepSeek-V4在华为昇腾950PR上的推理速度,较迁移初期提升了35倍。
英伟达CEO黄仁勋在一档播客中表示,如果DeepSeek在华为芯片上首发,对美国而言将是“a horrible outcome”(可怕的结果)。能让经历过大风大浪的黄仁勋说出这样的话,足见这次迁移的重要性。
如今,DeepSeek已实现这一突破。对黄仁勋和英伟达来说,他们担心的并非某款芯片的销量,毕竟这在英伟达的AI基建帝国中占比不高。
但这一突破的关键价值在于,“开源模型必须以英伟达芯片为基建”的行业铁律被打破了。我认为这就是V4迟到15个月的最大原因。
02 那次“没什么亮点”的更新,是地基
如果你一直在使用DeepSeek或关注其进展,可能记得2025年下半年的DeepSeek-V3.2-Exp更新。当时外界反应冷淡,跑分与上一版本几乎无变化,很多人觉得DeepSeek在原地踏步。
但那次更新悄悄引入了DSA(DeepSeek Sparse Attention,稀疏注意力机制)。当时无人特别关注,因为技术细节枯燥,跑分也无显著提升,只有少数技术文章提及。
而这次DeepSeek-V4官方公告中提到的“全新注意力机制、在token维度压缩、大幅降低计算和显存需求”,DSA正是核心组成部分。也就是说,那次被忽视的更新,其实是V4的基础工程。
你看,很多重要动作在发生时并不显眼。我们容易盯着跑分榜单焦虑,却没注意到人家在打基础。
03 百万上下文,从“顶级配置”变“水电煤”
此前,量产可用的百万token上下文还是谷歌Gemini的独家优势。其他主流模型大多支持12万到20万token。
DeepSeek这次直接宣布:从即日起,百万上下文是所有官方服务的标配。不是只有旗舰版才有,而是所有版本都具备,且开源。
一百万token是什么概念?《三体》三部曲约百万字,你可以将整套书输入,询问任何问题。或者,把几百页的合同、财务报告、法律文件传进去,让它帮忙找关键条款、总结核心内容。以前需要几小时,现在只需几秒。
更重要的是,这背后有一个规律:AI行业每隔一段时间,就会有一项“只有顶级产品才有的能力”,突然成为人人可用的标配。
两年前是联网搜索,一年前是图片理解,现在是百万上下文。现在顶级模型的付费功能,到明年普通人大概率都能用上。
04 写代码,已跻身世界第一梯队
官方文章提到:目前DeepSeek-V4已成为公司内部员工使用的Agentic Coding模型,使用体验优于Claude Sonnet 4.5,交付质量接近Claude Opus 4.6非思考模式。
别小看“接近”这个词,因为Claude在写代码方面一直遥遥领先,连谷歌和OpenAI内部都有人偷偷用它写代码。所以DeepSeek能接近行业顶级水平,本身就是一大进步。
第三方数据也能印证这一点。在竞技编程测评Codeforces上,DeepSeek-V4得分超过GPT-5.4;在软件工程测试SWE-Verified上,与Claude Opus 4.6几乎持平。
这两项测评是业内公认最能反映模型真实代码能力的标准之一。
这对普通人有什么意义?我认为有三个实用场景:
做小工具
最直接的应用。比如自动整理Excel、定时发邮件、制作简单个人主页。以前要么自己学编程,要么花钱找人写。现在你可以直接发指令,让DeepSeek尝试编写。
不过别指望一次就满意,多半要反复修改,但这个过程能让你了解它的能力边界。
解决报错
很多人遇到代码报错就慌。其实报错说明问题可解决。把报错信息复制进去,AI会告诉你哪里出错、如何修改,无需懂代码逻辑。
开发者直接替换
如果你是开发者,市面上主流Agent工具如Claude Code、OpenClaw、OpenCode、CodeBuddy等,DeepSeek-V4都做了专项适配和优化,可直接替换使用。
05 为何免费?靠什么生存?
结论是:普通用户在网页端或App端日常使用完全免费,且短期内大概率继续免费。
原因在于DeepSeek背后的“金主”幻方量化,是中国头部量化对冲基金之一,提供了充足的资金和算力支持。对现在的DeepSeek来说,让更多人使用、做大生态,比向普通用户收月租更重要。
真正的盈利方式是B端,向需要大规模调用AI的企业收取API费用。例如,各类软件企业要将AI能力嵌入产品,需付费调用DeepSeek的商用接口。据了解,DeepSeek-V4-Pro的调用成本约为Claude Opus 4.6的七分之一、GPT-5.4的四分之一。
对企业而言,用几分之一的价格获得接近顶级的性能,这笔账很划算。不过由于版本刚发布,我们Get笔记尚未使用,等完成场景实测后会再分享信息。
06 DeepSeek开始大量招聘文科生
这个细节是我在资料中发现的,很有意思。
过去一年,北大学生发现DeepSeek的HR频繁出现在中文系宿舍楼,专门招聘中文系学生,用于人文领域的数据标注。
简单说,就是给AI提供“正确答案”。比如让AI读古诗,判断情绪是悲伤还是旷达;看散文,分辨哪些表达有文采、哪些平淡。这些判断机器无法完成,需要懂文学、有语感的人来做。
DeepSeek以前是出了名的“理科做题机器”,数学、代码、逻辑推理都很强;但涉及情感表达、有温度的文字时,总差一点。现在它开始弥补这块短板。
这背后有个更大的信号:AI竞争正从“谁更聪明”转向“谁更像人”。
推理、数学、代码能力可通过算力和数据堆砌,各家差距逐渐缩小。但情商、语言质感、对人类情感的理解,更难复制和追赶。
而且招聘中文系学生,说明DeepSeek仍扎根国内市场,后续在中文深度理解、本土化创作等方面的表现值得期待。
最后,回到荀子的那句话
过去半年,DeepSeek不仅面临外部质疑,内部也不平静:R1核心作者被字节挖走,LLM核心作者被腾讯挖走,V2核心作者被小米以千万年薪挖走。同时,公司核心员工期权未市场化定价,留人越来越难。
可见,他们并非一帆风顺。有技术攻坚的煎熬,有人才流失的压力,有外界“是不是凉了”的质疑,还有长期未回应的舆论真空。
然后在这个周五,他们默默推出了最新的V4模型。不是“因为厉害所以淡定”,而是“选择先做,再说话”。
说实话,这种风格在如今的AI圈很罕见。大多数公司的发布节奏是:先开发布会造势,再讲故事融资,然后慢慢交付产品。DeepSeek则相反,先做出产品,开源、上线,再发布公告,仅此而已。
我不知道DeepSeek最终会走向何方。它还面临很多问题:世界知识储备仍逊于Gemini,超长文本细粒度检索并非最强,核心人才流失后能否保持“不急不躁”的研发文化也是未知数。
但至少到今天,它做到了荀子所说的那句话。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com