
GEN-1爆火背后:具身智能竞争核心转向基础设施






日前,Generalist AI推出的GEN-1模型在具身智能领域引发热议,其CEO Pete Florence甚至断言机器人技术正临近「ChatGPT时刻」。
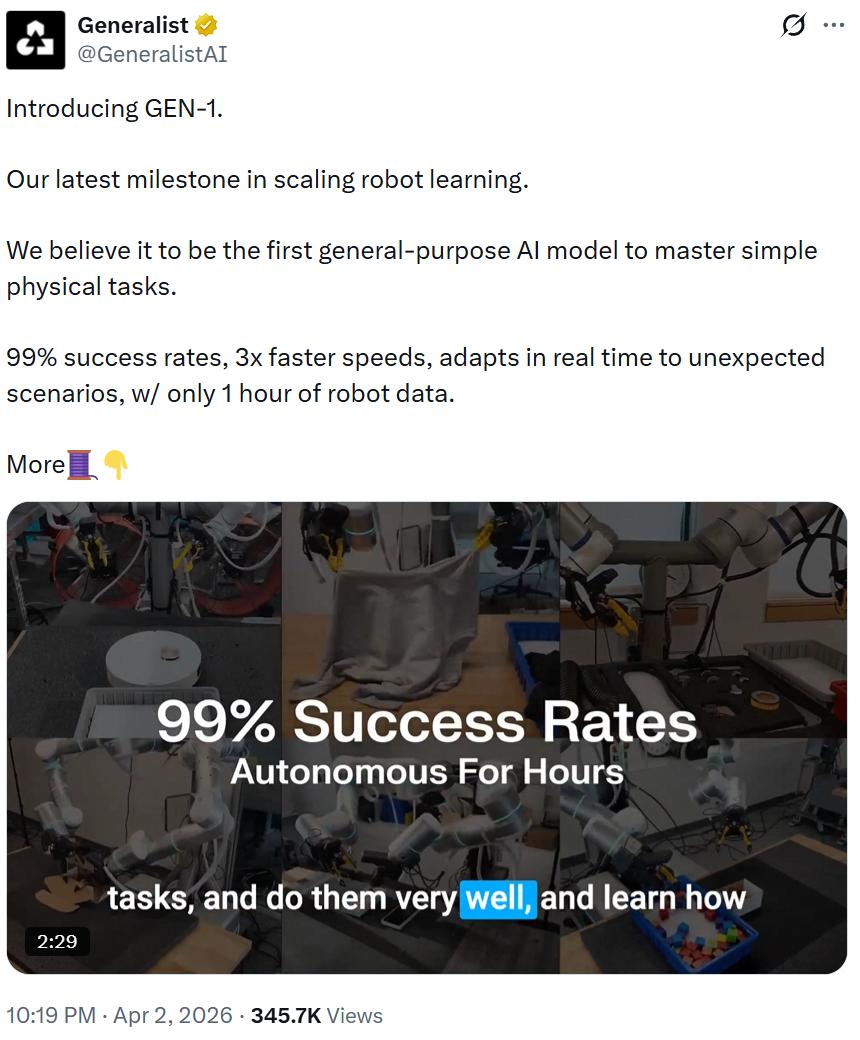
据官方介绍,GEN-1在多任务中成功率达99%,执行速度提升3倍,还具备强大的意外恢复能力。这些亮眼数据背后,是具身基础模型首次触及关键门槛——从「能演示」阶段稳步迈向「可部署」的商业化阶段。
这不禁让人好奇:新一代物理AI模型究竟如何训练而成?
业内消息显示,此次能力跃迁的底层支撑是全新的数据与仿真基础设施体系,光轮智能作为关键参与者发挥了重要作用。
GEN-1的出现标志着:具身智能的竞争阵地正从模型层转向背后的基础设施层。
光轮智能CEO谢晨在访谈中透露行业动态:「今年头部大厂已全力布局机器人VLA,字节、阿里等国内企业,以及OpenAI、DeepMind、英伟达等海外巨头,推进速度都非常激进。」巨头加速入局,将竞争焦点推向支撑模型快速迭代的基础架构层。
不止模型升级,竞争重心转移
分析GEN-1的影响需跳出版本升级思维,其深层意义在于:首次将具身基础模型从「证明机器能学」的验证期,推向「接近可部署」的商业化门槛。
其中三大突破尤为关键:超高成功率、快速执行能力、意外情况自我恢复能力。
这意味着行业关注焦点已转变:从业者更关心模型执行是否稳定、动作是否敏捷、面对现实偏差时是否具备鲁棒性。
逻辑推演可知,模型跨越初始可用性门槛后,行业突出矛盾将转化为如何让模型持续稳定变强。此时核心问题变为:能否获取更大规模、更高质量、更多样的数据?能否可靠判断模型是否进步?能否在更广场景、更复杂任务中暴露失败模式?能否形成「发现问题→补充数据→训练→验证」的反馈闭环?
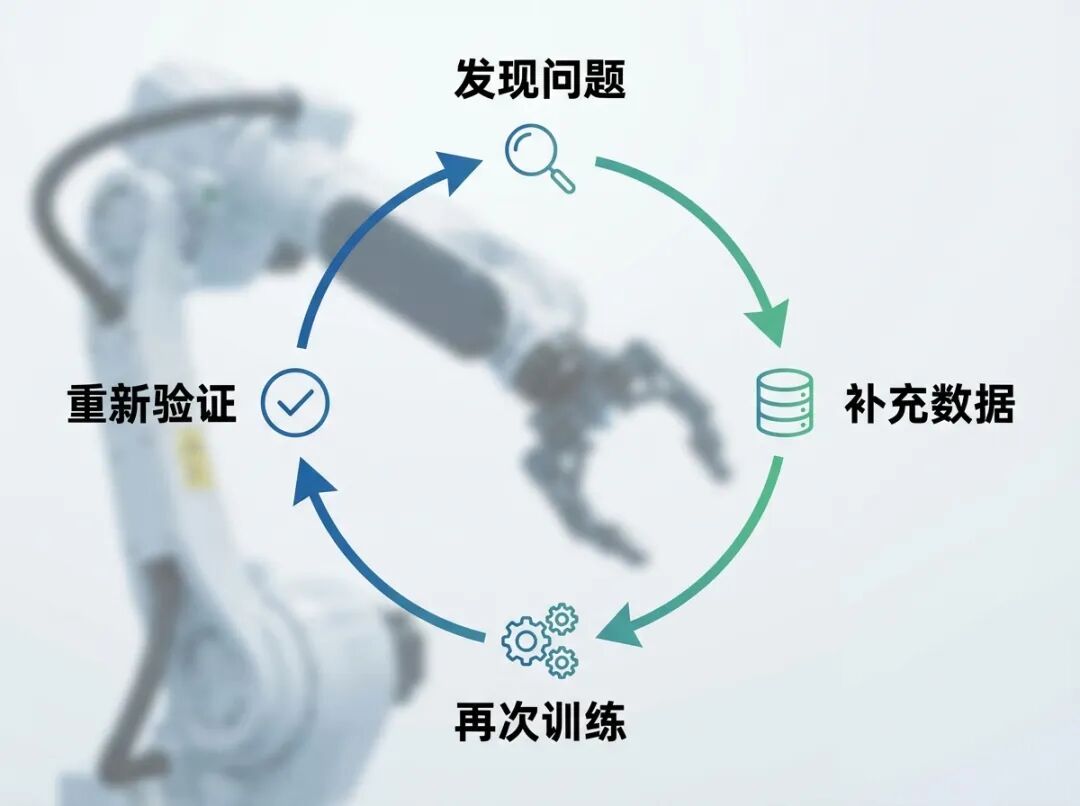
由此可明确判断:行业真正稀缺的资源已超越更强模型本身,支撑模型持续进化的基础设施能力成为制胜关键。具身智能竞争正全面向上游溯源,基础设施层成核心战场。
这些判断在张小珺对谢晨的访谈《机器人数据的综述:新时代的石油》中得到印证,谢晨还分享了更多具身智能数据基础设施的洞见。
模型能力跃迁后,追问能力来源
GEN-1展示了能力形态的显著变化,而张小珺与谢晨的深度对话为理解这种变化提供了关键视角。
访谈中,谢晨提出深刻类比:「从第一性原理看,数据与模型的关系类似教育与人类学习。」这表明数据已超越样本集合属性,成为学习信号、经验传递途径和能力塑造方式。

以此框架审视具身智能前沿,会发现前沿模型的成功难以简单归结为数据量堆砌,核心在于:具身智能首次形成真正的学习系统。
在这个系统中,数据采集、行为保留、失败强化、能力优化不再是随机孤立事件,而是被高度系统性构建。
这揭示了深层产业演进:数据正从「静态数据集」加速变为「动态教育系统」。
谢晨清晰梳理了这一过程:从机器视觉时代填鸭式的静态数据集,到工业化大规模数据生产,再到大模型时代的反馈驱动。他总结:「数据应被定义为帮助模型学习的信号及相应经验。」
这种演进本质是数据向「针对性指导」发展。传统机器人训练追求完美轨迹,但当前具身模型训练中,严格完美不再绝对。
谢晨分享服务客户的实践经验时提到反直觉认知:「最有效的数据是先失败再成功的数据。」在他看来,完美视频未必最有价值,包含纠错过程的负样本能赋予模型在非结构化环境中随机应变的能力。
在这个新阶段,行业涌现出超越单纯数据提供、致力于构造学习过程的全新能力体系,光轮智能就是其中关键参与者,正为具身智能打造完备教育闭环,让模型在海量仿真与现实交互中持续进化。
隐性瓶颈:评测与仿真基础设施
谢晨认为,当今具身智能的底层逻辑已超越单一模型算法,涵盖数据、评测及反馈机制等能力。
这些核心要素构成全新能力体系——学习基础设施(learning infra)。模型较弱时,该系统处于隐性状态;模型变强后,它就成了制约行业发展的真正瓶颈。
系统中最关键的环节是评测。
谢晨明确指出:「具身智能当前最关键的问题是评测,尤其是规模化评测。」
原因很简单:测不出来的问题,模型永远学不会。
评测为何困难?自动驾驶评价近乎「免费」,因有「影子模式」可拿司机操作实时对比反馈,但机器人在现实世界缺乏大规模评价基础。没有规模化评测,开发者无法准确判断模型是否进步,无法系统性发现失败模式,自然无法形成有效反馈闭环。正如谢晨强调:「解决不了这个问题,就很难衡量具身智能的提升,这是核心。」
在仿真中建立类似自动驾驶的「影子模式」评价体系,是具身智能跨越预训练时代的唯一路径。
同时,数据结构也在深刻变化。具身智能发展路径正摆脱对单一硬件本体数量的依赖,走向新路线。
谢晨观察到:「最多的具身数据一定不是本体商提供的。」这意味着支撑通用具身智能的最大规模数据会走向本体无关。只有构建本体无关的数据闭环,才能打破硬件采集的物理限制,为通用大模型训练提供海量多样的燃料。
在此演进路线下,仿真的行业地位发生根本改变。过去仿真只是模型与算法训练的辅助手段,如今仿真已成为整个系统成立的前提条件。
谢晨对仿真的定义标准严格:「需在足够物理准确的环境中,可复现、可修正地产生行动并观测结果。」
对于机器人,仿真已从「可选项」变为「必备条件」。谢晨笃定表示:「我可以肯定地说,仿真对机器人是必备条件,没有仿真肯定做不成。」
他进一步指出,要做大规模、可重复的评测,同时在千百个不同场景中随时验证算法演进,「唯一方案只有通过仿真」。
缺乏高精度仿真环境,行业无法建立真正可规模化的评测与学习闭环。这促成关键产业认知转变:优秀模型已难成单一竞争壁垒,决定具身智能能力的核心要素,已转移到模型背后提供数据、仿真与评测支撑的「数据引擎」上。
真正稀缺的不是数据,而是「数据引擎」
在此理论框架下,行业下一阶段真正稀缺的能力已摆脱对数据量或数据供给本身的依赖。目前焦点在于:能否持续构造有效学习信号,能否系统性暴露失败模式,能否将现实问题转化为评测问题,进而形成持续迭代的反馈闭环。
正因如此,谢晨在访谈中对「data factory」和「data engine」的严格区分愈发重要。
前者带有流水线交付特征,后者是反馈驱动、评测驱动的学习引擎。
谢晨明确表示:「我更希望把它定位成data engine。」他解释:「data factory有点偏工厂,运作模式停留在流水线层面,缺少关键技术与系统化能力,也未构建反馈驱动的迭代机制。data engine则是反馈驱动的学习引擎。」行业下一阶段真正需要的是持续生产学习信号的系统,仅生产样本的工厂难以满足未来需求。
进一步说,终局的数据系统会高度类似教育系统。谢晨推断:「终局的数据公司可能跟教育公司长得很像。」他也指出量贩式的data factory会被淘汰:「data factory还是偏量贩式……我认为这个路径很快就不需要了。」真正的终极需求聚焦于能自我进化的数据引擎、仿真环境和评测系统。

在此意义上,光轮智能这类公司的生态位发生变化,超越传统数据供应商角色,演变为以数据、仿真与评测为核心,驱动模型持续学习的基础设施系统供应商。
谢晨定义自身企业时提到:「我们是一套以系统驱动、以系统和评测为中心的……通过帮助客户的模型发现问题,基于有效反馈和经验帮助他们提升能力的系统。」
从模型时代进入基础设施时代
GEN-1显然是新起点,它未解决所有难题,也未让具身智能一夜跨入大规模商业化阶段。
但它足以说明:具身智能正经历从「模型驱动」向「基础设施驱动」的深刻转型。此阶段决定智能上限的关键要素是让学习持续发生的系统,单个更强模型无法支撑行业未来发展。
谢晨曾把仿真比作「时间机器」,认为它只是加速器。但现在他认为,对于机器人而言,仿真是「先决条件」。这种认知转变,本质是整个行业从模型狂热转向基础设施深耕的缩影。谢晨强调:「我觉得仿真是解决具身数据问题的基石,是整个具身智能学习所需的前提条件。」
面向未来,他描绘了更具科幻感却理性的终局形态:「智能越强,对数据的饥渴程度反而成倍增加。最终,AI可能会像马斯克设想的那样,处在庞大仿真环境中,基于既定成功指标不断自我博弈、修炼内功。」这再次印证:Generalist的跃升只是结果,基础设施的厚度才是背后的真正原因。
本文来自微信公众号「机器之心」(ID:almosthuman2014),作者:关注数据的,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com