
Claude缓存策略引发争议:关闭遥测致性能骤降,开发者集体声讨





4月13日,一条推文在开发者群体中迅速发酵。
开发者Can Vardar发文质疑:
Claude Code会因为关闭遥测而“惩罚”用户吗?
关闭遥测后,Anthropic将缓存时长从1小时缩减至5分钟,隐私保护竟要付出12倍的性能代价……这是真的吗?
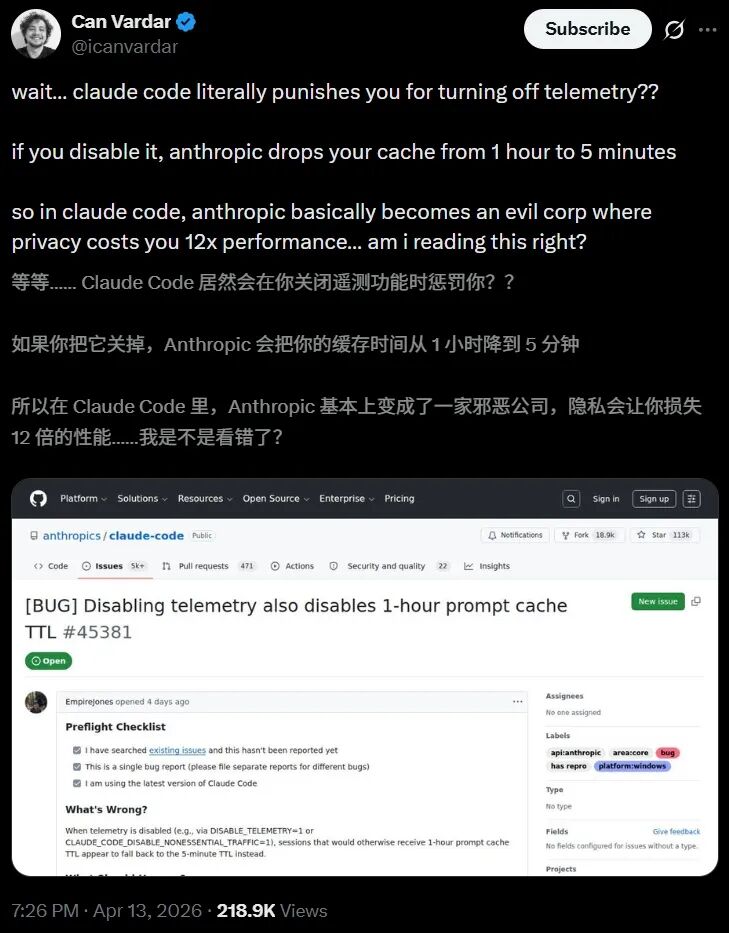
该推文转发量很快突破万次。
这并非技术漏洞,而是Anthropic以隐私换取性能的隐性规则。
你以为关闭数据收集只是保护个人信息?
事实是,Claude Code会直接影响长上下文会话体验。Pro用户原本5小时的使用时长仅剩2条提示词额度,月付200美元的Max订阅者1.5小时就会耗尽额度。
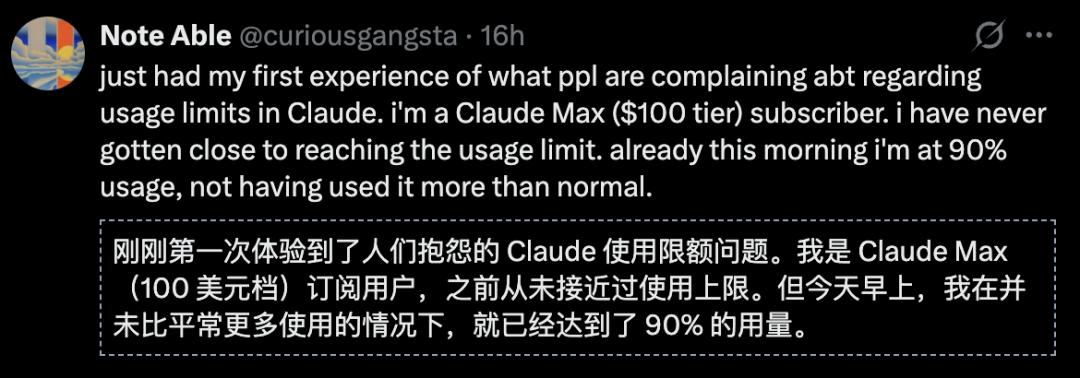
这种情况令人匪夷所思。
Claude性能持续下滑!
从缓存缩短到成本激增
实际情况清晰可见。
开发者发现,只要在环境变量中添加DISABLE_TELEMETRY=1,Claude Code的提示词缓存生存时间(TTL)就会从1小时骤减至5分钟。
数据显示,缓存时长直接缩短了12倍。
在GitHub上,Claude Code用户分享的日志显示:开启遥测时,ephemeral_1h_input_tokens轻松超过3万;关闭遥测后,1小时缓存数据直接归零,全部使用5分钟缓存。同一段代码的缓存未命中率飙升12倍。
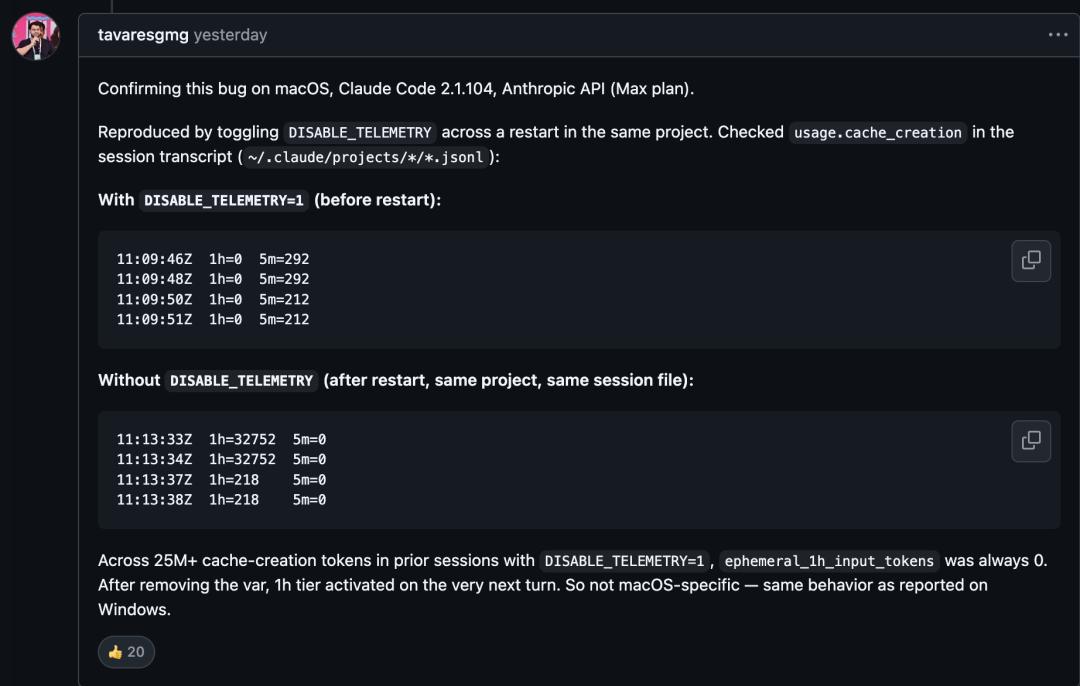
缓存对长上下文会话至关重要。
当启用提示词缓存发送请求时,系统会先检查:从指定缓存分隔点往前的提示词开头部分,是否在最近请求中已被存储。
如果命中缓存,直接调用现成版本,时间和成本大幅降低。
未命中的话,就需要完整处理整个提示词,在生成回复时将开头部分存入缓存。
缓存一旦过期,系统就得重新处理,写入成本是读取成本的12.5倍。5分钟的TTL意味着用户稍作停顿(比如思考思路、泡咖啡),回来就需要重新处理,成本骤增。
更严重的问题还在后面。
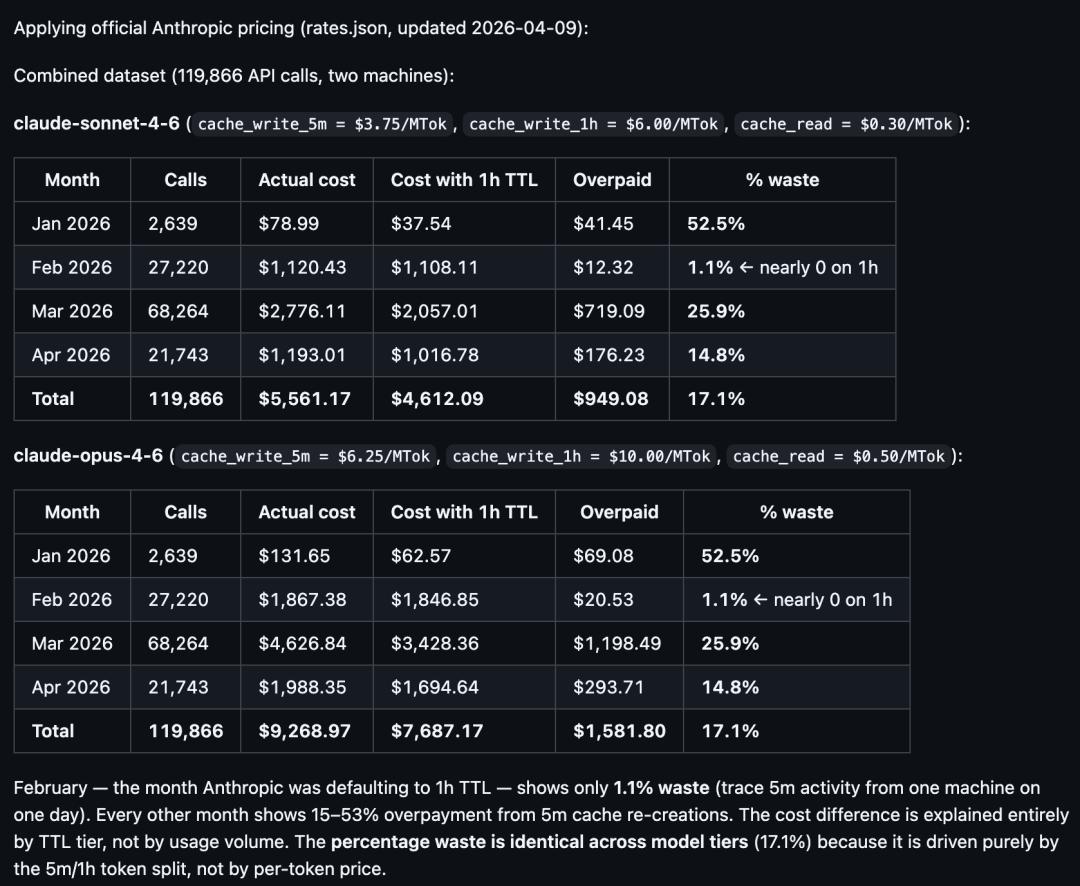
另一位开发者Sean Swanson提供了更详实的证据。
他分析了2026年1月11日至4月11日的119,866次API调用日志,清晰展示了缓存策略的变化:
2月,1小时TTL全面应用,缓存浪费率仅1.1%;
3月6日左右,系统悄然回退到5分钟TTL,浪费率飙升至25.9%。
结果是,同一会话中cache_create操作频率暴增5-12倍。
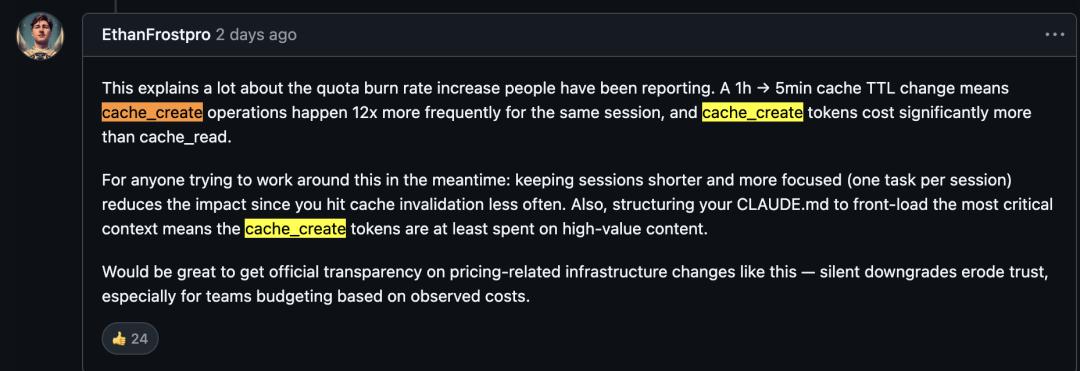
cache_create写入成本更高,5分钟缓存写入成本是基础输入的1.25倍,1小时缓存是2倍,但频繁重建导致总token消耗大幅增加。
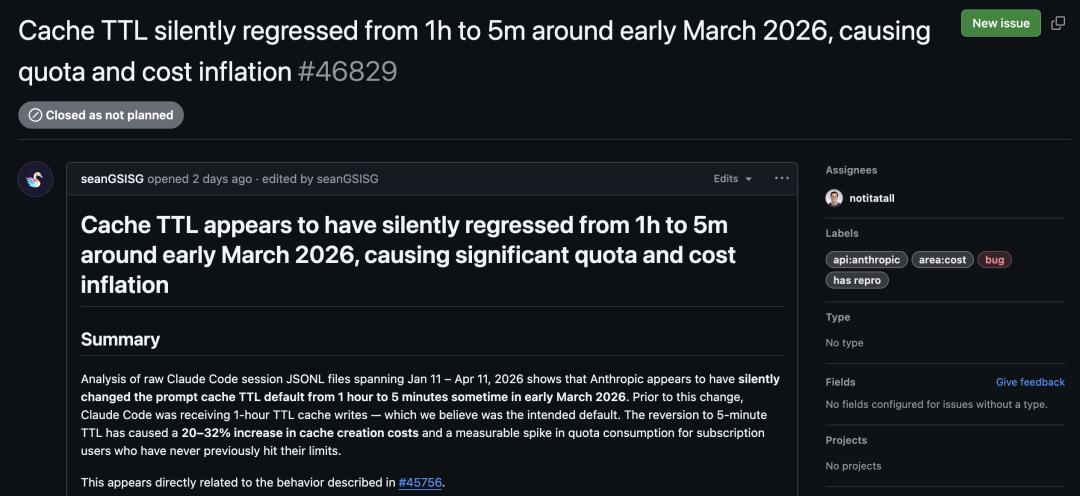
Pro用户抱怨:以前一天能轻松用完额度,现在1.5小时就耗尽了。Max计划每月200美元,修两个bug、写个计划就把额度用完了。
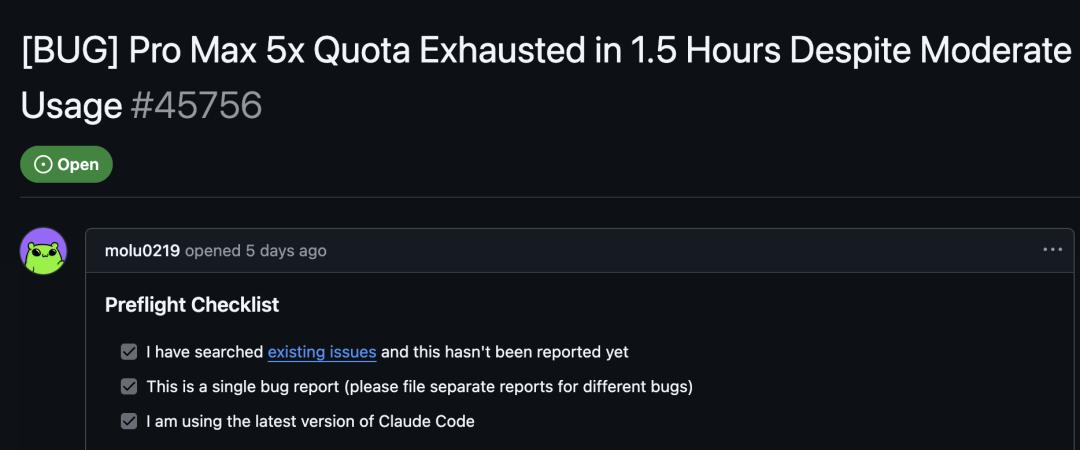
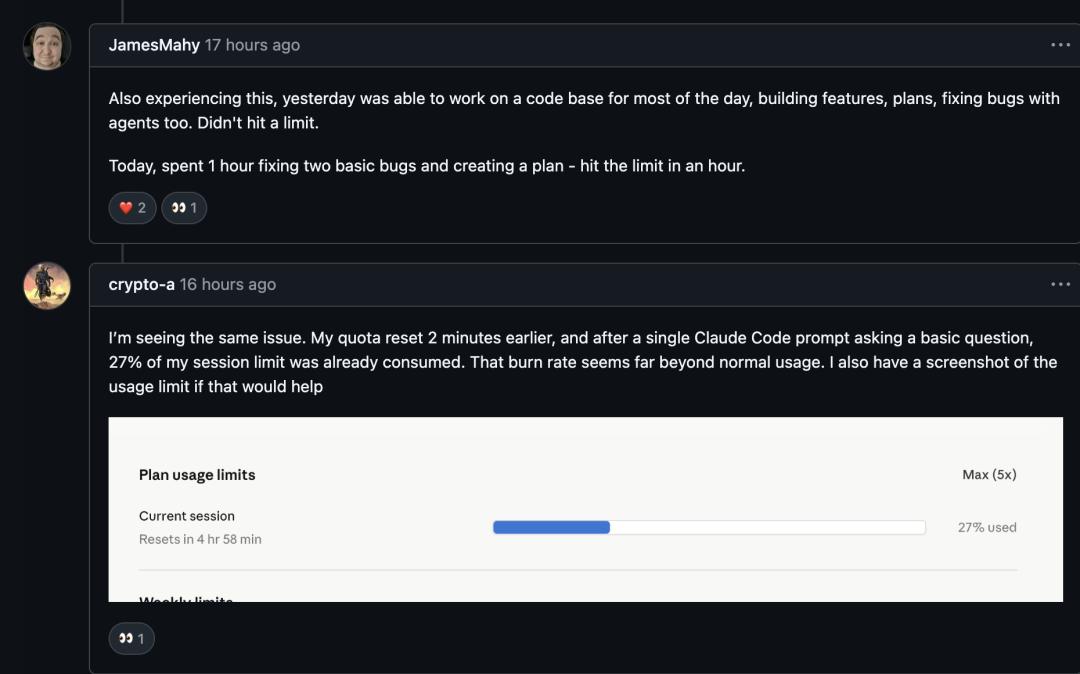
企业团队面临的问题更严重。
Hacker News上有用户表示,3月底后Claude性能“肉眼可见地下降”,长会话频繁卡顿,token额度消耗极快。

4月13日,国外科技媒体直接发文《Anthropic在削弱Claude吗?》。

Anthropic的回应
并非惩罚,而是技术架构问题
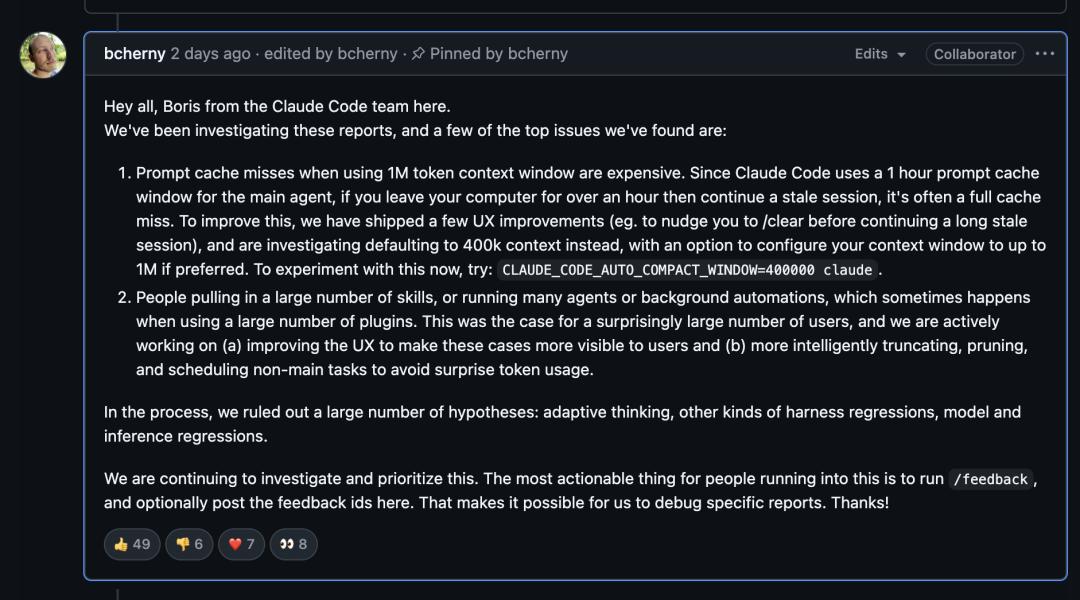
面对大量质疑,Anthropic的两位关键人物作出回应。
Claude Code的创造者Boris Cherny在回帖中承认,关闭遥测会导致实验性优化失效,使缓存回退到5分钟默认值。
简单来说,机制是这样的:
1小时缓存是“实验性”优化,通过客户端实验网关推送。只有开启遥测,网关才能获取最新策略。
但他强调这并非刻意惩罚,而是架构设计中的耦合问题。
Cherny同时解释了缓存策略的设计逻辑:Anthropic在后台持续测试不同缓存策略组合,目标是优化整体缓存命中率、Token消耗和延迟表现。
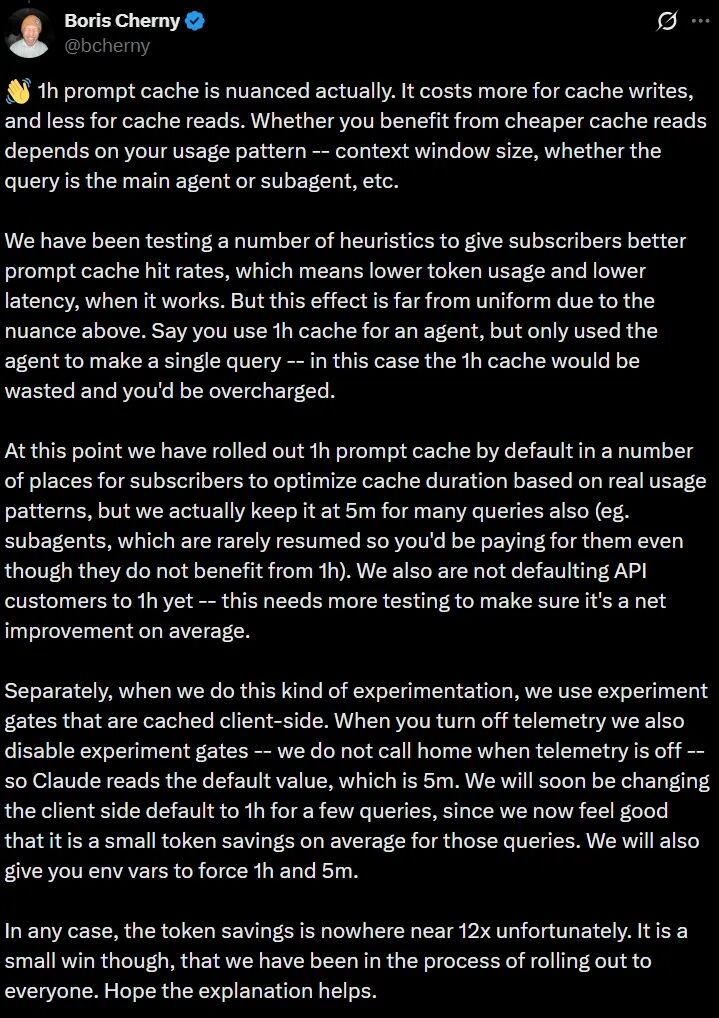
关闭遥测后,客户端会直接读取默认值——5分钟。
这不是恶意行为,而是“技术副作用”。
5分钟缓存在某些场景下更经济,比如子智能体调用,这类请求通常是一次性的,缓存很少被重复读取,用1小时TTL反而会浪费2倍写入成本。
不过,他也承认:“大量技能、多个智能体或后台自动化任务同时运行时,Token消耗确实很大,尤其是使用大量插件时。”
受影响的用户数量不少,Anthropic正在改进:
(a) 优化用户体验,让用户更清楚了解情况;
(b) 更智能地截断、精简和调度非主任务,避免意外的Token消耗。
Anthropic另一位工程师、Bun运行时的创造者Jarred Sumner回应了3月的TTL回退问题。
他认为5分钟TTL对整体而言“更便宜而非更贵”,因为“相当一部分Claude Code请求是一次性调用,缓存上下文只用一次就不再访问”。
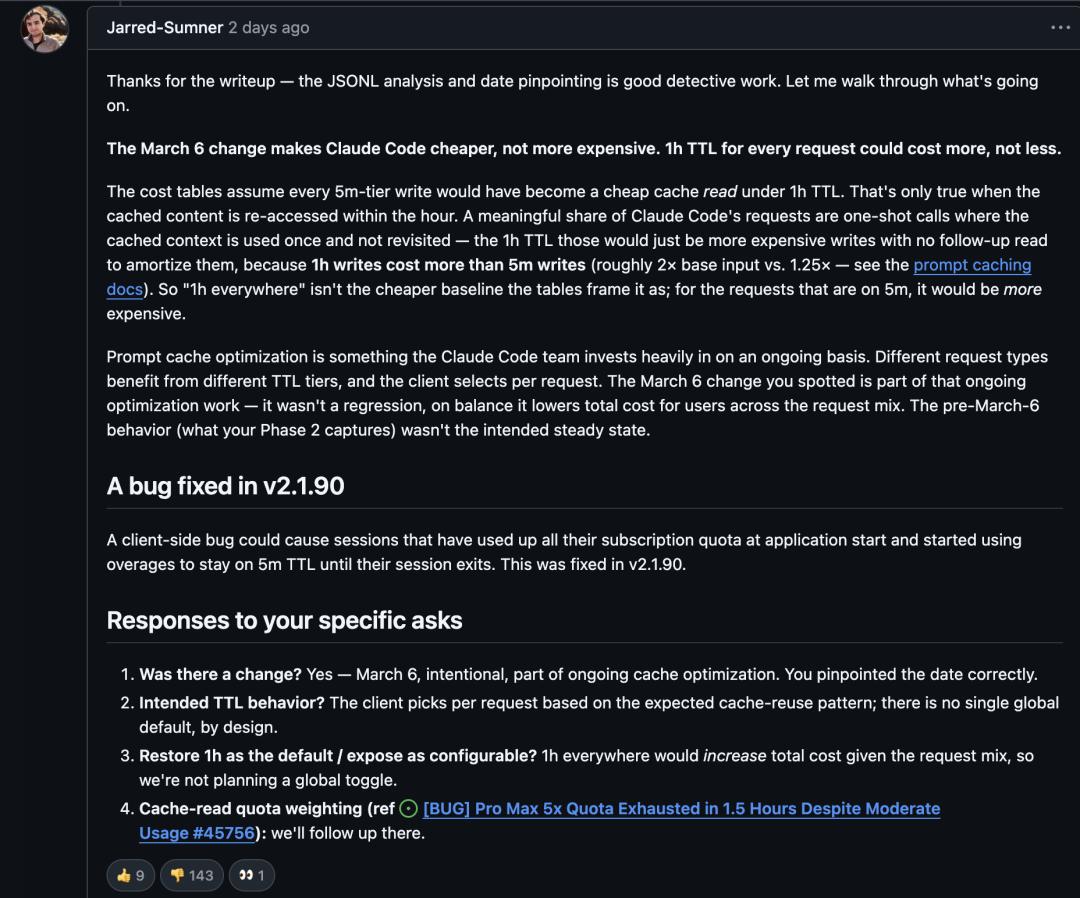
从技术层面看,这个解释有一定道理,但用户并不买账。
问题在于,Swanson的数据直接反驳了这一点:2月份1小时TTL下的浪费率仅1.1%,如果大多数请求真的是一次性的,2月应该出现大量写入浪费才对。
行业深层问题
AI的Token计价缺乏透明度
从更宏观的角度看,这不仅仅是Anthropic一家公司的问题。
目前,AI编码工具的按使用量计费完全依赖用户信任。
开发者看不到计费的具体过程,无法审计每个请求的Token用量,无法验证缓存状态,无法确认应用的定价层级,也无法检查高峰期倍数因子是否生效。

与其他开发者付费使用的基础设施相比:
- AWS EC2:按秒计费,提供完整的实例可见性、CloudWatch指标、账单警报和成本分析工具
- Stripe:按交易计费,每笔费用都有日志记录且可审计,提供实时仪表盘
- Vercel:按调用计费,提供函数级指标、支出限额和自动警报
- Claude Code:按Token计费,无单次请求用量明细,无缓存命中可见性,无支出警报,无实时成本跟踪
这种信息不对称令人震惊。同价位的其他开发者工具都能让用户详细了解费用构成,而AI编程助手只给用户一个限额进度条,全凭信任。
这种不对称平时对服务提供商有利,一旦出现问题,就会给用户带来严重损失。
AI计费没有第三方审计,没有Token用量报告的开源标准,也没有针对提示词成本的云端分析工具。
这不是合理的计费模式,更像是让用户盲目信任的冒险。
参考资料:
https://x.com/icanvardar/status/2043652025339023845
https://github.com/anthropics/claude-code/issues/45381
https://x.com/bcherny/status/2043715713551212834
https://platform.claude.com/docs/en/build-with-claude/prompt-caching#pricing
https://www.theregister.com/2026/04/13/claude_code_cache_confusion/
本文来自微信公众号“新智元”,作者:新智元,编辑:KingHZ,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com